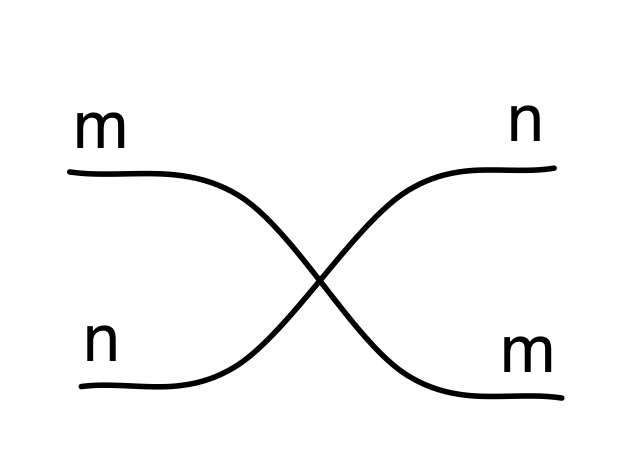
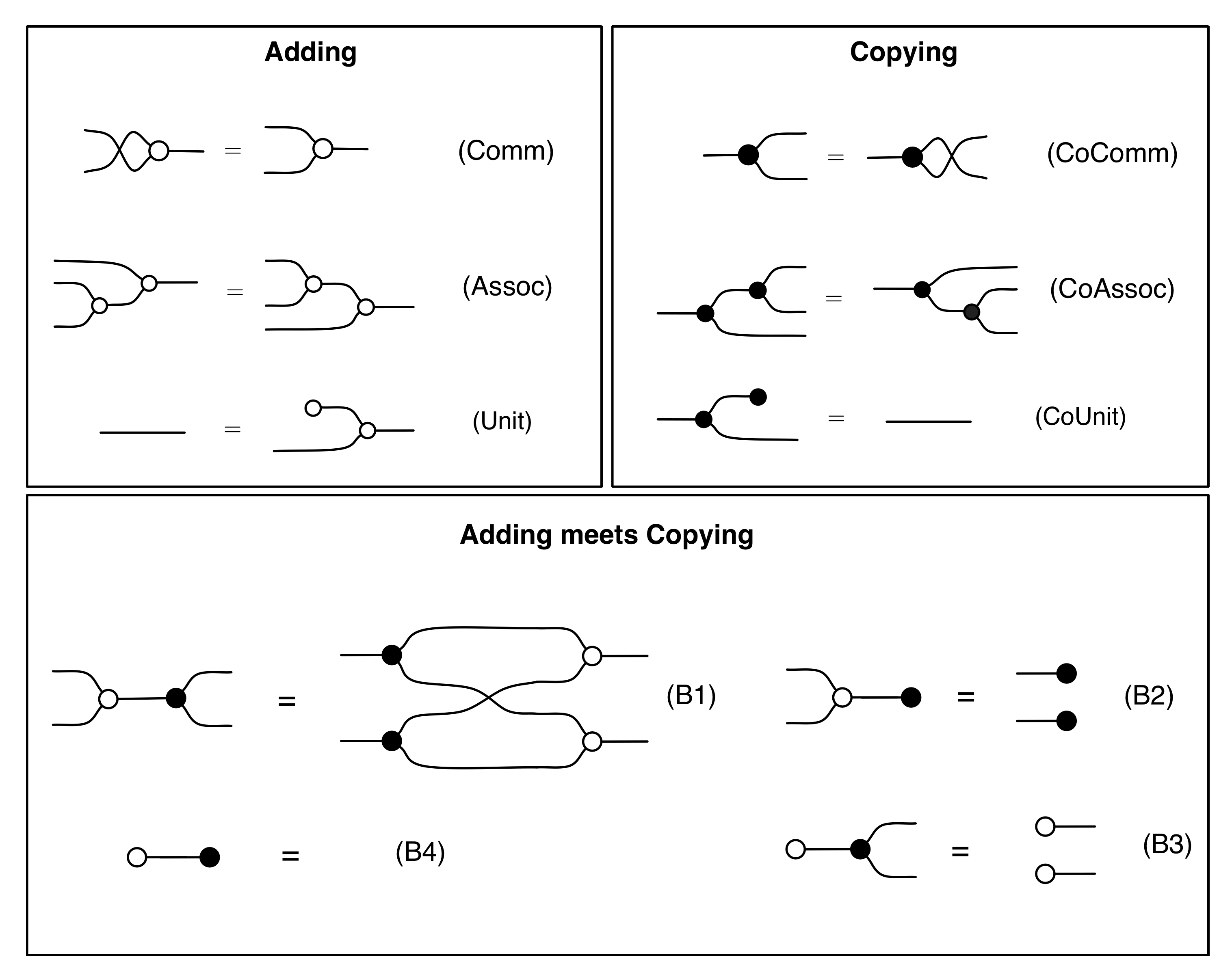
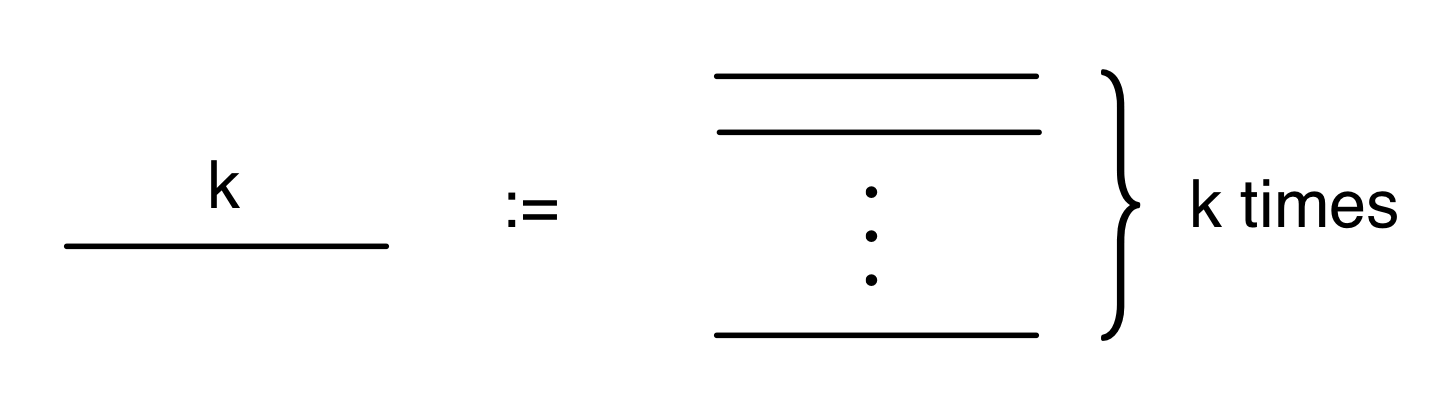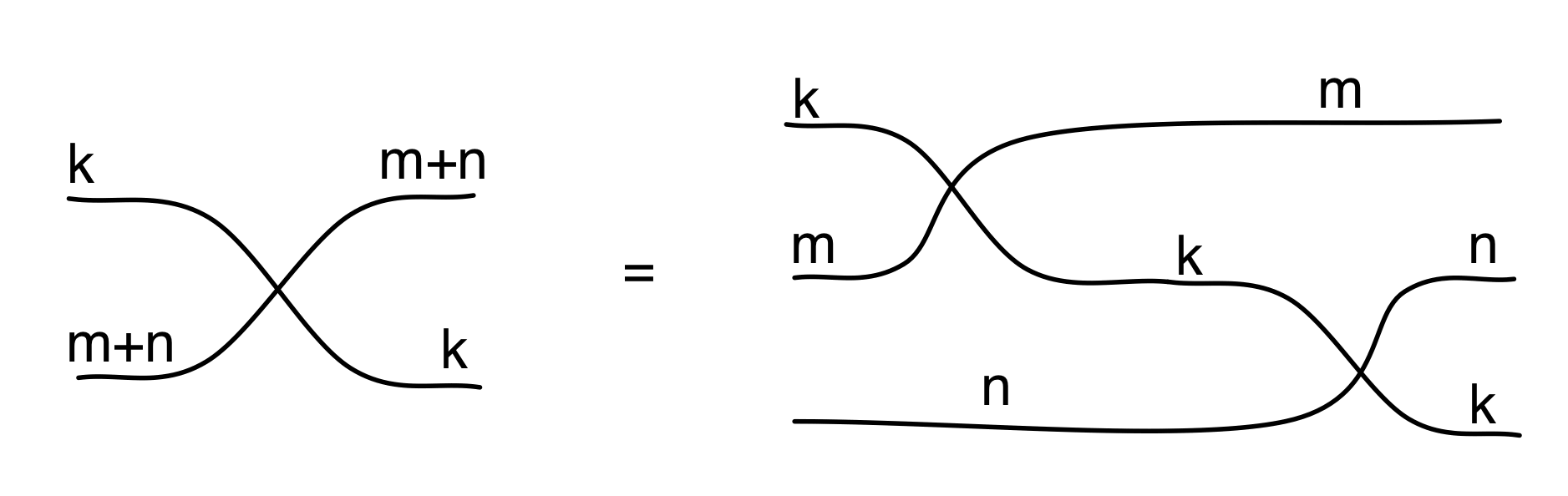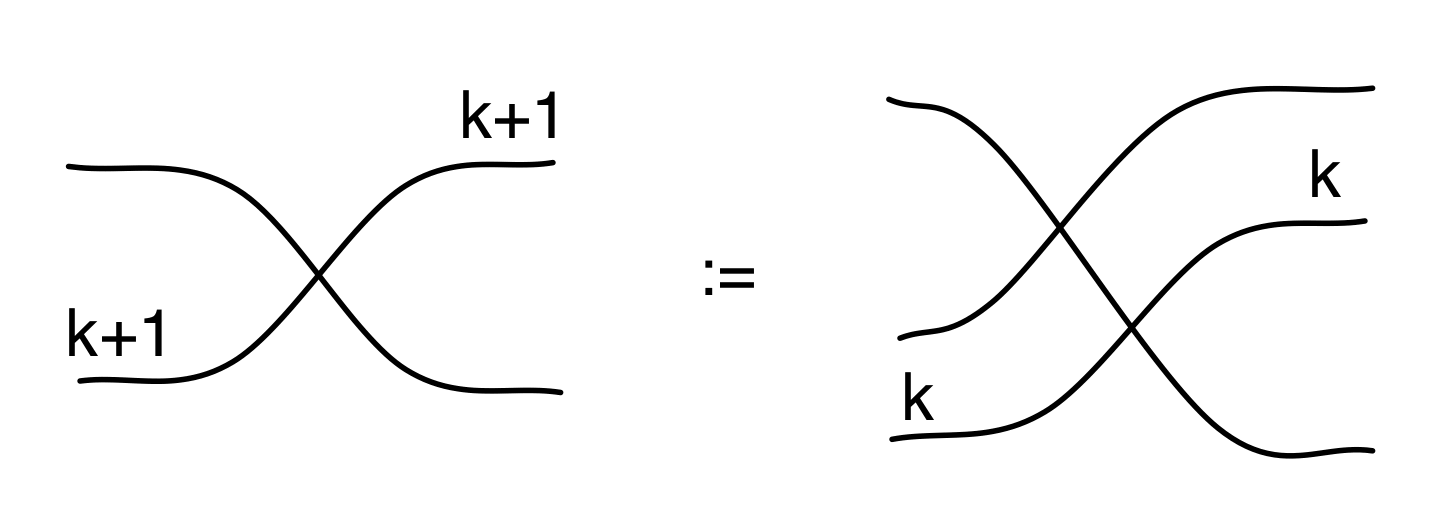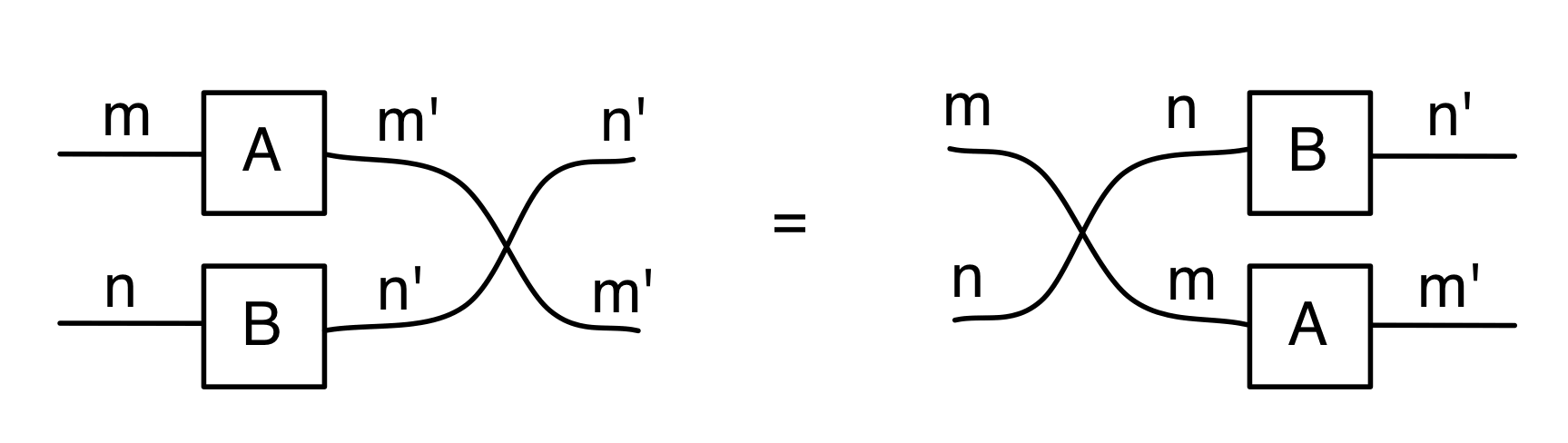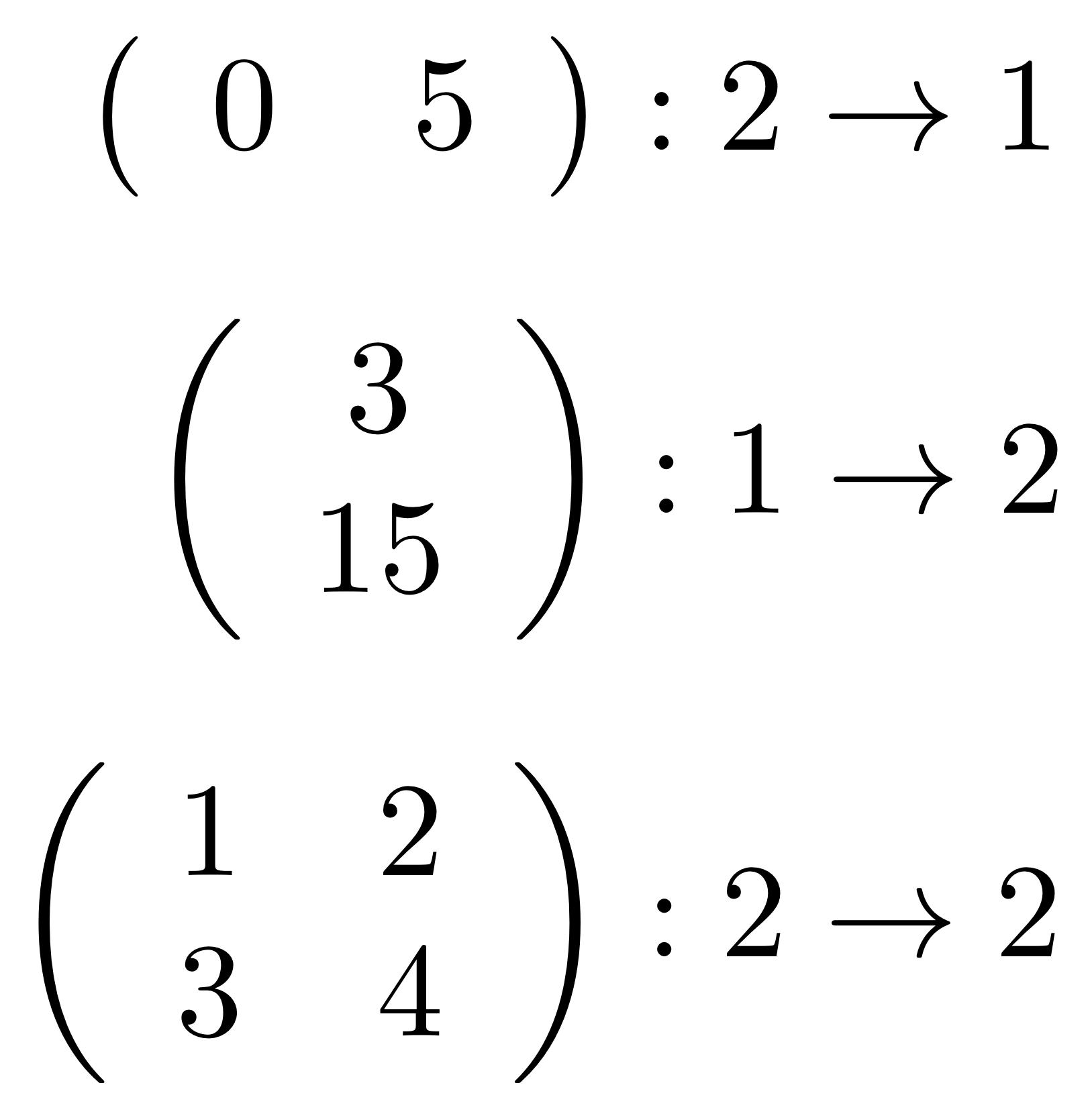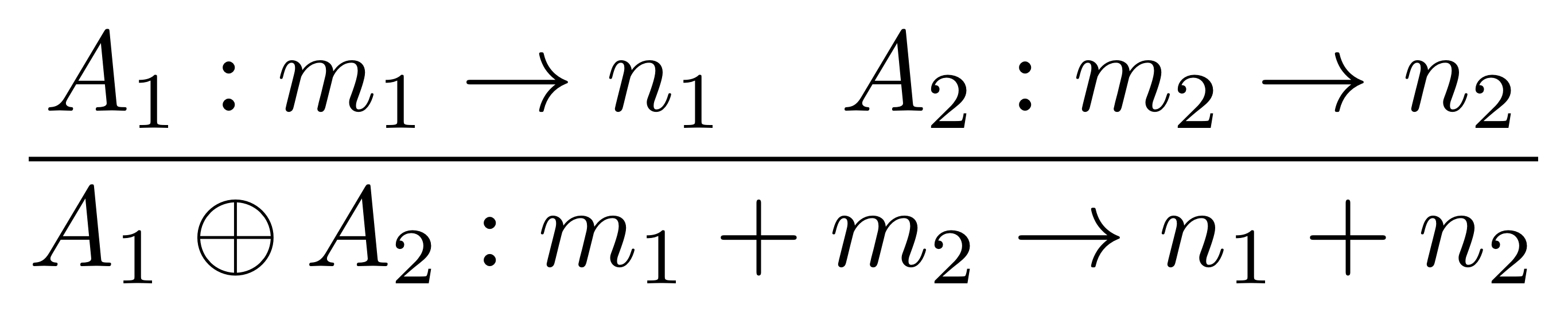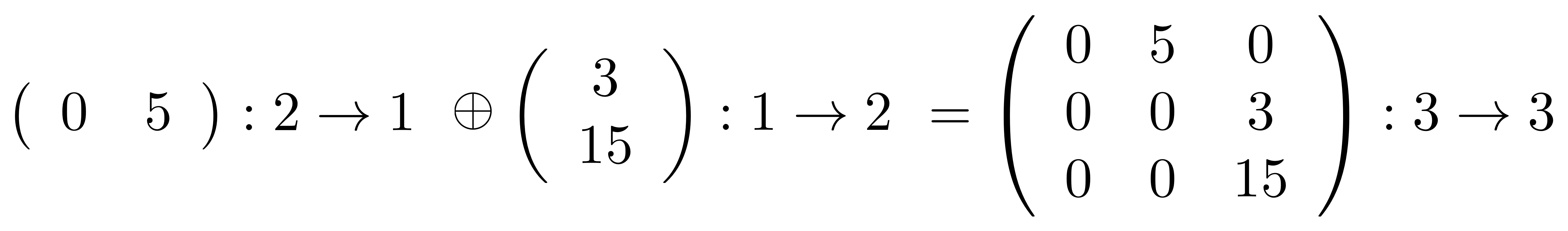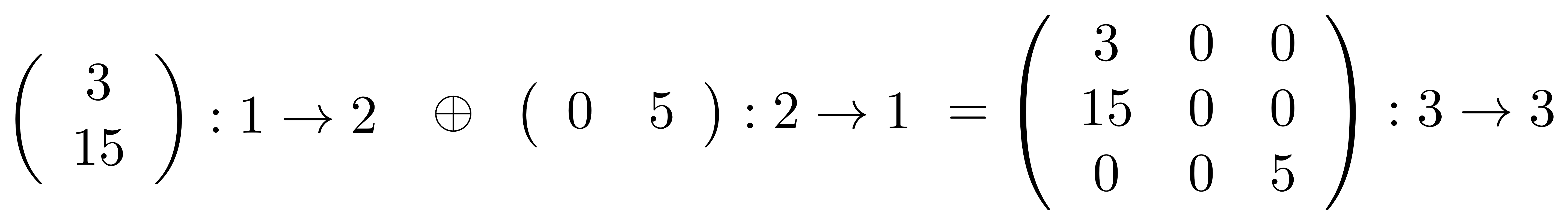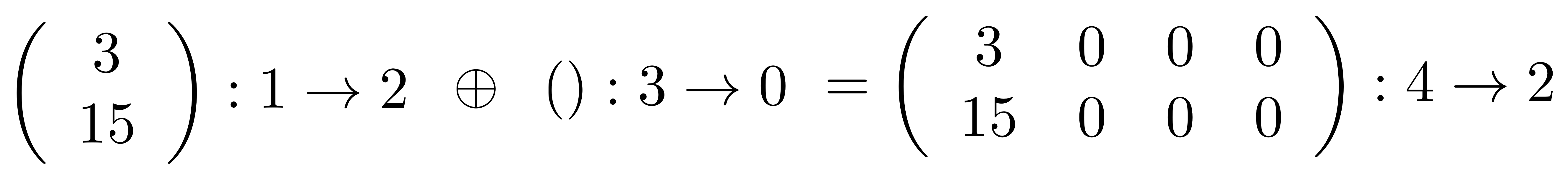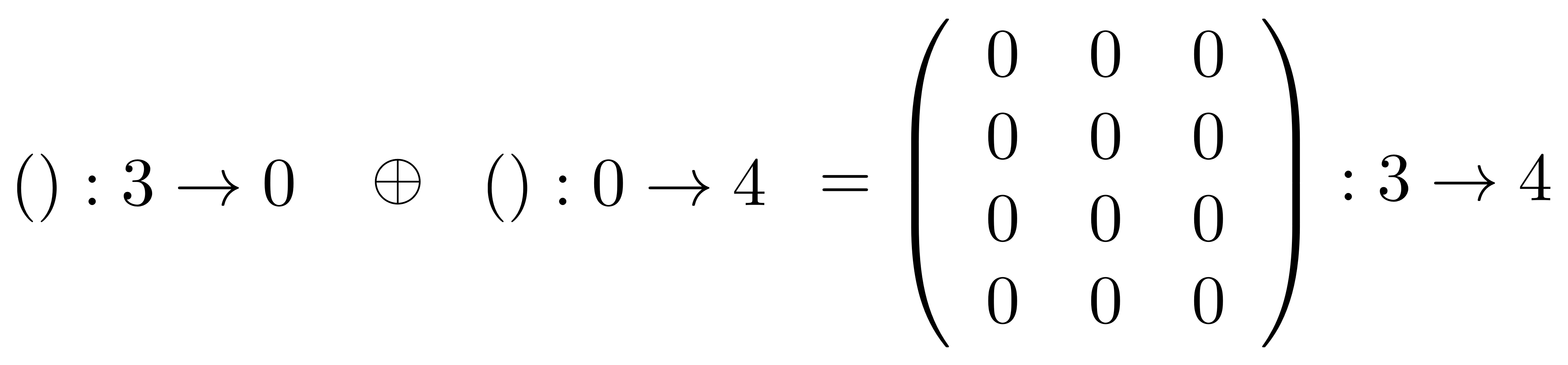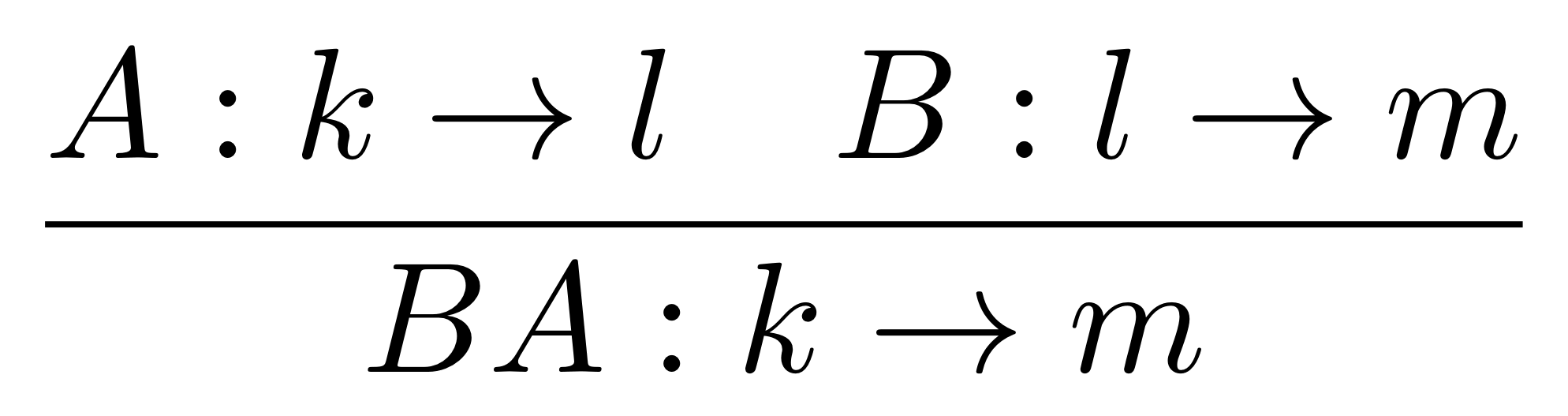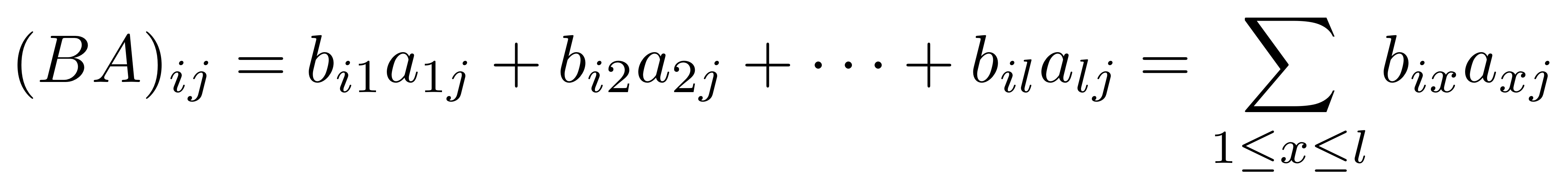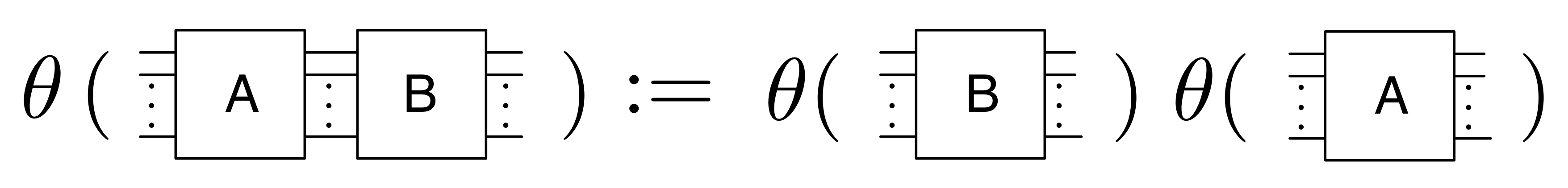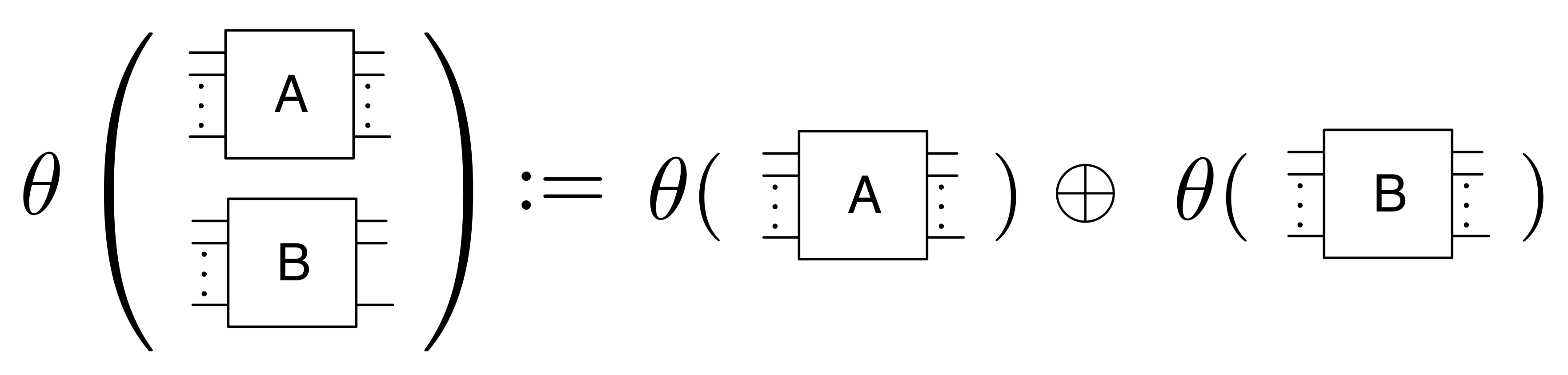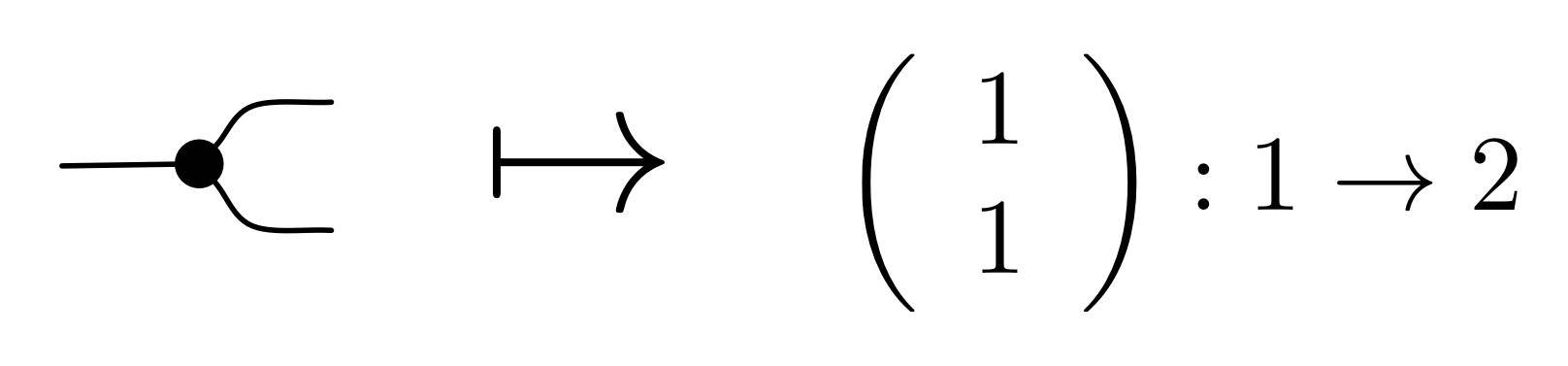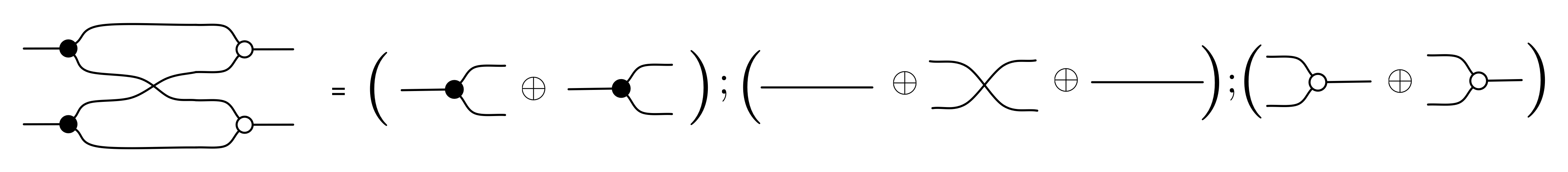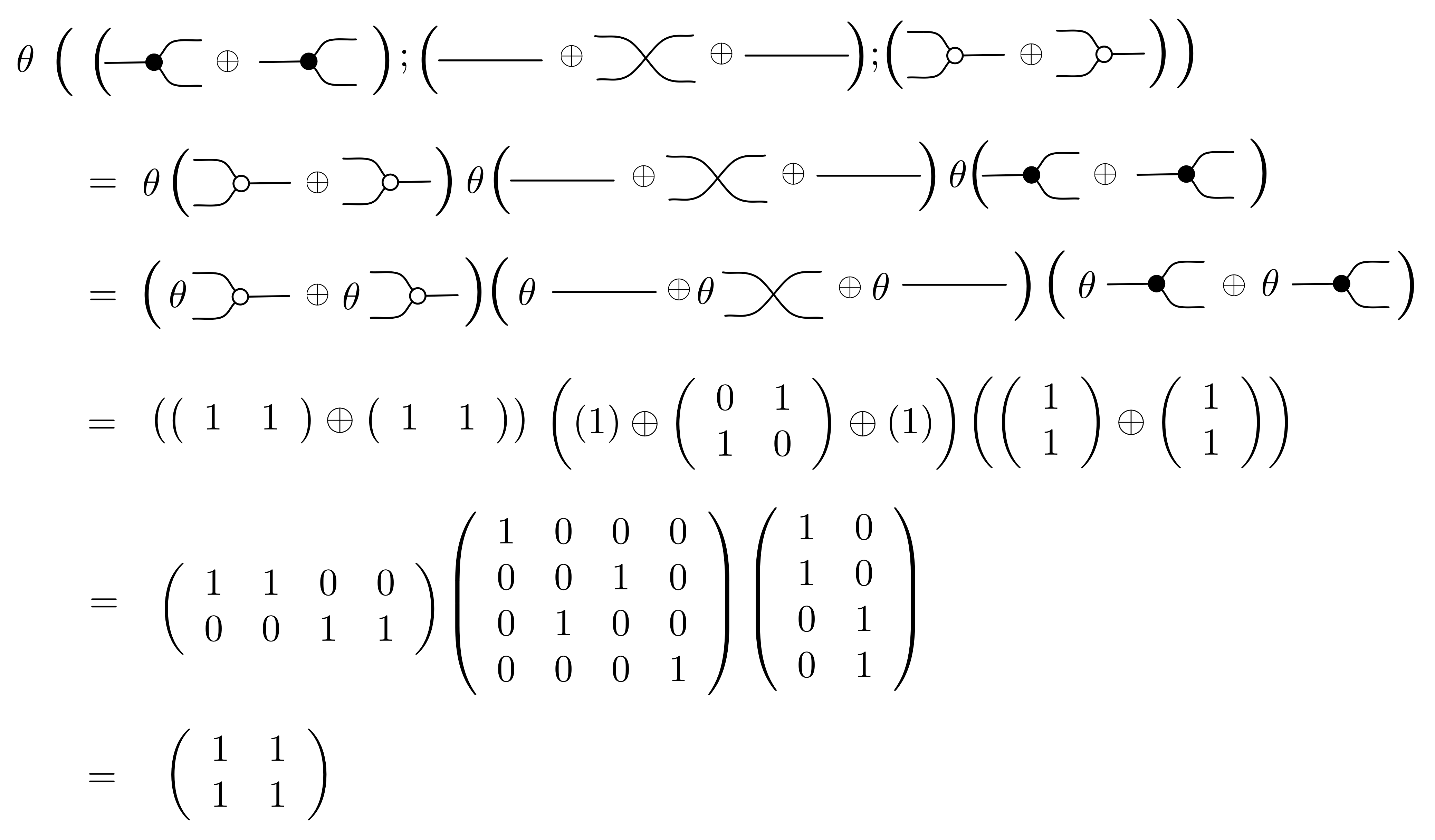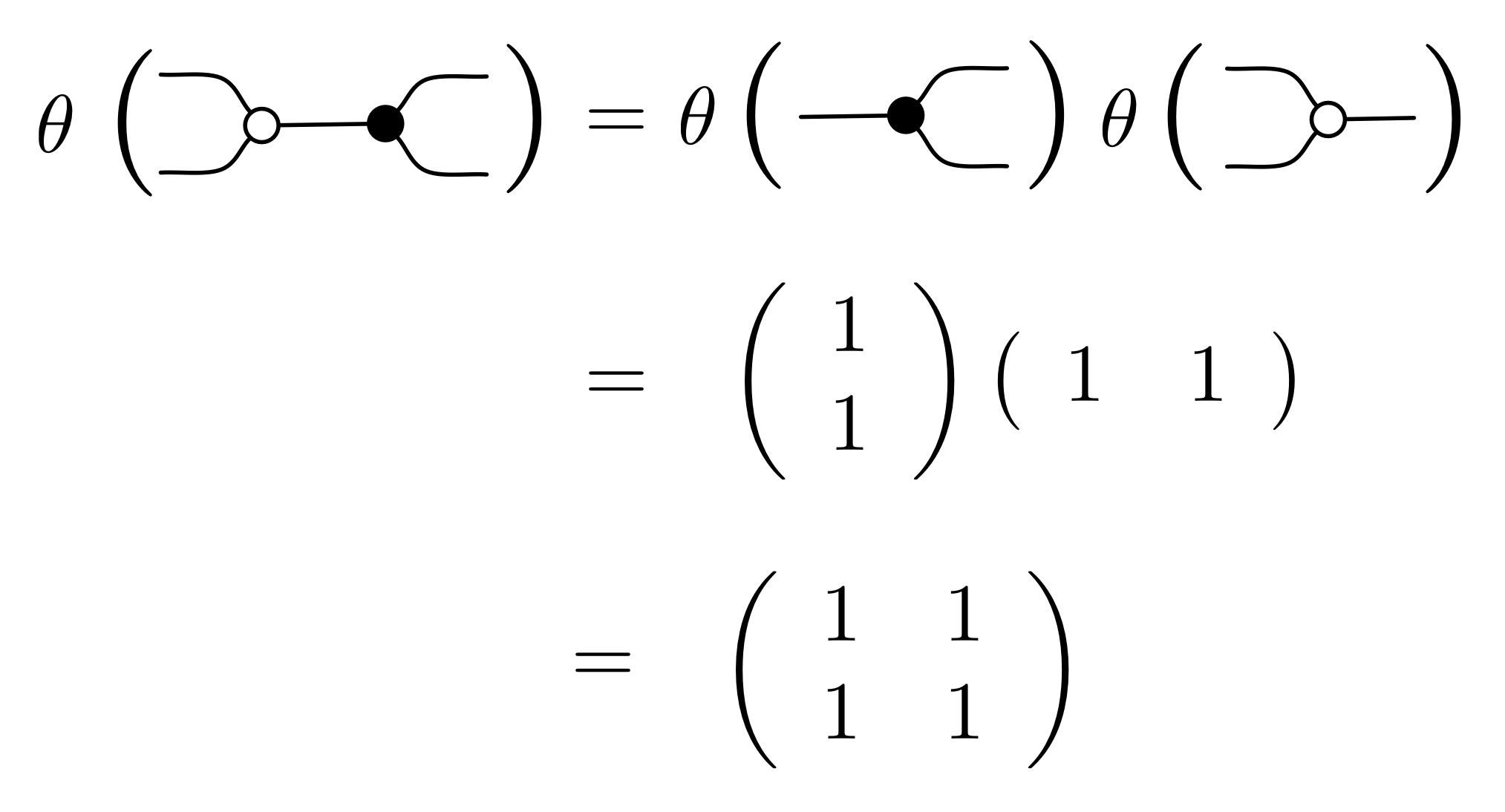In the last two episodes we have established that our diagrams, constructed from the four generators, and subject to the equations below, are the arrows of a PROP B.
We have also talked about another PROP, Mat, that has as its arrows matrices of natural numbers.
In maths, it is often the case that to understand something properly you need to think about how it relates to other things. Our current task is an example of this, since we need to establish exactly what we mean when we say that diagrams and matrices “are the same thing”. This brings us to the notion of homomorphism —a generic jargon word that means “structure-preserving translation”—of PROPs.
So suppose that X and Y are PROPs. It’s useful to colour them so that we can keep track of what’s going on in which world, the red world of X and the hot pink world of Y. A homomorphism F from X to Y (written F : X → Y) is a function (a translation) that
for any arrow A : m → n in X produces an arrow FA : m → n in Y.
Notice that the domain and the codomain must be preserved by the translation: both A in X and FA in Y have domain m and codomain n.
But PROPs come with a lot of structure, and homomorphisms have to preserve all of it. For example, for any other arrow A’ in X, it must be the case that
F(A ⊕ A’) = FA ⊕ FA’ ①
The above equation says that if I translate the monoidal product of A and A’ taken in X then I get the same thing as if I had translated A and A’ separately and took the monoidal product in Y. Remember that monoidal product is defined differently in different PROPs: for example in B it is the stacking diagrams on top of each other, while in Mat it is forming a certain matrix.
Similarly, if we can compose A with A’ (which we can do exactly when the domain of A’ is n) then:
F(A ; A’) = FA ; FA’ ②
Again this says that translating A composed with A’ in X should be the same thing as translating the individual components separately and doing the composition in Y. Recall that in B composition is simply connecting dangling wires together, while in Mat it is matrix multiplication.
Moreover, as we have seen, every PROP has special identity arrows, one for each natural number m. These form a part of the structure of PROPs and so must also be preserved:
Fidm = idm ③
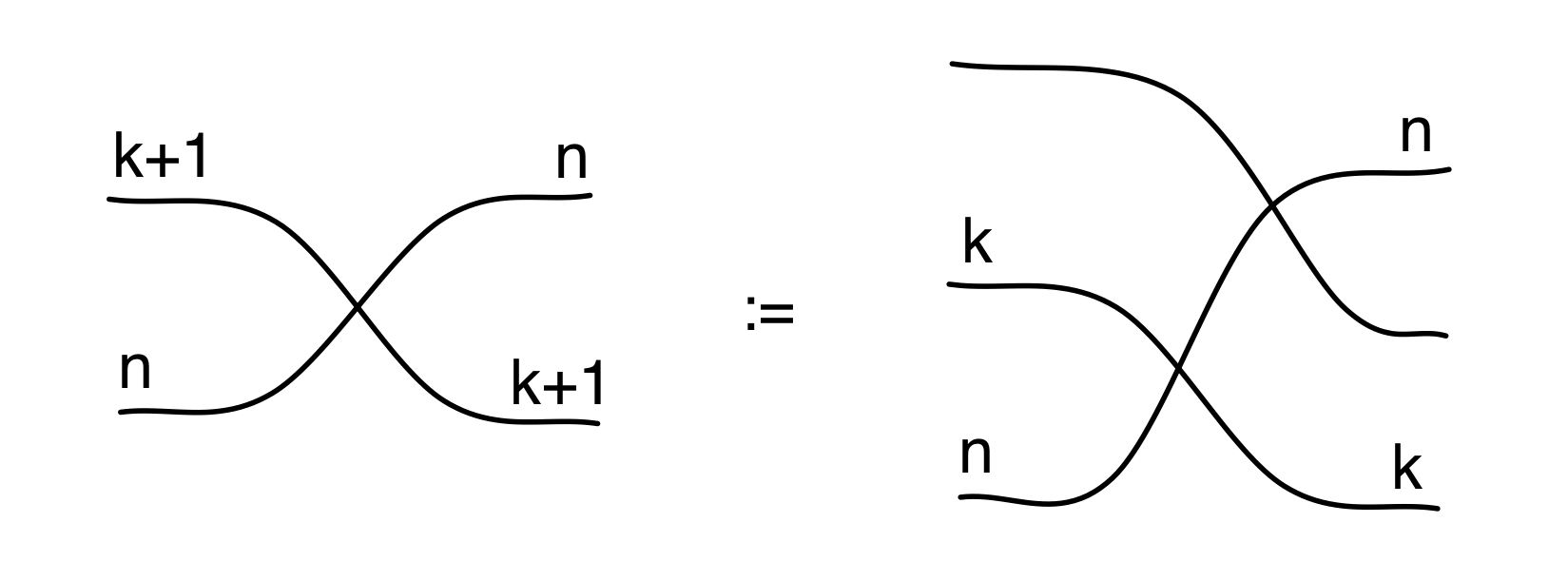
Finally, for any natural numbers m, n, there are the special “wire-crossing” arrows σm,n that also must be preserved:
Fσm,n = σm,n ④
That takes care of all the structure. So if we can find a translation F that satisfies ①, ②, ③ and ④, we have got ourselves a homomorphism of PROPs.
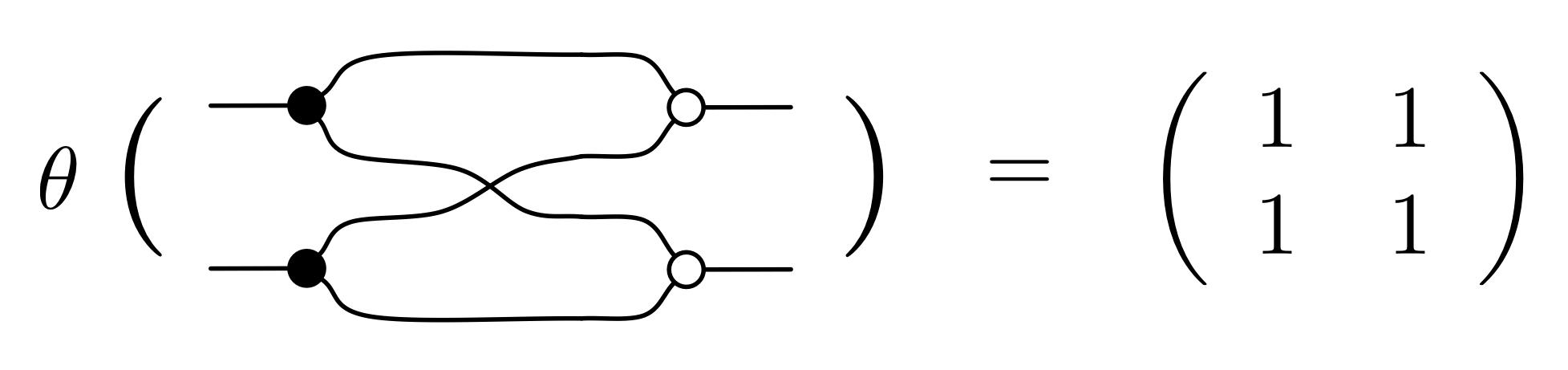
Back in Episode 11 we started to define a translation called θ. There we listed the matrix that is assigned to each generator:
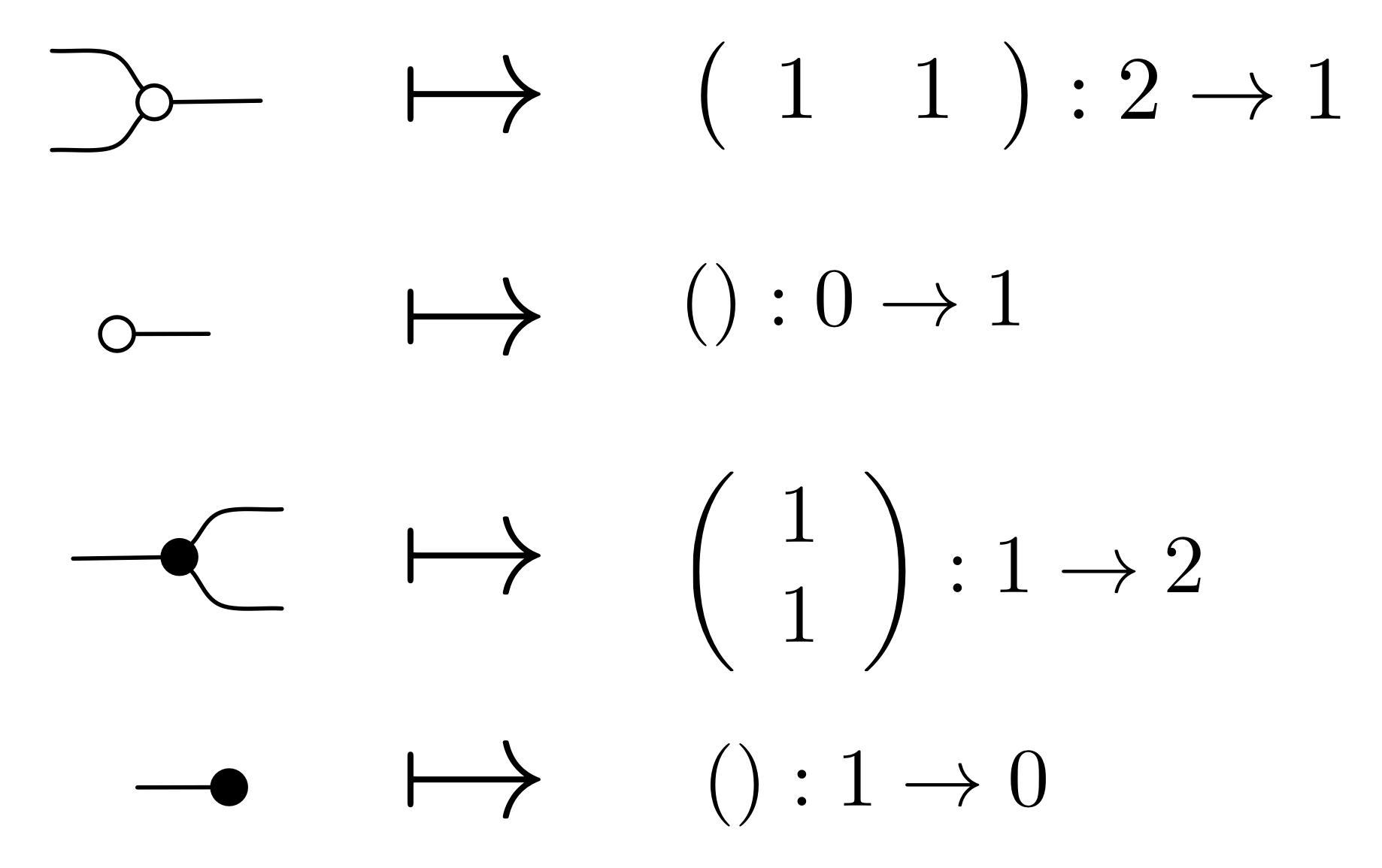
But to have a homomorphism from B to Mat, we need to give a rule θ that translates every diagram with m dangling wires on the left and n dangling wires on the right to an n×m matrix. It turns out that because of the way in which B is constructed, the above four rules tell us everything we need in order to define a homomorphism from B to Mat. All the other stuff is predetermined.
This is because B is special: it has diagrams as arrows, and every diagram is constructed from the four generators, identity and twist. That means that there is only one way we can extend the translation above so that it defines a homomorphism. We do not even need to say how to translate the identity and twist diagrams, since they are part of the PROP structure: they are respectively id1 and σ1,1 of the PROP B. And ③ together with ④ tell us that they must be translated to id1 and σ1,1 in the PROP Mat:
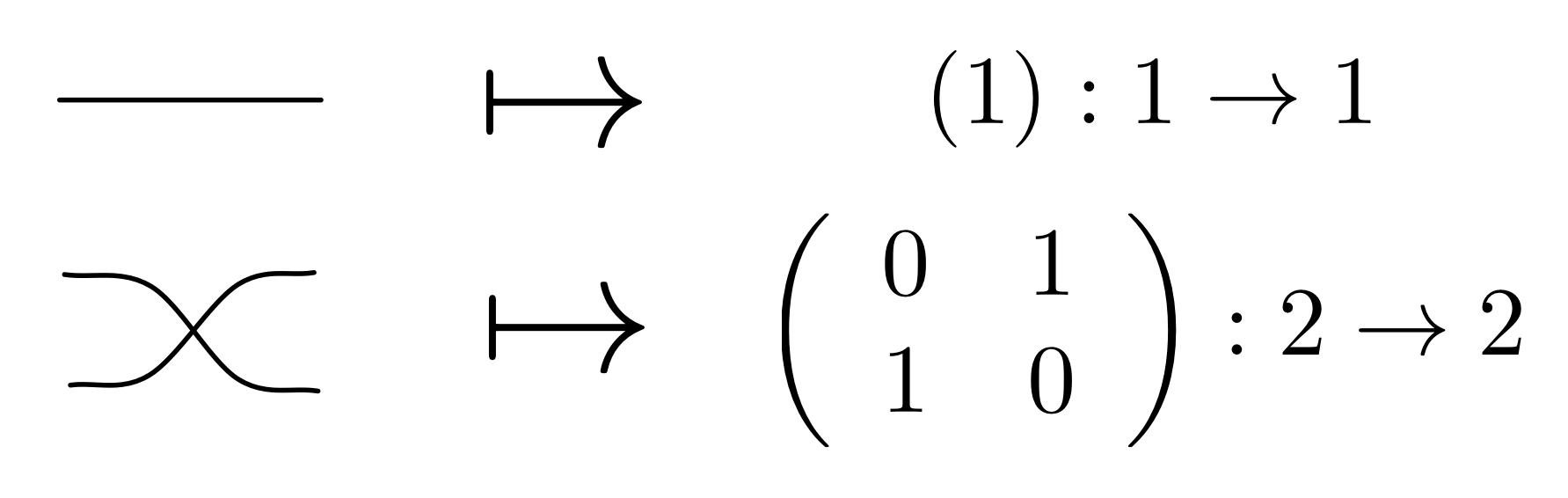
Next, since we already know how to translate the most basic diagrams, rules ① and ② give us the recursive rules for translating more complex diagrams. We already worked through an example.
Because of the middle-four interchange and the identity laws it does not matter how we subdivide the diagram: since Mat is also a PROP, it also satisfies these laws. Moreover, the procedure is well-defined, since, as we have seen in the last two episodes, diagrammatic reasoning amounts to using equations that hold in any PROP, and the additional equations of B that can be shown to hold in Mat: we did the work of checking this back in Episode 11.
That alleviates all of our fears from when we started discussing the translation. All that hard work of going through PROP lore is finally paying off! If you are not that impressed then don’t worry, we will have the opportunity to see many other examples of PROPs in action further on in the story.
Stepping back a bit from what we’ve been doing above, there is one thing worth mentioning. Back when we were talking about how natural numbers can be seen as special kinds of diagrams, I mentioned that they are free: two diagrams are considered to be equal exactly when we can prove it using diagrammatic reasoning and our equations.
In fact, the PROP of diagrams is the free PROP on the four generators and ten equations. This is the “special” nature of B that I alluded to before, and the thing that makes PROP homomorphism from B pretty easy to define: we just need to show where the generators go and make sure that the equations of B are also true in the codomain PROP.
How can we tell, in general, that two different languages can express exactly the same concepts?
One way is to construct a perfect translation. To understand what this could mean, we could start by thinking what non-perfect translations look like. For example, let’s pretend that I claim to be qualified English to French translator—which I’m definitely not, by the way—and you give me two English words to translate, say serendipity and dog. Suppose that both of the times I say chien. Then my translation cannot be very good, even if you don’t know what the word chien means.
The reason is that you could ask me to translate chien back to English. This would force me to choose one of serendipity or dog, or maybe something else entirely. If I say dog then you know that something went wrong: you asked me to translate serendipity to French, I said chien, then you asked me to translate back and I said dog.
serendipity → chien → dog
Since you know that serendipity and dog are two different concepts, something clearly got lost in the translation. Even If I said serendipity, you would still be able to catch me out, since then the translation chain would be:
dog → chien → serendipity
The moral of this story is that we would expect that a reasonable translator would not translate two different concepts in English to the same word in French.
The mathematical jargon adjective for such reasonable translations is injective. And because PROPs come from category theory, they inherit their own special jargon: a homomorphism F : X → Y is said to be faithful when,
given two different arrows A ≠ A’ : m → n in X, we have FA ≠ FA’: m → n in Y.
Another way a translation, say from Klingon to English, could be less than satisfactory is if there are some words in English for which a word in Klingon does not exist. This is likely because Klingon only has about 3000 words: so some English words like “serendipity” do not have a Klingon equivalent. But don’t quote me on that, I’m not an expert in Klingon.
The common mathematical jargon for a translation that hits every word in the target language is surjective, and in the world of PROPs the word is full. So a PROP homomorphism F: X → Y is said to be full when
for all arrows B: m → n in Y, there exists an arrow A: m → n in X such that FA = B.
It turns out that a homomorphism F: X → Y that is both full and faithful is perfect in the the following sense: there exists a translation G: Y → X that “reverses” F. G is called the inverse of F and satisfies the following two properties:
- for all arrows A: m → n in X, GFA = A
- for all arrows B: m → n in Y, FGB = B
So if I start with some A in X, translate it to Y and translate back again I end up where I started. Same if I start with some B in Y. There is a special word for homomorphisms that have inverses: they are called isomorphisms. A translation that has an inverse is about as perfect as one could expect.
The PROP homomorphism θ: B → Mat is full and faithful and thus an isomorphism of PROPs. We will discuss why this is the case in the next episode.
The upshot of θ being an isomorphism is that the diagrams of B and matrices of natural numbers are really two languages that talk about the same thing. In particular, we should be able to translate concepts from one language to the other.
Here’s one example: we saw that the bizarro operation on diagrams, where we reflect a diagram and interchange white and black, is quite useful: it has already saved us quite a bit of work with proofs, since a proof of any claim can always be translated to a bizarro proof of the bizarro claim. So what does it mean to consider the bizarro version of a matrix: that is, if I start with a diagram D and its bizarro version Dbizarro, what is the relationship between matrices θD and θDbizarro?
Well, it turns out that the equivalent concept for matrices is called transpose. If I give you an m×n matrix A (n columns, m rows) then its transpose AT is an n×m matrix (m columns, n rows) that has, as its entry at the ith row and jth column, the entry at the jth row and the ith column of A. Intuitively speaking, the rows of A become the columns of AT. Here’s an example, if I let A be the matrix
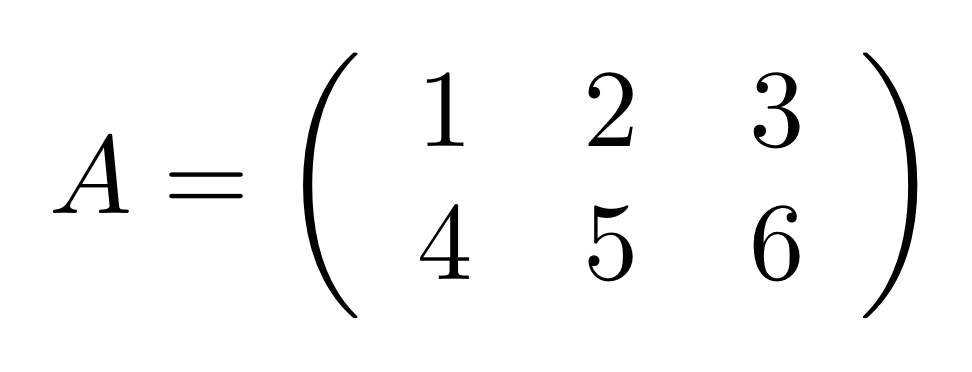
then its transpose is the matrix

What about a concept that maybe you’ve come across in the language of matrices? For example, linear algebra courses usually go on about special kinds of matrices called row vectors and column vectors. A row vectors is simply a matrix with exactly one row, and a column vector is a matrix with exactly one column.
So the concept of a row vector, translated to the world of diagrams, is a diagram with exactly one dangling wire on the right. Here’s an example:
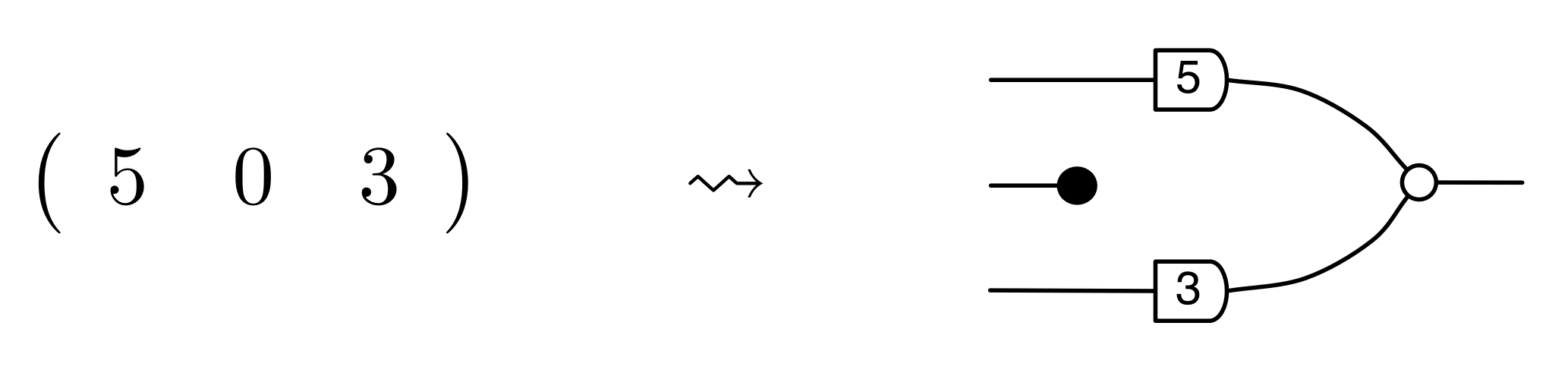
Similarly, a column vector translates to a diagram with exactly one dangling wire on the left. Like so:

Some of you, especially those who are already familiar with matrices, are probably asking yourselves what is the point of having two languages to describe the same thing. It all seems to be a bit redundant, since you already know about the concept of a matrix of natural numbers. Please hang in there for now: I hope to convince you that looking at the world through the prism of diagrams gives you a different, sometimes truly surprising perspective.
Continue reading with Episode 15 – Matrices, diagrammatically