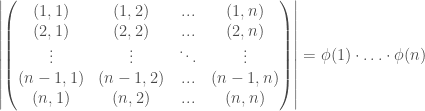Jason earned his Ph.D. in mathematics from the University of California, Riverside, working on string diagrams very similar to the ones found in this blog. Because of a temporal coincidence in connection with these diagrams, he was mentioned back in Episode 10.
His diagrams are obviously superior, being written vertically instead of horizontally. He is currently teaching maths and physics at Victor Valley College and putting together applications for postdoc and tenure-track positions at universities. There is hardly a scrap of paper in Jason’s office that he hasn’t doodled some of these kinds of diagrams on.
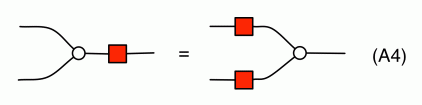
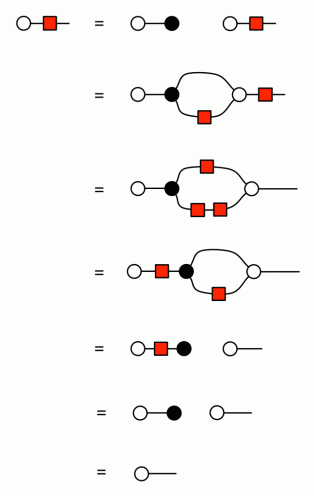
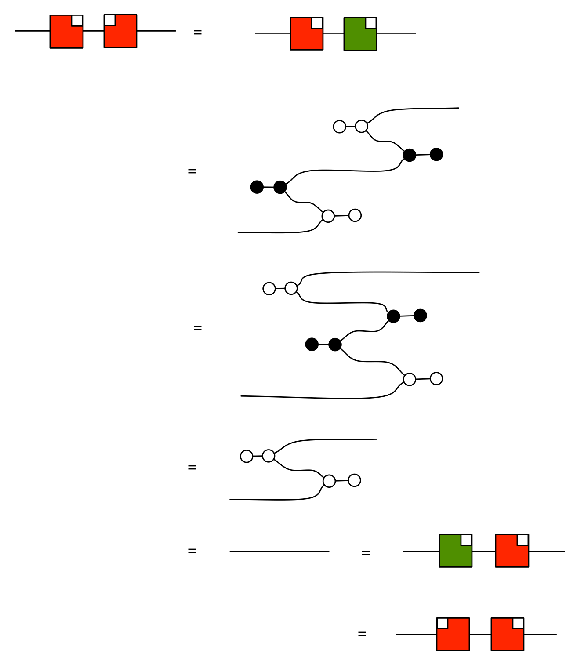
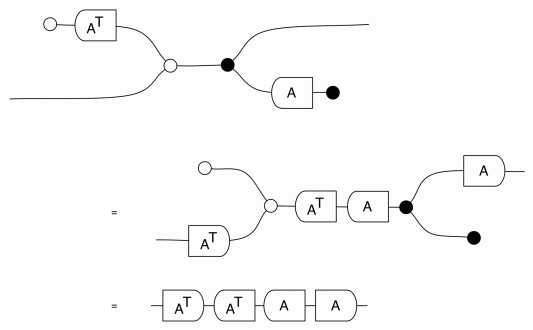
In Episode 24, Pawel mentioned there is a bit of redundancy in the graphical presentation of interacting Hopf algebras. In this short series of episodes I will show how you can derive some of the redundant equations, and in pruning the redundancy there will be a bit of a twist. The equational system interacting Hopf algebras, or interacting Hopf monoids, as displayed in Episode 24, is repeated below in its full glory.

Discounting the Scalars equations, of which there are infinitely many, this equational system features a total of 38 equations. As we can see, though, we only need two representative Scalars equations, so if we count by equation representatives, we have a total of 40 equations in the system. Shaving off redundant equations with Occam’s razor, we can cut this total in half.
Antipode and Antipodeop
Let’s start by looking at the five equations in the Antipode box, beginning with how the antipode interacts with adding. This equation
says -a + -b = -(a + b), and it can be proved as follows:
A bizarro argument similarly proves
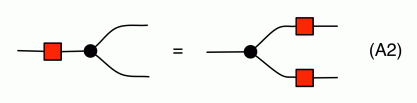
The interaction between antipode and zero

states that -0 is the same as 0. If you throw a (black) bone to the left side, it’s not hard to see how to prove this using the Hopf law.
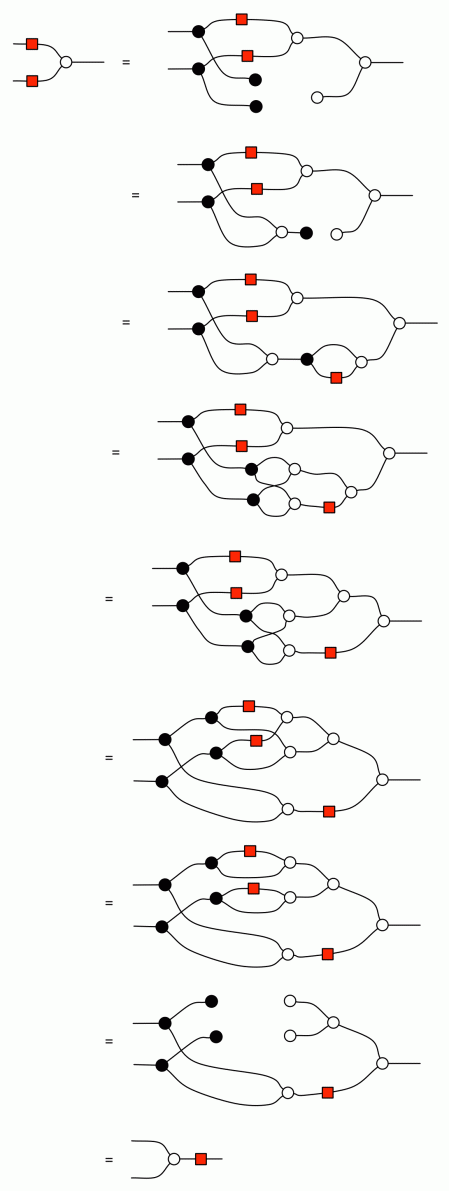
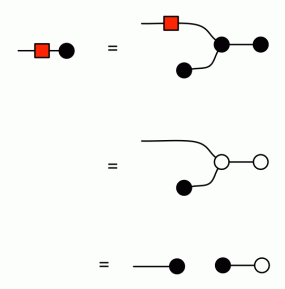
A bizarro argu… oh. Wait a minute. We need to be a little bit cautious here. When whittling down the equational system to remove redundancy, careful attention must be paid as to which equations are used to prove various theorems. We used the fact that double negation cancels to show -0 = 0, and since antipode is self-bizarro, that fact would be used in the purported bizarro proof. But our proof that double negation cancels used the statement

So we can’t use the fact that double negation cancels to prove this statement.
Fortunately there is another way:
In that second-last step, we’re using one of the equations from the Division by Zero episode (Episode 26), namely:
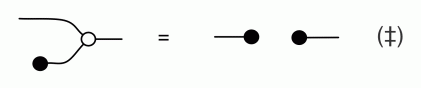
The proof of (‡) depended on (A3), though, so it seems we are caught in a circular argument again. Something has to give, so let’s keep things black and white and take (‡) to be part of the reduced equational system, along with its bizarro equation, (†).
Running all these arguments in a mirror, we can show the corresponding Antipodeop equations are also redundant. So, while we didn’t quite manage to get rid of (A3) for free, we have cut down the set of the antipode equations to just:

That’s eight redundant equations thrown out already!
Zebra snakes
The way the antipode interacts with the cups and caps, which we used in the last derivation, hints toward something even bigger that we can tackle. In Episode 23, the cups and caps equations


give us the way to turn half-snakes of one colour into half-snakes of the other colour, so long as an antipode is included on one of the half-snakes. Together with the snake lemma (also in Episode 23) we get an alternate presentation of the antipode.
If you start with the cups and caps equations as given, it’s easy to show
If you take a snake where the left and right halves are opposite colours, one of the halves can be made to have the same colour as the other by introducing the antipode. But now the snake lemma can be used to straighten the snake out, leaving behind only the antipode! That means when adding, copying, and their mirror opposites all meet, the antipode can be taken as a syntactic sugar (i.e. redundant as a generator).
So let’s ignore the cups and caps equations for the moment and define the antipode as a sugar.
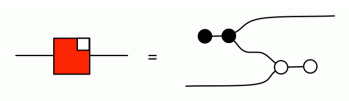
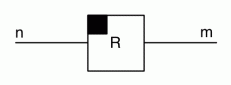
Don’t worry. These zebra snakes are not as dangerous as the biological version of zebra snake. When the adder half of the snake is on the lower right, we will take that to be the official designation for the antipode. The other three zebra snakes can be formed using our conventions for bizarro and opposite. The little white box in the top right corner breaks the symmetry, for now, so that we can distinguish it and its mirror image opposite.
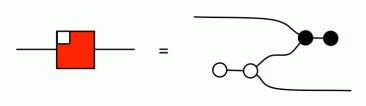
Let’s use green for the colour inverse, giving us the the following two variants.
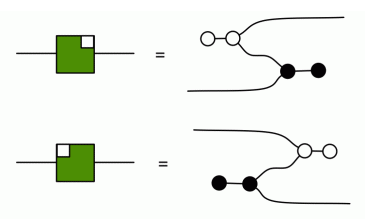
I would apologise to the red-green colourblind readers for this convention, but you actually get a sneak peek at the truth here: red=green. One of the stipulations made when antipode was introduced was that antipode should be self-bizarro – that’s why it was red and square, after all, since bizarro is only supposed to affect black and white. Is this stipulation still true when antipode is simply defined as a zebra snake? Yes!
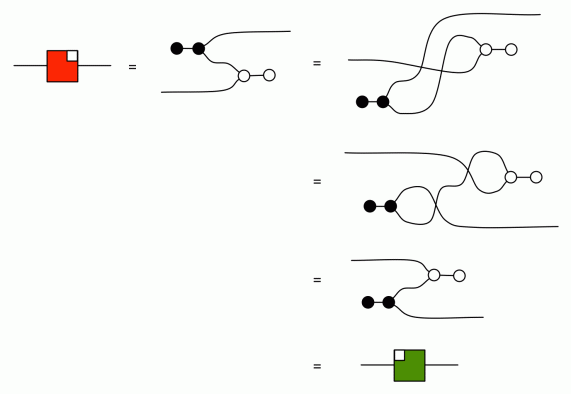
In the derivation above, first we pull the black half-snake down and left, then pull the white part up and right. Finally, we use the (co)commutativity of the copying and adding.
Mirroring this argument tells us antipodeop is also self-bizarro.
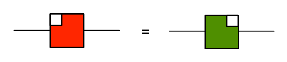
With the zebra snake definition of antipode, the black and white snake lemmas show that the mirror image of the antipode is its inverse:
Recall that the Hopf equation, the main equation involving antipode and the one that says “1+-1=0” is the following
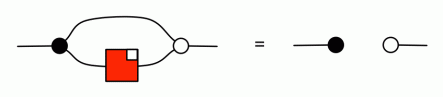
and (together with a couple of now-redundant equations) it implies that -1.-1 = 1, i.e.
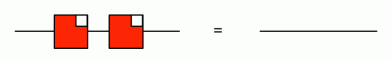
So assuming the Hopf equation, and then using the fact that inverses are unique we have

So all the zebra snakes are equal!
Let’s go back to the Cups and Caps equations. Both are now provable, since:
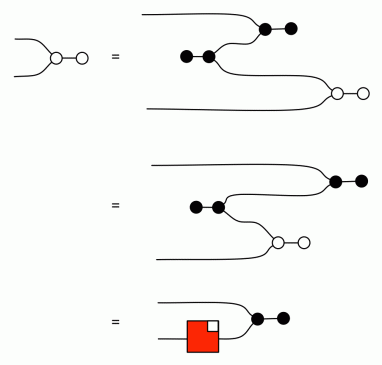
But at this point, we can stop distinguishing between them and return to using just a symmetric, red box and use any of the four definitions in proofs.
So the only equations we need for the antipode—besides its definition as a sugar—are the Hopf equation and its mirror image!

Hold on… did we just prove the Hopf equation? That means the antipode and all the equations involving it is completely redundant! What a twist!
So what have we gained here? We dropped 12 equations and a generator as redundant, and we added a syntactic sugar and four equations. The original big box of equations can be reduced to the following, smaller set:

And this isn’t even IH‘s final form.
I would be remiss not to point out that just because we can treat certain diagrams as syntactic sugars instead of as generators doesn’t mean it is most expedient to do so. We should like to have the antipode even if we do not have access to the opposites of adding and copying, for instance, because (bicommutative) Hopf algebras are important enough to be considered separately from relations. Likewise, we should like to have the twist, independently of the antipode, to describe (bicommutative) bialgebras. After all, the antipode is not accessible when we are drawing diagrams of matrices of natural numbers, as in Episode 11.
While we have made some headway, there are still a handful of equations that I need to get rid of to fulfill my promise of reducing the interacting Hopf algebras equational system from the Big Box of 40 equations to only half as many. In the next part of this miniseries, I will continue chipping away at the redundant equations. There is a saying that less is more, but sometimes the converse is the appropriate aphorism: more is less. There are four very simple equations that are missing from the Big Box, which have already been included in the reduced Big Box above. With their help, we can prove equations that are completely in the mirror universe. And some of those four additional equations end up being redundant, too.












































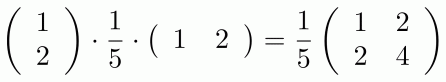

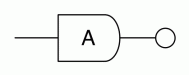
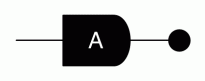







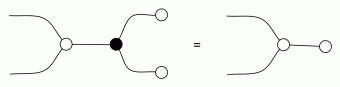




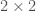 matrix
matrix 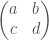 :
:
 and
and  to the output nodes
to the output nodes 
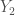 . Moreover, we want to do this in such a way that every output node receives some flow without any congestion in the network. More specifically, want to push flow from the input nodes to the output nodes in such a way that:
. Moreover, we want to do this in such a way that every output node receives some flow without any congestion in the network. More specifically, want to push flow from the input nodes to the output nodes in such a way that: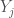 , there is a path from some input
, there is a path from some input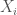 to
to  units of flow from
units of flow from 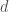 units of flow from
units of flow from 
 units of flow from
units of flow from  units of flow from
units of flow from 


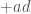 . The unsigned weight of this flow is
. The unsigned weight of this flow is 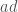 since we push
since we push 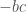 .
. . Coincidence?
. Coincidence? a matrix whose determinant is exactly equal to the
a matrix whose determinant is exactly equal to the and
and  we call any bijection
we call any bijection 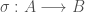 a permutation from
a permutation from  to
to  . Now assume that
. Now assume that  sends
sends  to
to 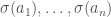 respectively. For example, let
respectively. For example, let 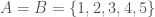 , and let
, and let  to
to  respectively. Write
respectively. Write  below
below 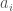 for each
for each  , and count the number
, and count the number  of crossings in between the
of crossings in between the  s and the
s and the  s. Define the sign of
s. Define the sign of  . For the permutation
. For the permutation  .
.
 of inversions of
of inversions of  such that
such that 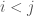 but
but  . In the example above, the number of inversions of
. In the example above, the number of inversions of  , which gives the same result as before.
, which gives the same result as before. and output nodes
and output nodes 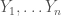 .
.
 , there is a path from some input
, there is a path from some input -tuple
-tuple  of paths , where
of paths , where 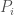 is a path from the input node
is a path from the input node  for some permutation
for some permutation  be this permutation.
be this permutation. between any two vertices in
between any two vertices in  be the product of the weights of the edges of the path. For any two vertices
be the product of the weights of the edges of the path. For any two vertices  for the sum
for the sum



 .
.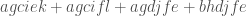 , and it is easy to check that each of these terms indeed gives a viable flow from the
, and it is easy to check that each of these terms indeed gives a viable flow from the 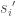 s to the
s to the  s. Note also that the sign of each term is +1 since
s. Note also that the sign of each term is +1 since  is sent to
is sent to 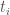 in each of the viable flows.
in each of the viable flows. , we may compute the determinant of
, we may compute the determinant of  and output vertices
and output vertices 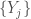 in
in  . Then, we (easily!) compute the sum of the signed weights of viable flows in
. Then, we (easily!) compute the sum of the signed weights of viable flows in 
 denotes the greatest common divisor of
denotes the greatest common divisor of  and
and 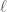 .
. denote the number of positive integers less than or equal to
denote the number of positive integers less than or equal to 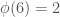 since the only numbers less than 6 that are relatively prime to 6 are 1 and 5. On the other hand
since the only numbers less than 6 that are relatively prime to 6 are 1 and 5. On the other hand  since all the positive integers less than 7 are relatively prime to 1. In fact, it is easy to see that
since all the positive integers less than 7 are relatively prime to 1. In fact, it is easy to see that  for any prime
for any prime  .
.
 .
.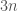 vertices:
vertices:  are the input vertices,
are the input vertices,  are the output vertices and
are the output vertices and 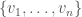 are intermediate vertices. If
are intermediate vertices. If  with weight
with weight 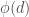 and the edge
and the edge 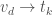 with weight 1.
with weight 1.
 of all the paths from
of all the paths from  to
to  ? Well each path from
? Well each path from  of weight
of weight  of weight 1, for some
of weight 1, for some 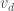 , where
, where 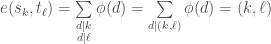
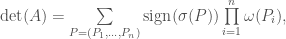
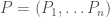 ranges over all viable flows from the input vertices
ranges over all viable flows from the input vertices  to the output vertices
to the output vertices  .
.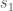 to
to  is
is 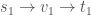 since 1 has only one divisor, namely 1. As a result, for each prime
since 1 has only one divisor, namely 1. As a result, for each prime 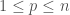 , any path from
, any path from 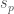 to
to  . This is because
. This is because  of two primes, any path from
of two primes, any path from  to
to  . Repeating this argument for all the other numbers less than or equal to
. Repeating this argument for all the other numbers less than or equal to  to
to 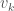 .
. , then there must be some
, then there must be some  such that
such that  is linked to
is linked to  with
with  (why?). But this means that
(why?). But this means that 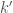 divides
divides 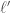 , a contradiction since
, a contradiction since  ! So we must have
! So we must have  , for all
, for all  via
via  , since the weight of each path
, since the weight of each path  in this flow is
in this flow is