
Sometimes I put the URL of this blog into a search engine to see what people are saying. When I first started – having heard about the fabled Internet Hate Machine – I was a little worried that I’d have to deal with tons snarky remarks and negativity. The opposite has happened. I’ve received several touching personal “thank you” emails, and a large majority – maybe even 90% – of social media feedback has been positive and extremely polite. So, unexpectedly, it’s been a bit of an Internet Love Fest. It’s all a bit disconcerting: hey, I enjoy arguments as much as the next guy!
Of the non-positive 10% of remarks, 95% have been quite useful and constructive. They allowed me to look outside my own conceptual bubble and understand the parts of blog that people have found mysterious, unclear or even annoying. In particular, there is one recurring sentiment.
The guy has some interesting insights, but what’s that weird diagrammatic notation all about?
I realised that I spent a lot of time talking about “the rules of the game” for dealing with string diagrams, using them in proofs and explaining some technical facts about what they mean mathematically, but I never really explained the fundamental questions of why people should care about them. This made me re-evaluate the way I present this material: at the recent Midlands Graduate School I spent half of my four lectures explaining the story of string diagrams and why computer scientists (and engineers, physicists, mathematicians, economists, philosophers,…) ought to care about them.
I think that this is an important missing chapter of the story so far. It’s an interesting tale in itself, involving natural language, Universal Algebra, programming languages and higher category theory. I will make the case that string diagrams are not only important, they’re inevitable. And it’s due to something called resource-sensitivity.
What is resource-sensitivity?
It’s a cliché that the digital revolution has changed the way we understand the world. One, somewhat under appreciated aspect is the way that the concept of data has changed the way human beings perceive reality. Sequences of 0s and 1s encode all kinds of information and have spoiled us: millenia of experience of coping with finiteness (food, money, time, etc.) has been augmented with an immensely powerful resource that comes with an unprecedented ability to be copied and thrown away at will. Media companies have been struggling with this disturbing new reality since the days of Napster. Dealing with data is also a conceptual leap that programmers have to make when first learning to program; they learn to navigate this unfamiliar and exotic world, governed by a resource like few other in human experience.
Let’s start with a simple example of resource-insensitivity. The following is a very simple function, in C syntax, that takes an integer x, multiplies it by itself, and returns the result.
int square (int x) {
return x * x;
}
The same identifier x appears twice in the body of the function (and another time, at the start, where it’s declared as the parameter). That means that the resource that the function deals with, in this case an integer, is implicitly assumed to be copyable. This is fine: an integer is represented by a sequence of 0s and 1s in memory. It’s not a problem to use it several times, copy it somewhere else or even overwrite it.
But not every resource is as permissive as data. One of the first string diagrams on this blog was the recipe for Crema di Mascarpone. The wires were typed with ingredients and there were several generators; for example a crack-egg generator that took an egg and produced a white and a yolk.

Actually, it was subsequently criticised by a colleague on my Facebook for not being truly honest, because it implicitly threw away the shell. But here’s something less controversial: I think everyone would agree that doesn’t make sense to include an egg-copy generator.

So, while copying numbers is ok, copying eggs is not. It’s an amusing idea precisely because we are intuitively aware of the concept of resource-sensitivity. Actually, once you start thinking about it, there are examples everywhere. For example consider the following, grammatically correct sentence in a natural language:
Have your cake and eat it too.
This aphorism is used in situations where you can’t have something both ways. But the literal meaning is referring to a physical object: you can’t have a physical cake, eat it and still have it, since the action of eating it destroys it. So, perhaps, a hypothetical programming lanuage for cake handling should not allow you to write the following routine:
cake handle_cake (cake c) {
eat c;
return c;
}
Here executing the command eat c; consumes the resource c, so there is nothing to return. It seems that type cake is quite unlike the type int of integers. We will call the integer kind of data classical: classical data can be copied and discarded, whereas non-classical data (like eggs and cakes) cannot.
The closest thing to classical data that we had before computers is referencing things or concepts. In other words, information, which can be copied (e.g. by monks) and discarded (e.g. in a bonfire). Natural languages like English evolved to express information, and so they have several classical features built-in. In particular, the way that sentences of natural language are constructed are an example of something called classical syntax. Classical syntax is a good fit for dealing with classical data like information, but as we will see, also has some annoying limitations.
What is classical syntax?
Trees are a popular way of organising classical data, and are closely related to the notion of classical syntax.

Unlike traditional trees, like the Hawaiian one in the photo above, abstract trees are usually drawn with the root at the top. For example, the following is the tree representation of the expression 2 × 3 + 4.
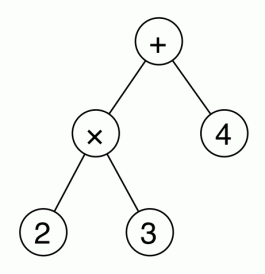
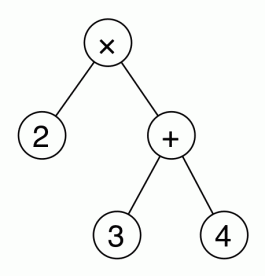
The usual convention that × is evaluated before + is captured by the fact that × appears deeper in the tree than +. So actually, trees are better than formulas because they eliminate the need for parentheses. For example, the tree for 2 × (3 + 4) is the following:
Expressions in natural language such as “you can’t have your cake and eat it too” can also be represented as trees. A lot of this is due to work by Noam Chomsky on the theory of context free grammars (CFGs), although some people date work on CFGs and their relationship with natural language back to ancient India. So “have your cake” looks something like this, as a syntax tree:
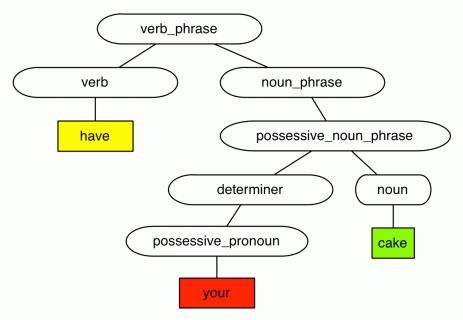
(Don’t trust me, I never actually studied English grammar. When I went to high school in Australia back in the 90s, teaching formal grammar was unfashionable and considered to “stifle creativity”. What a load of…)
Anyway, as you can see from the tree above, natural language grammars are complicated things. CFGs are also used to define the syntax of programming languages; fortunately, these are actually much simpler to describe than natural language grammars, which are full of exceptions and special cases. So here’s how the cake handling program from before might look like as a tree:
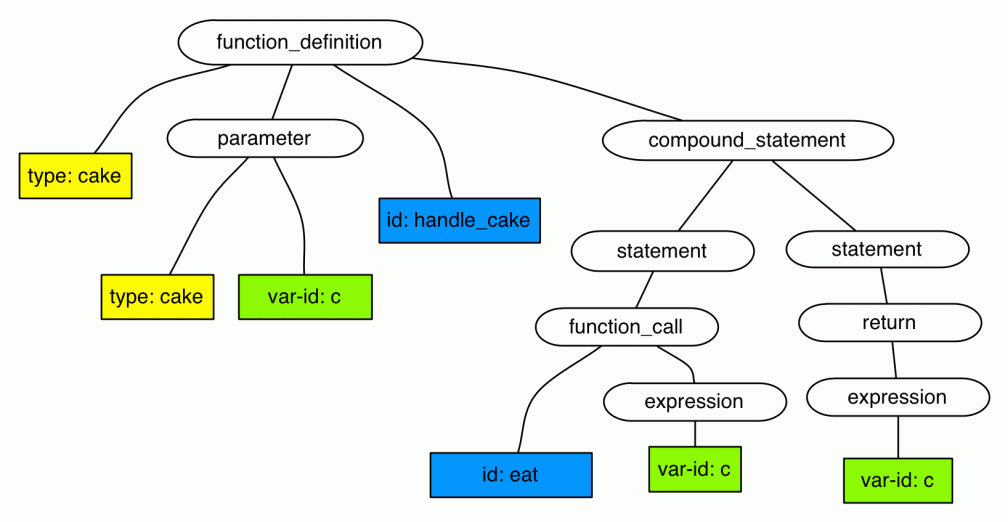
This is roughly the kind of tree that’s constructed by the compiler, or, more precisely, by one of its components, the parser. Here I’m being somewhat reductive: in the programming language context such trees have special features to deal with variables and identifiers, and these kinds of extended trees are referred to as abstract syntax.
The cake c is referred to twice in the body of the function and once in the declaration. But since cake is a non-classical, resource-sensitive type, then perhaps the compiler ought to ensure that the variable appears only once in the function body? So maybe our cake programming language should reject this program as a syntax error?
This doesn’t really work very well. For example, some actions might preserve the resource. For example, following ought to be ok: there’s no problem with looking at your cake and having it too.
cake handle_cake (cake c) {
look_at c;
return c;
}
One popular way to go about solving this problem is to build a little type theory for cakes and catch these kinds of bugs during type checking. Although this often works, is often very cute, and is quite similar to the kind of semantic analysis that goes on in our heads when trying to make sense of expressions in natural language, I think that it ignores a deeper issue: we are cramming non-classical data into classical syntax.
Other interesting repercussions that will become clear when we think about the mathematics that governs the behaviour of classical syntax. More about this next time. For now, I’ll highlight some things that I think are symptoms of the widespread disease of classical thinking about non-classical things.
Limitations of classical thinking
Apart from cakes, here are some other examples of non-classical data, in order of decreasing coolness: qubits, money and time. In fact, almost any finite resource you can think of is non-classical, and they all pose similar problems. All these examples are of things that, like eggs and unlike information, cannot be arbitrarily copied and discarded.
But even for ordinary, classical 0s and 1s kind of data, sometimes resource-sensitivity comes into play. A good example is concurrency: the idea that a computation can be split into a number of threads that are executed in parallel. The threads then maybe communicate and synchronise several times during processing in order to perform a task faster than would be possible when using a single thread.
Concurrent programming is the the task of writing programs that can do several things at the same time. It is more important and necessary then ever before, because hardware has been getting increasingly parallel in the last 15 years. Unfortunately, it is also widely feared and considered to be extremely hard to get right. Here, although the data is classical, the actual act of computation is resource-sensitive. Two or more threads accessing and modyifying the same piece of data can have weird consequences, because of the non-determinism: we can’t predict before hand which thread will get to the data first, and it quickly becomes infeasible to examine all the possibilities. Getting this wrong can sometimes have deadly consequences. I’ll return to the topic of concurrency later because it’s one of my favourite things to talk about. For now, I will tell you my own personal hypothesis: one of the main reasons why programming language technology has problems with concurrency is that ordinary, classical syntax has problems dealing with resource-sensitive applications such as concurrency. I think that string diagrams can help. (Incidentally, I recently watched Bartosz Milewski’s introduction to category theory lectures: it was extremely cool to see someone introducing category theory and talking about programming in general, and concurrency in particular! I highly recommend the videos.)
Finally, one of the main points of this blog is that resource-sensitive thinking can actually help in areas that have traditionally been understood in a resource-insensitive way. For example, doing linear algebra with string diagrams reveals all kinds of beautiful symmetries that are hidden or only half visible when expressed in traditional, classical language. This is because the copying and discarding is explicitly a part of the graphical lexicon – it is the black structure of interacting Hopf monoids. Here, although the data is classical, it is nevertheless useful to be explicit about when the copying and discarding is done: only then the full picture becomes visible.
This episode has turned into one long piece of motivational text, with not too much technical content. This will change, because there is quite a bit of nice mathematics involved. So, my plans in the next few episodes are to answer the following questions in more detail:
- what are the mathematical properties of classical syntax?
- how can classical syntax be made (more) resource-sensitive?
- what is true resource-sensitive syntax? (spoiler: it’s string diagrams, just like the ones all over this blog!)
- how to convert classical syntax to resource-sensitive syntax?
- what are some examples of classical syntax, viewed through resource-sensitive glasses?
- what is the history of string diagrams?
- what are some future research and technological challenges to be solved?
The moral of the story will be that string diagrams are not just some weird, trendy notation. They are inevitable, once we accept that the world is full of non-classical things that need to be described properly. String diagrams are resource-sensitive syntax.

Pawel, Your thoughts on using Jamie Vicary’s Globular?
It seems to me that if it allowed more extensive text in the nodes
that it would be quite suitable for your diagrams.
And the layering is extremely useful for showing the development of diagrams.
Your thoughts?
LikeLike
I’m a big fan of Globular, and I know that it’s been used to do several very impressive things, e.g. sphere eversion by rewriting.
On the other hand, it’s not exactly what I’m looking for in a tool. My string diagrams are arrows of symmetric monoidal categories, so I would like the tool to be able to, e.g., find matches *modulo the laws of symmetric monoidal categories*.
Globular was designed to deal with weak higher categories, so many of the rules of the game that I always assume would need to be done manually in Globular – things like functoriality of ⊕, naturality of symmetry, etc.
I’ve been thinking about this problem for a while with a bunch of people: Filippo Bonchi, Fabio Gadducci, Aleks Kissinger and Fabio Zanasi. We have a paper called “Rewriting modulo symmetric monoidal structure” and a followup “Confluence of graph rewriting with interfaces” — it turns out that there is a very close connection with between rewriting string diagrams for symmetric monoidal categories and a form of graph rewriting called double pushout rewriting. So we now understand how to implement this stuff — we “just” need to find some time/people/money to do it! 🙂
LikeLike
Thanks very much for the ref to “Rewriting modulo symmetric monoidal structure” –
really an excellent and interesting paper with a great bibliography!
And for your comments in your reply. Very interesting.
On the content of the above post ““Why string diagrams?”,
you are less than happy about the usefulness of “classical things” in reasoning about concurrent programs.
Do temporal and modal logic (popular in New Zealand!) address any of your concerns?
In any case, thanks for making your interesting and useful work available!
Glad you can find the time to write and publish it.
LikeLike
Do you mean things like separation logic, or Lamport’s TLA? I think both have their uses, but my critique is somehow more fundamental: the way that concurrent programs are written nowadays are very fragile, difficult to understand, and require sophisticated verification techniques (like separation logic) that do not always scale well. I will definitely write more about this in the future!
LikeLike
Where are the followups for this post? I can’t seem to easily find what to read next from the index.
LikeLiked by 1 person
Hi Pawel,
first of all a ton of thanks for this great blog! It was an extremely interesting read right from Episode 1.
With regard to resource awareness being made explicit in the diagrammatic notation: Is your introduction of the new generator for polynomial variables in one of the last episodes not a classic syntax feature rather than resource aware non-classical? I was a bit astonished about it as I hoped you would introduce such entities by connections in a new 3rd dimension, 3rd in contrast to the 2d diagrams seen so far.
Or do you think this would not work in principle?
LikeLike