
Before we get started, I have an annoucement. Recently I have been contacted by Vincent Verheyen, a Belgian polyglot mathematician/developer who generously offered to translate the blog into several languages, starting with Dutch and French, but also German, Spanish, and even Chinese (with the help of his girlfriend Chung-Yi Lan). The first few episodes are already available and more will follow in the coming weeks. Vincent has set up his website in a way that makes external contributions possible, and the translations themselves are published under the Attribution-ShareAlike 4.0 International licence. So, if you are interested, please do get involved! I’m really honoured that Vincent has invested his time and energy in this effort, and it’s wonderful that the material will find a wider readership: at the moment, about 80% of the hits on the blog are from English speaking countries.
There is a new video series on YouTube by 3Blue1Brown called “Essence of linear algebra”. It’s slick and gives visual intuitions for matrices, spaces, determinants etc. It makes the important point that intuitions are not emphasised enough: too often linear algebra is presented as a series of definitions and algorithms to memorise. But you’ll notice that the diagrams there are quite different to the kinds of diagrams on this blog. The series has inspired me to think about the “essence of graphical linear algebra”. The story on this blog has been divided into bite size chunks, and as a result, it is sometimes difficult to see the wood for the trees. So in this episode we take a step back and look at the big picture. But first, let’s start with a little history.
Early 20th century mathematicians and logicians were a nervous lot, facing an existential crisis and a severe inferiority complex. Engineers were building astonishing machines that transformed the world in the timespan of a single generation. Their work was made possible by physicists who made breakthroughs in understanding the basic laws that govern the physical world, and by chemists who charted interactions between different types of molecules and compounds. For all of these pursuits there was an external reality to point to, a sanity check. A plane that did not fly was not much use; the design was improved or thrown out. Similarly, theories in the physical sciences could be put to the test in the lab. They were falsifiable: if experimental data did not fit the theory, it was the theory that was thrown out, not the real world.
Mathematicians, instead, worked with abstract systems, applying various levels of rigour. Instead of an external reality, they could point to the beauty and intellectual depth of their intuitions and results. An added bonus was—as the physicist Eugene Wigner put it in 1960—the unreasonable effectiveness of mathematics in the natural sciences. Therefore the party line was (and still is) that even if the applications were not immediately obvious, eventually research in mathematics pays off. Mathematical advances are thus a vital ingredient in the supply chain of civilisation and technological advancement.
It’s a nice story, but what if it’s all built on sand? The mathematician’s ultimate defence–and for many the raison d’être of the entire discipline–is rigour and logical certainty of the work. Unfortunately, this was shaken up severely by Bertrand Russell in 1901 with his famous paradox. We have already seen that Russell had interesting things to say about causality. With the paradox, he showed that (naive) set theory, a branch of mathematics developed in the 19th century as a unifying formalisation for mathematics, was inconsistent. Basically, this meant that any proposition whatsoever could be proved. We could prove 2+2=4, but we could also prove 2+2=5. Nothing could be falsified because everything was both true and false at the same time. This, understandably, led to a moral panic. There were several important consequences, including Hilbert’s programme, Zermelo-Frankel set theory, Gödel’s incompleteness and Nicolas Bourbaki.
This blog is not about philosophy of mathematics, so I will skip right ahead to the main point: my intense dislike of Bourbaki. If you have not heard of Bourbaki before, it’s a rather romantic, movie-script kind of story: the scene is Paris in 1935, where a group of young, disaffected, rebel mathematicians wanted to change the world; or, at least, their discipline. They began to discuss their ideas of how to change mathematics, which they saw as too often informal, too disconnected, old-fashioned and chaotic. It was time for a revolution.

Street scene, Paris 1935.
To emphasise the collective nature of the endeavour, they published under the nom de guerre Nicolas Bourbaki. From 1939 onwards, Bourbaki authored a series of very influential textbooks. The project continued and gained power and prestige: over subsequent decades the group’s membership changed and at various times included many of the leading lights of modern mathematics as contributors, people such as Eilenberg and Grothendieck. The following is a description by Marjorie Senechal, taken from her wonderful 1997 interview with Pierre Cartier, a Bourbaki member between 1955 and 1983:
From its beginning, Bourbaki was a fervent believer in the unity and universality of mathematics, and dedicated itself to demonstrating both by recasting all of mathematics into a unified whole. Its goals were total formalization and perfect rigor. In the post-war years, Bourbaki metamorphosed from rebel to establishment.
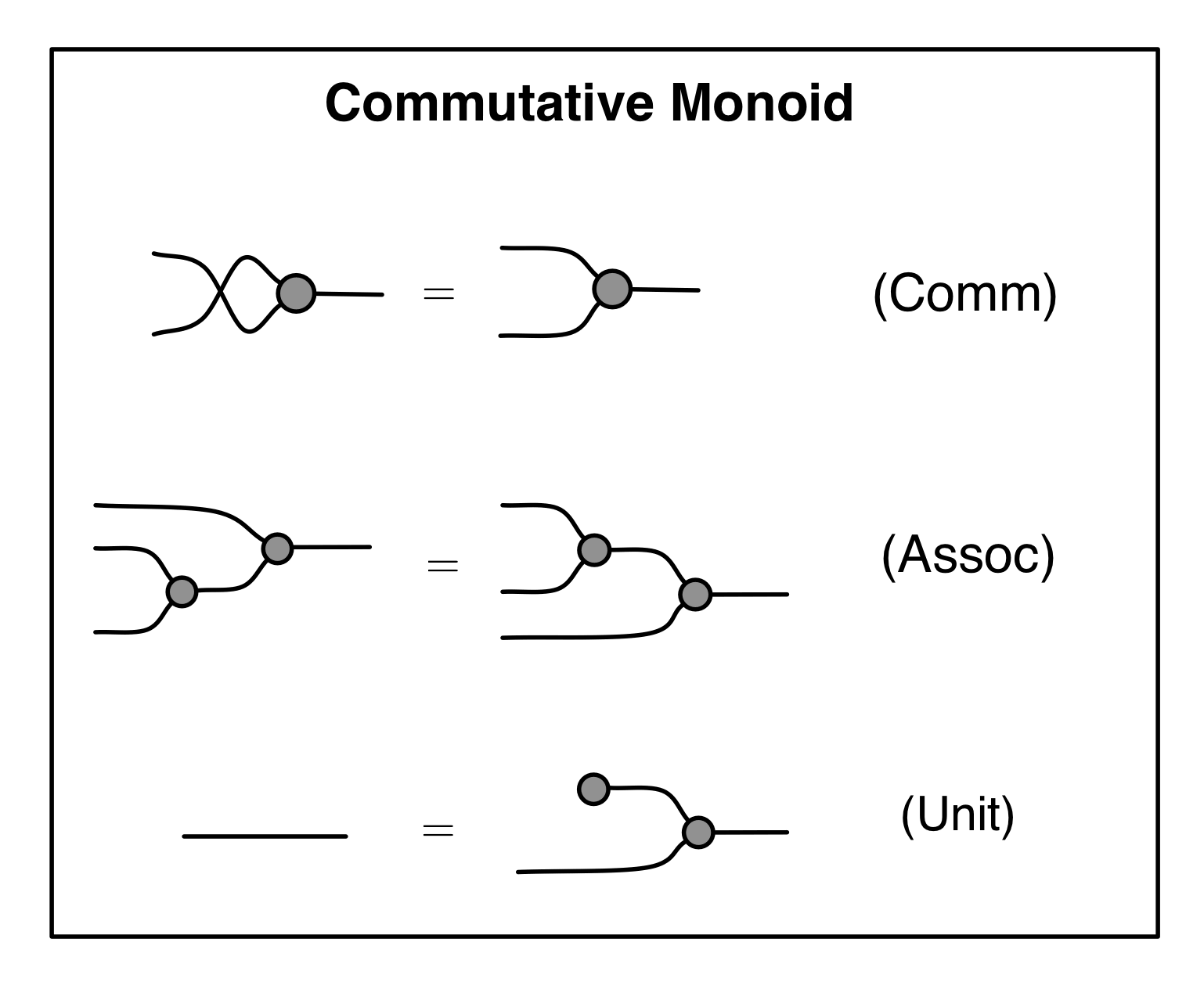
Bourbaki’s unifying idea was that mathematics ought to be viewed as the study of mathematical structures. A mathematical structure is a set, i.e. an abstract collection of elements, with some structure: e.g. operations, subsets, constants. These then are required to satisfy a number of axioms. A vector space is one example: it is a set, whose elements we call vectors, containing a special element 0, an action of a field on that set, and an addition operation, all together satisfying a long list of axioms. All this data is now found in the first two pages of any advanced linear algebra textbook. Indeed, linear algebra–from the point of view of a Bourbakian–is the study of the mathematical structure called vector space. End of story.
Bourbaki resulted from similar currents of thought that produced fascism and totalitarian communism: moral panics leading to revolutions, and ultimately “final solutions”, all terrible and evil in various ways and degrees. Bourbaki was an attempted “final solution” for mathematics. This is not my hyperbole: in Senechal’s interview, Cartier says:
A final solution. There are good reasons to hate that expression, but it was in the people’s minds that we could reach a final solution. … In science, in art, in literature, in politics, economics, social affairs, there was the same spirit. The stated goal of Bourbaki was to create a new mathematics. He didn’t cite any other mathematical texts. Bourbaki is self-sufficient. … It was the time of ideology: Bourbaki was to be the New Euclid, he would write a textbook for the next 2000 years.
Bourbaki’s new mathematics had no space for pictures. Diagrams were too fragile, not nearly mensch enough. Cartier says:
Bourbaki’s abstractions and disdain for visualization were part of a global fashion, as illustrated by the abstract tendencies in the music and the paintings of that period.
Bourbaki is the reason why we still have boring textbooks in mathematics in general, and linear algebra in particular. Bourbaki hated intuitions. Bourbaki is partly responsible for the insane levels of specialisation in modern mathematics. In this blog we fight Bourbakism. ¡Hasta la victoria siempre!
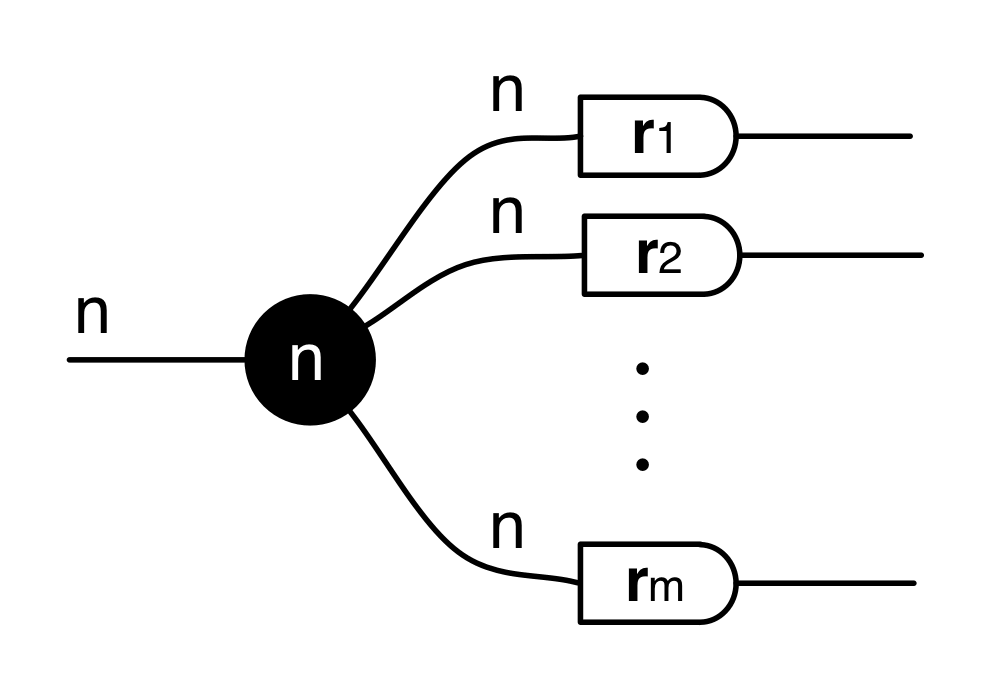
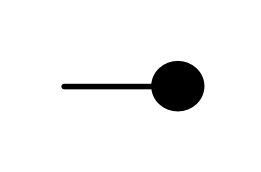
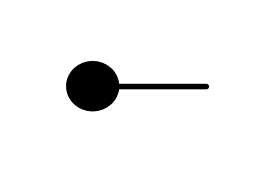
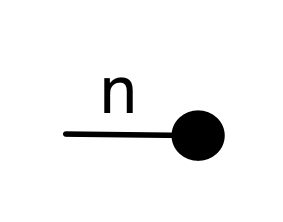
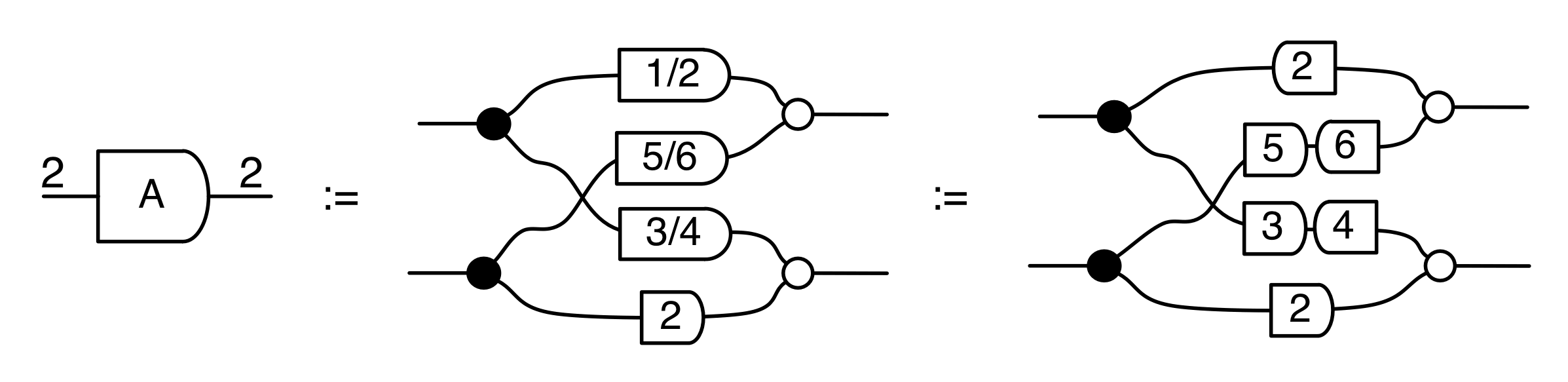
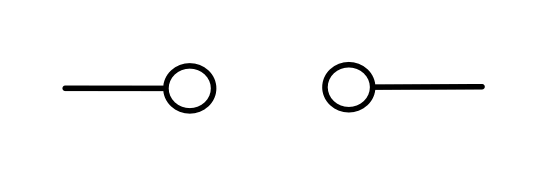
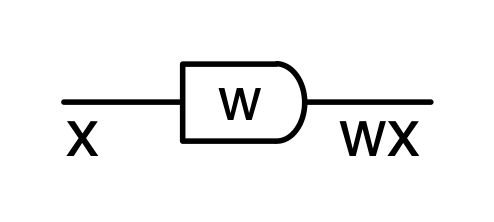
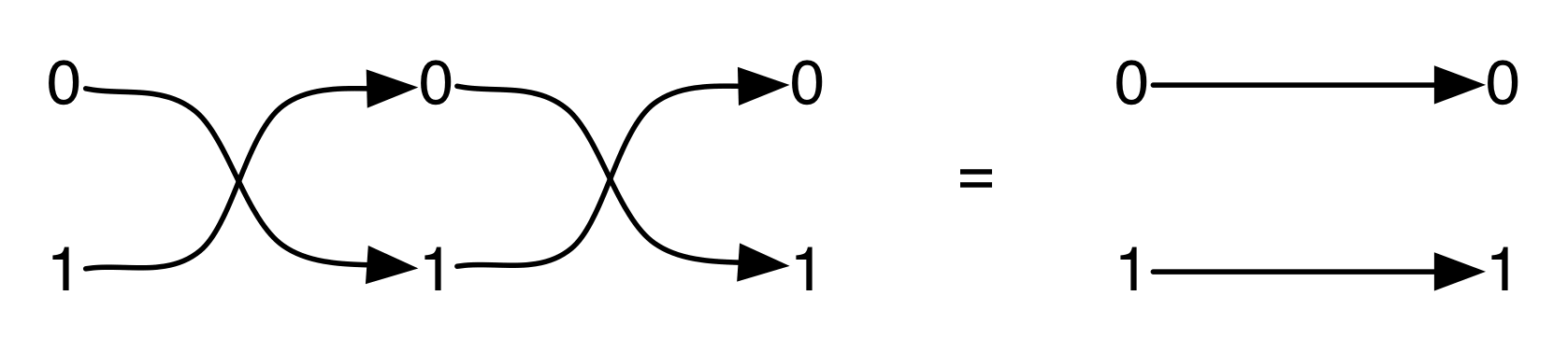
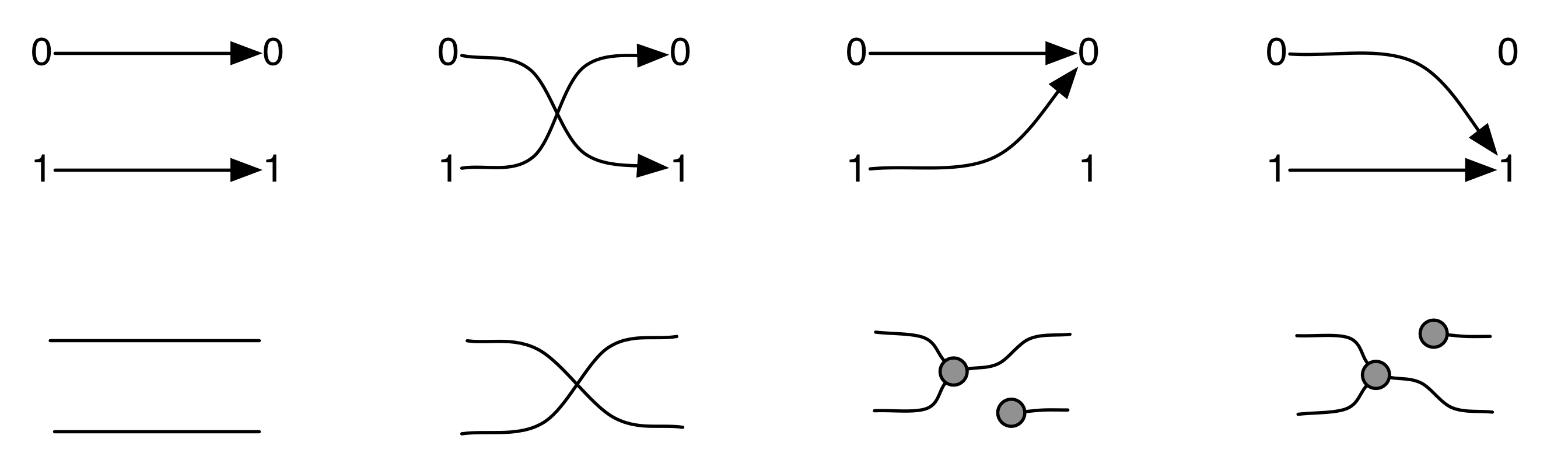
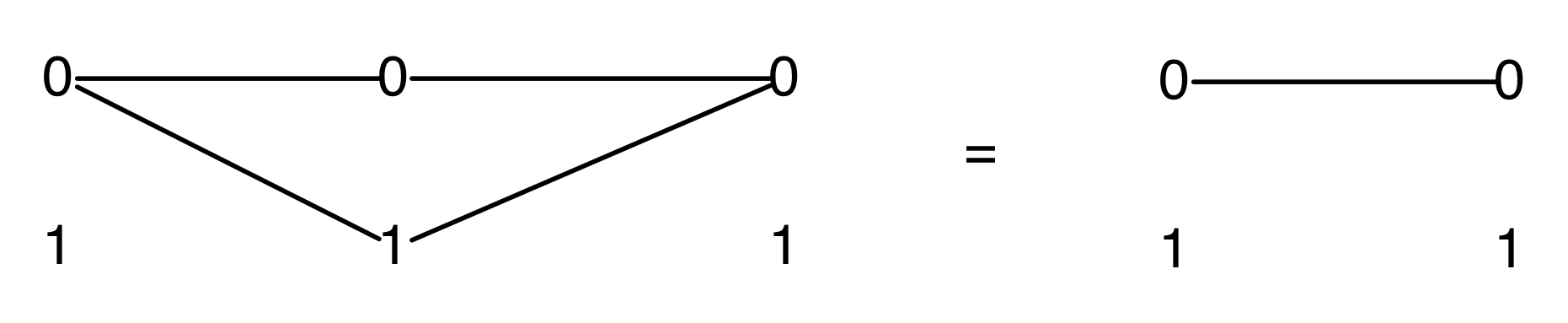
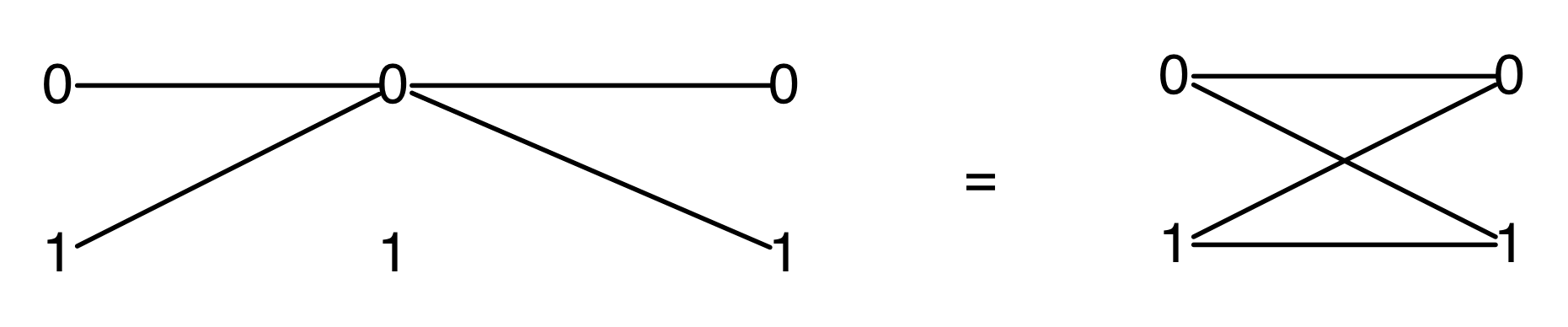
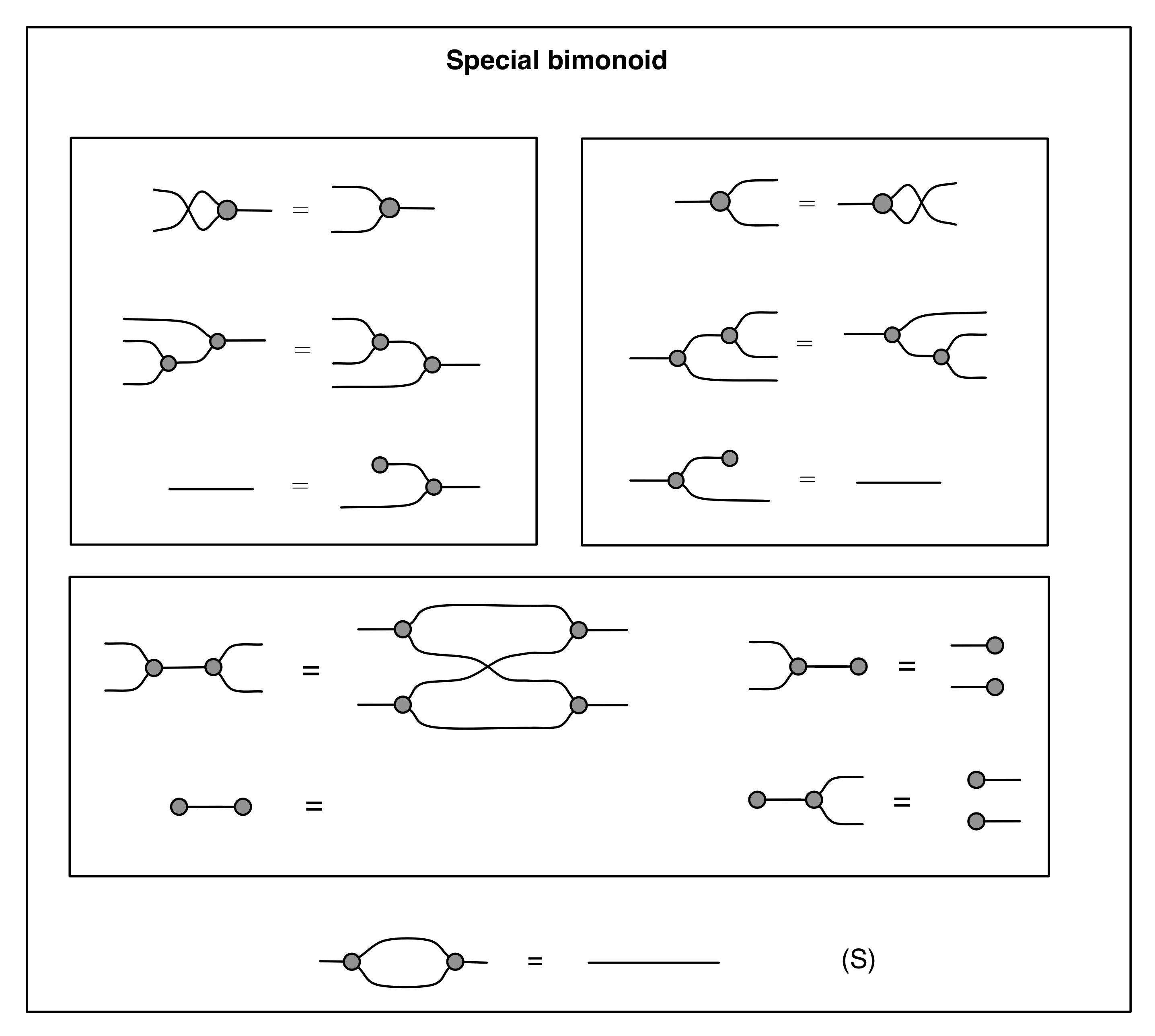
Graphical linear algebra is not the study of a mathematical structure in a Bourbakian sense. Instead, we use diagrams to describe linear algebraic concepts. So matrices are not homomorphisms between vector spaces, but diagrams in a theory of adding and copying. As we have seen, an m×n matrix A is a diagram with n dangling wires on the left and m on the right. In our graphical shorthand:
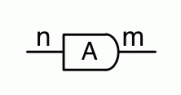
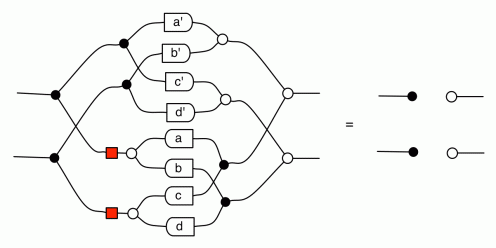
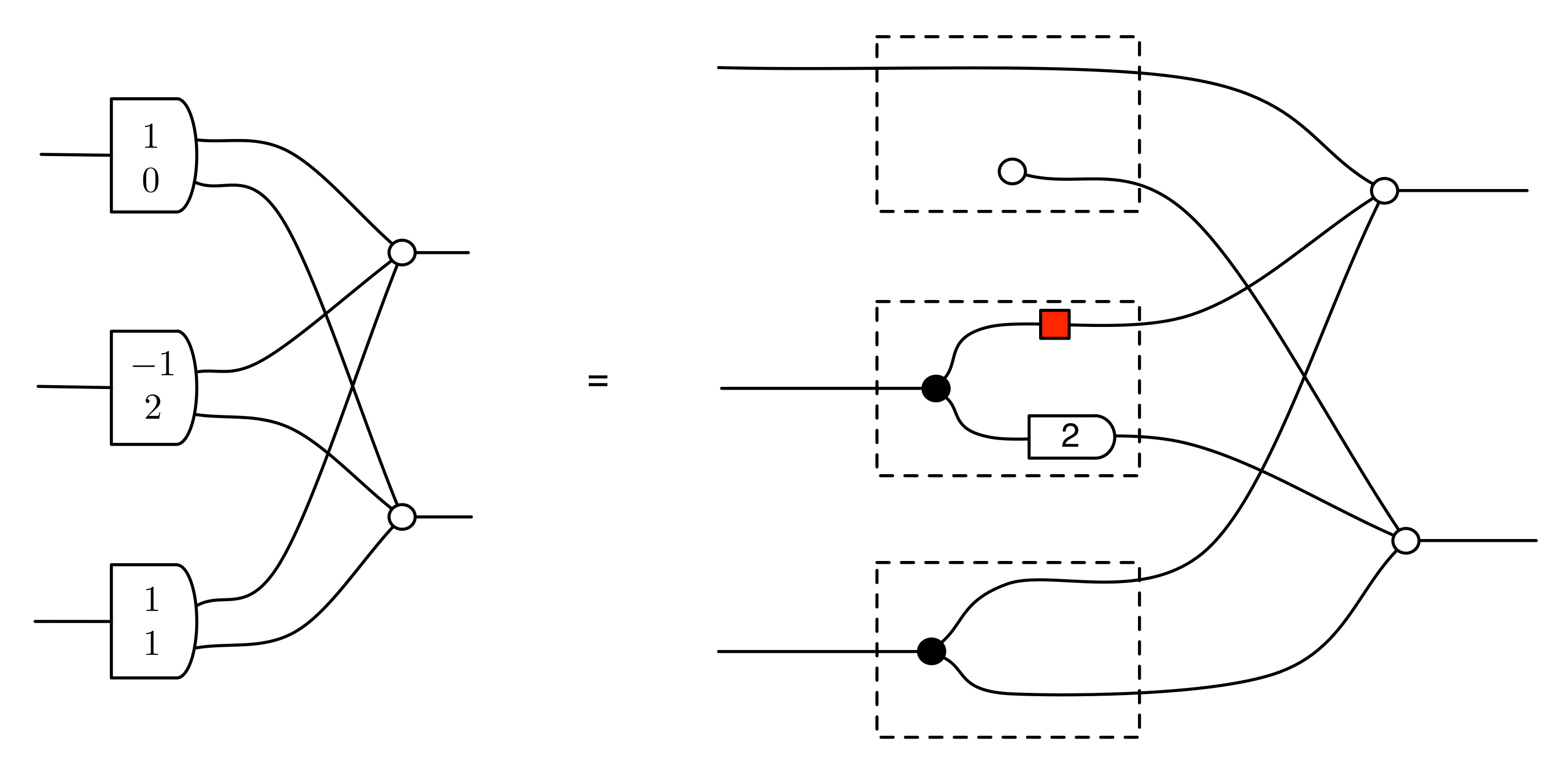
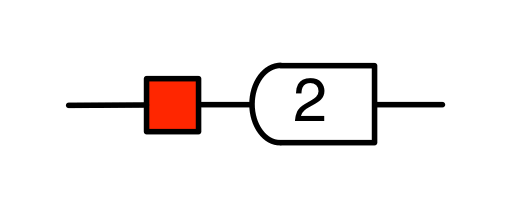
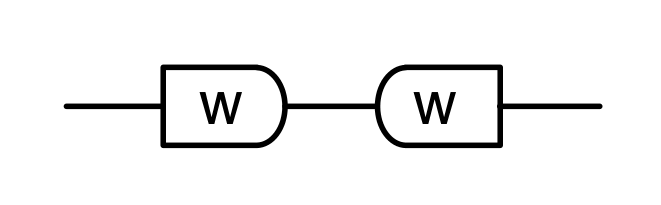
The cool thing is that matrices are just the beginning. For example, a Bourbakian would consider the kernel of A as a sub vector space ker A of the domain of A: that is, a set of vectors v such that Av = 0. In graphical linear algebra the kernel is not a set. As we have seen, it is also a diagram, one that is obtained in a modular way from the diagram for A.

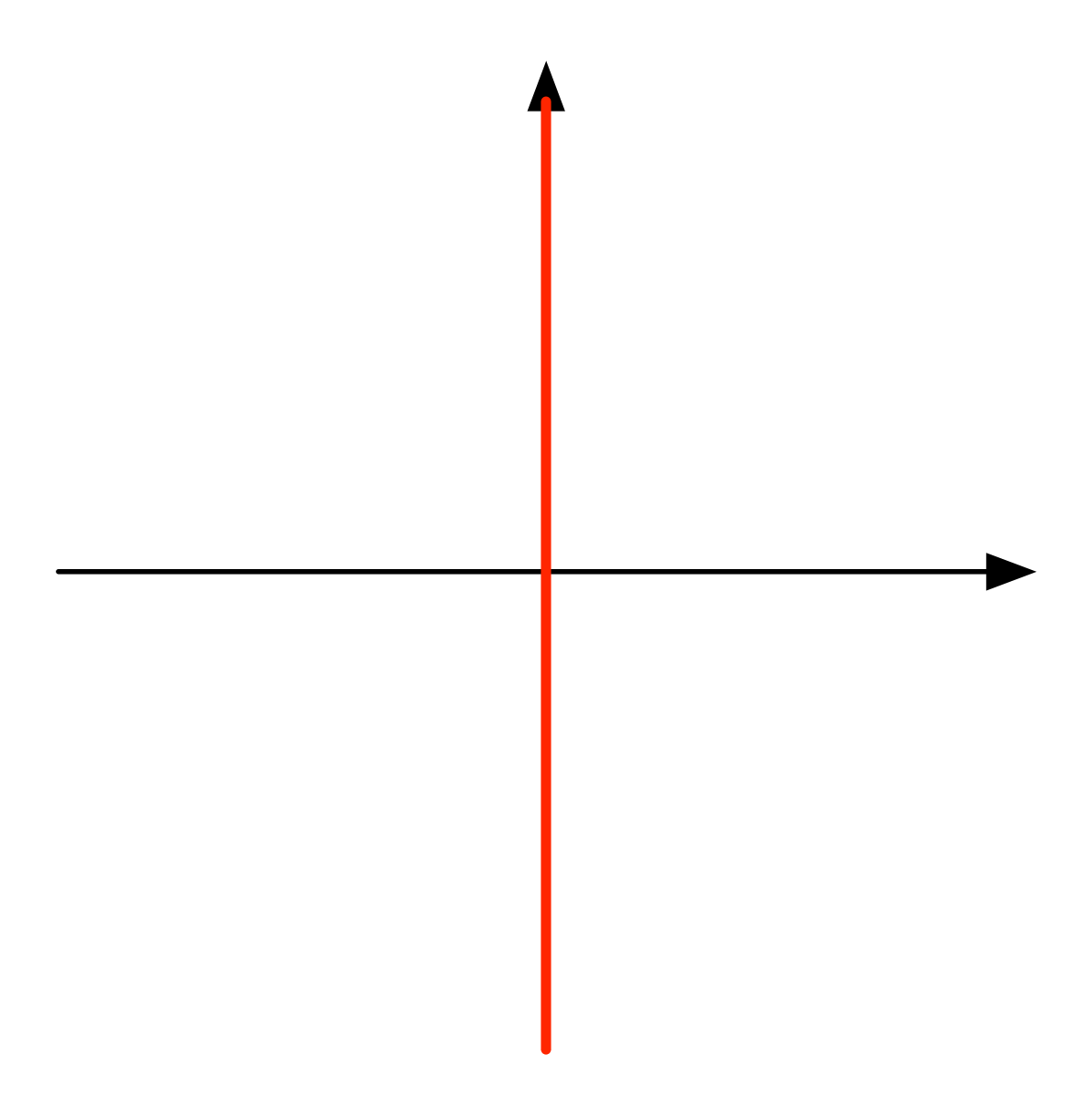
Similarly, the image of A is not the set { w | ∃ v. Av = w }. It is the following diagram.
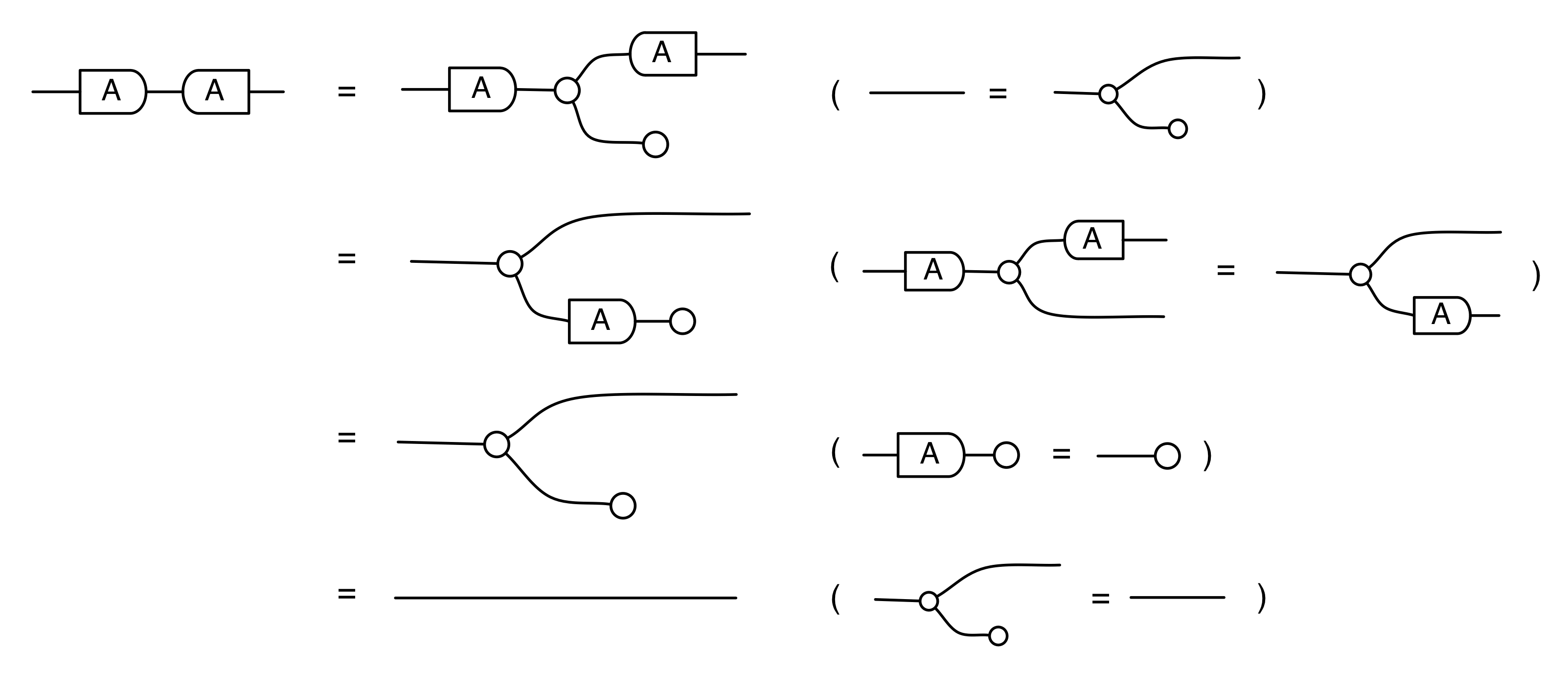
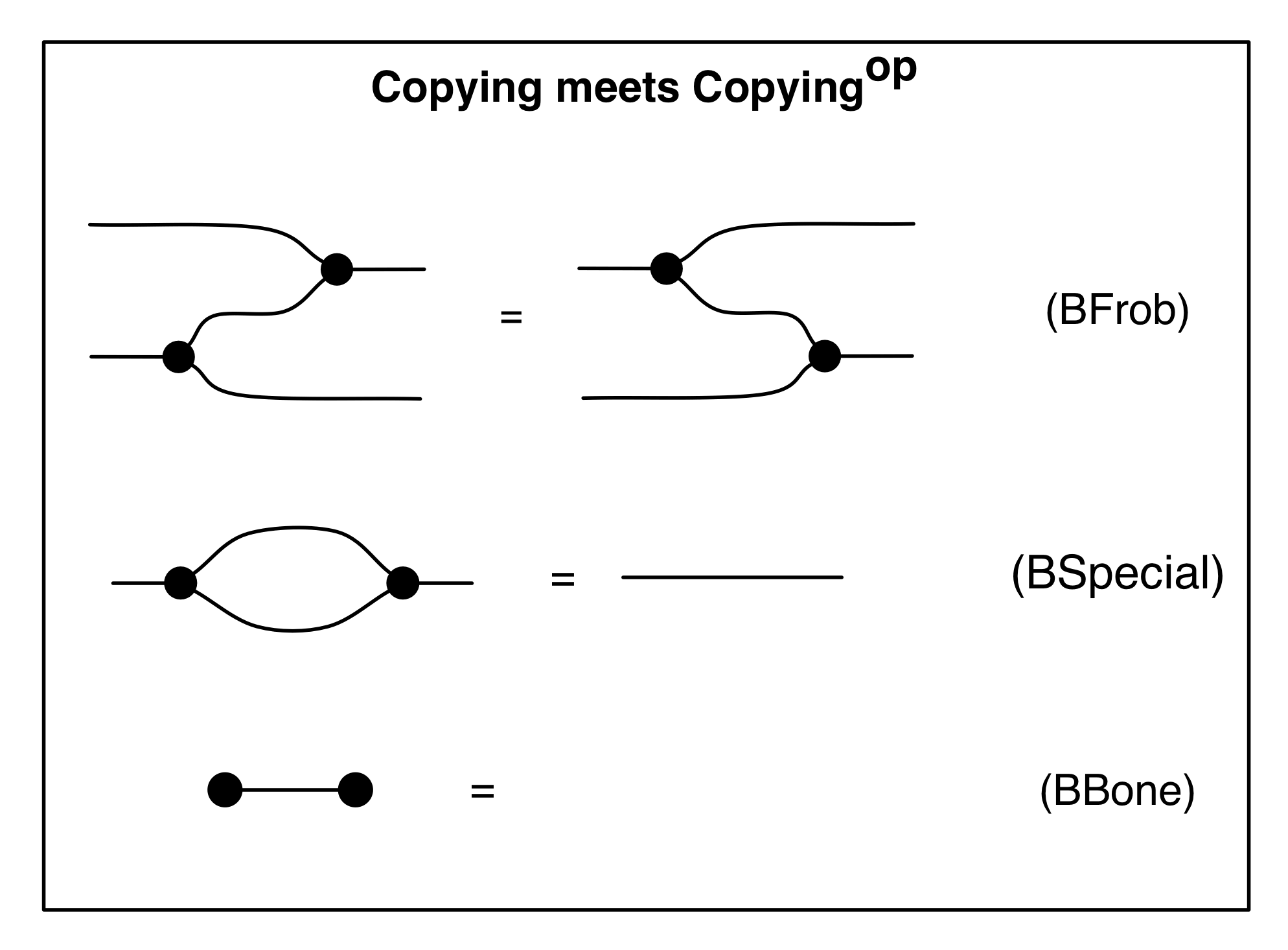
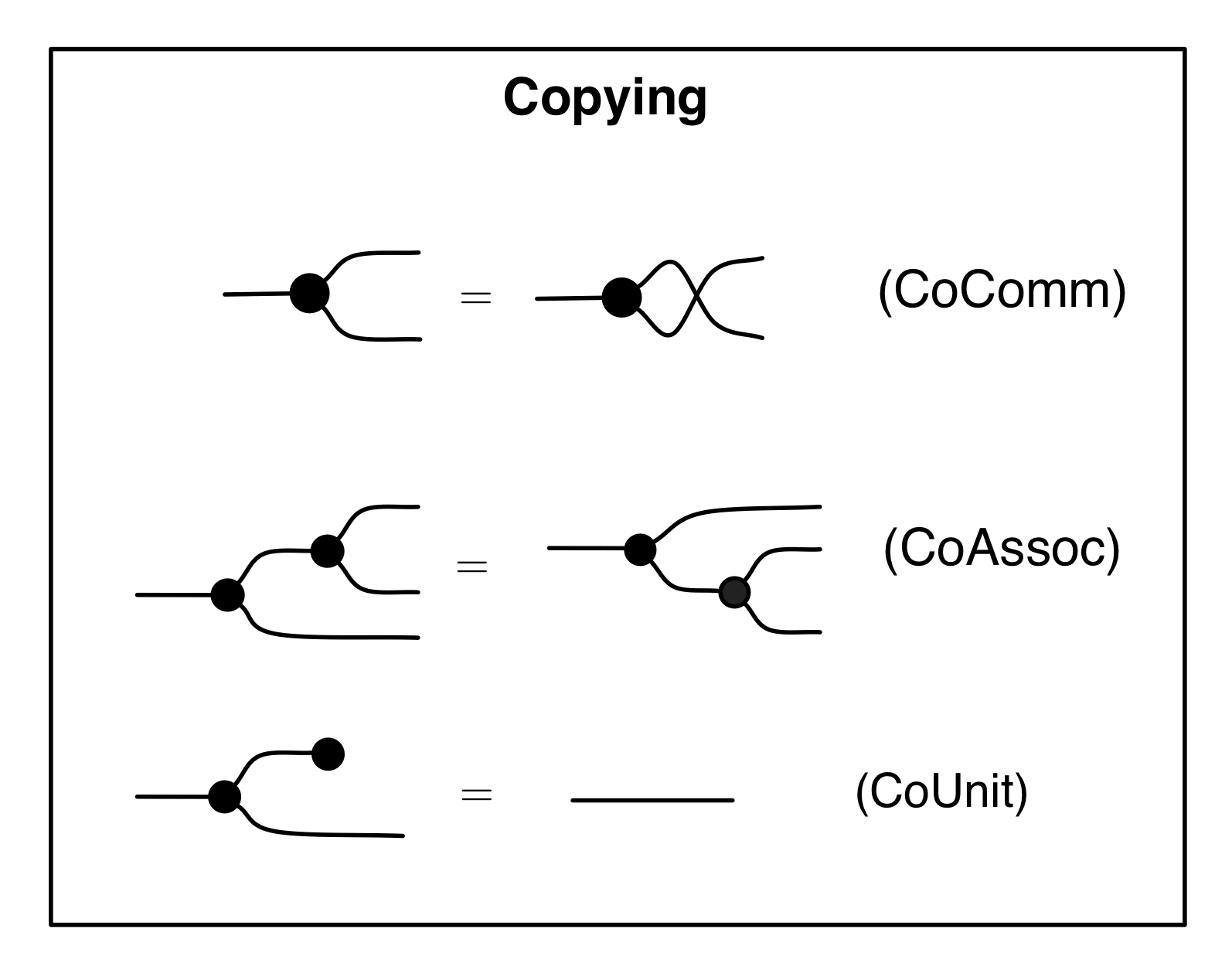
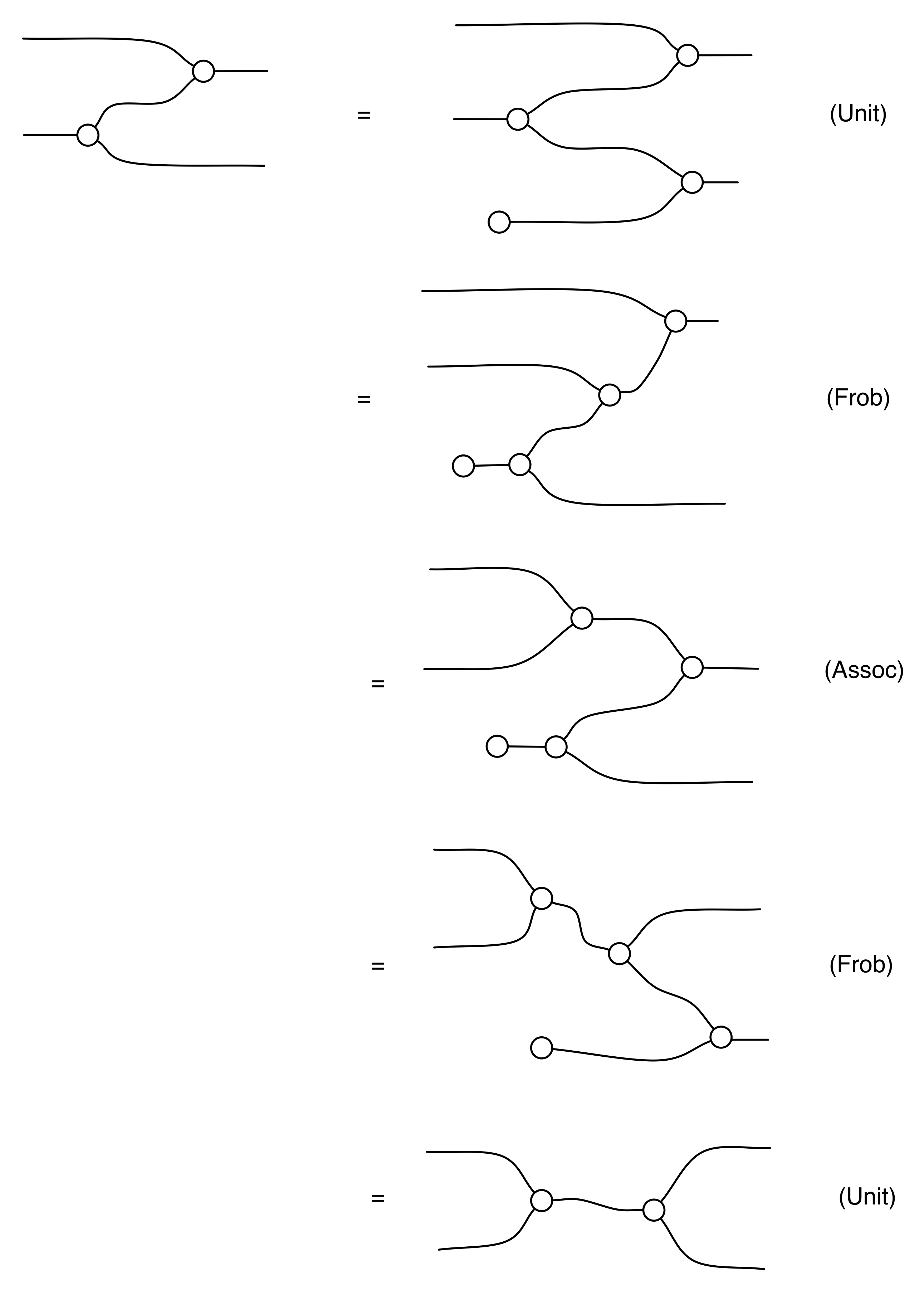
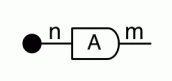 Our diagrams are not fragile. They are precise mathematical objects and come with a set of equations which allows us to write proofs, transforming one diagram into another. As we have seen, all of these equations have rather simple justifications and describe how an abstract operation of addition interacts with an abstract operation of copying. Hence the slogan, which we saw back in Episode 7:
Our diagrams are not fragile. They are precise mathematical objects and come with a set of equations which allows us to write proofs, transforming one diagram into another. As we have seen, all of these equations have rather simple justifications and describe how an abstract operation of addition interacts with an abstract operation of copying. Hence the slogan, which we saw back in Episode 7:
Linear algebra is what happens when adding meets copying.
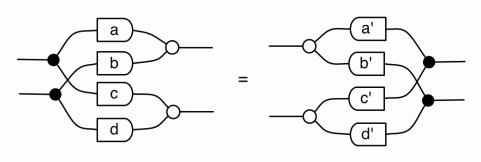
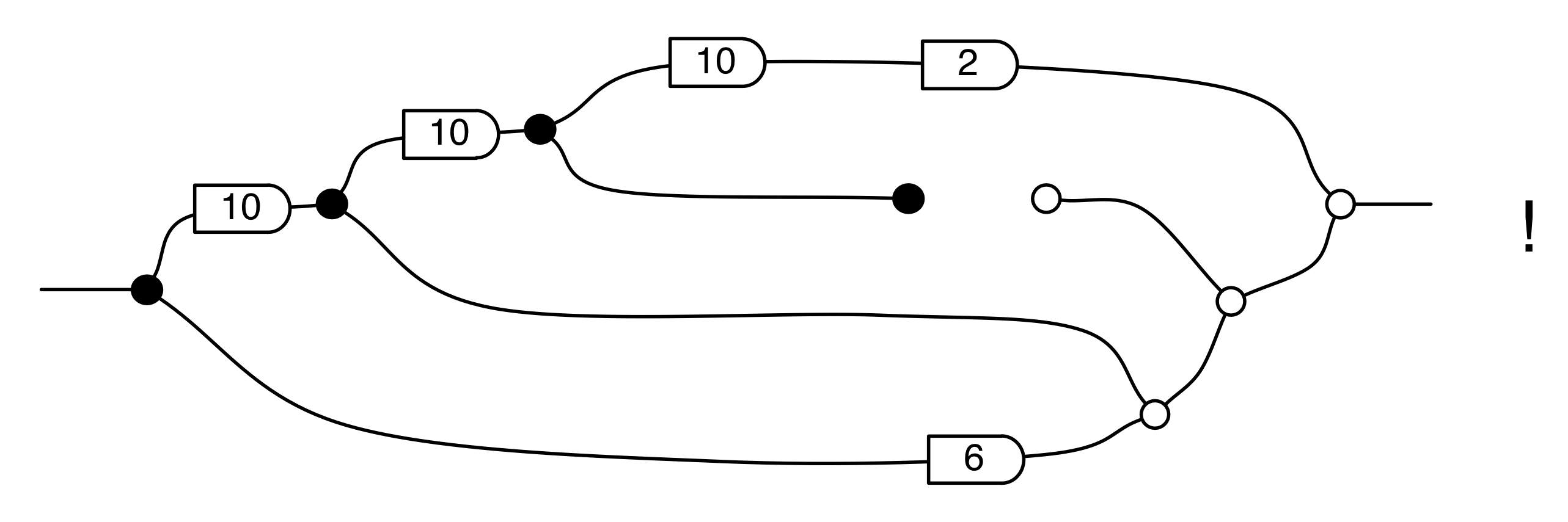
Proofs are done through diagrammatic reasoning, which we discussed in Episode 6 . Their style departs from Bourbakian set theoretic arguments like “take an element x in ker A”. To show, for instance, that A has a null kernel if it is injective, we start with the diagram for A, append another diagram to obtain its kernel, and use the assumption of injectivity to transform it into the diagram for the null subspace. We saw this in the last episode, but here’s that part again, diagrammatically.
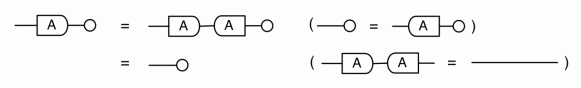
What really excites me about graphical linear algebra is the fact that it we can have our cake and eat it too: the diagrams provide intuition but are also sentences of rigorous, formal language.
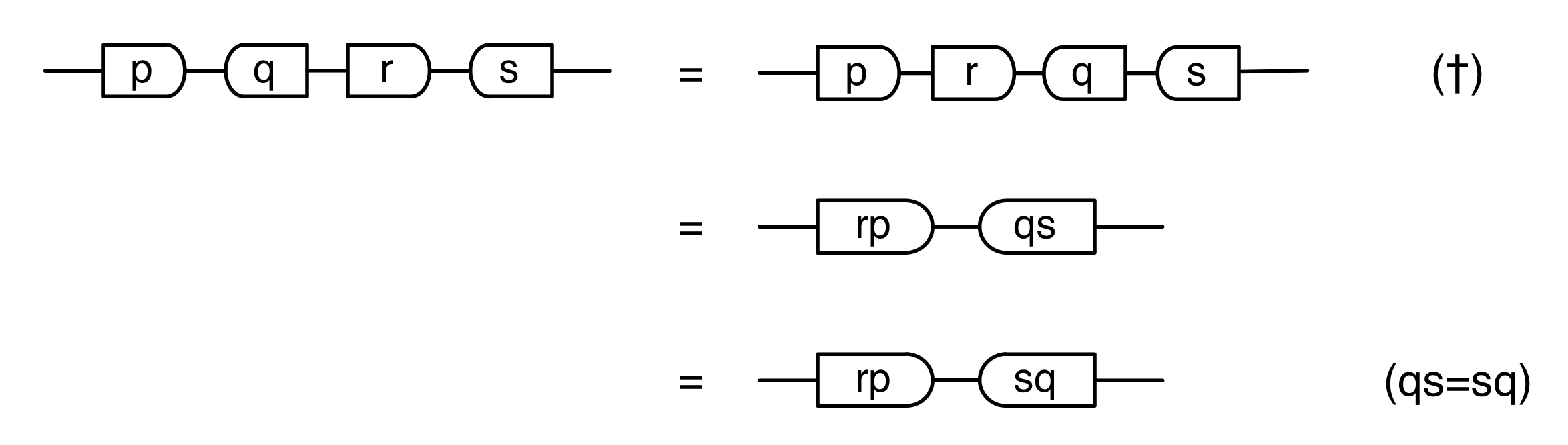
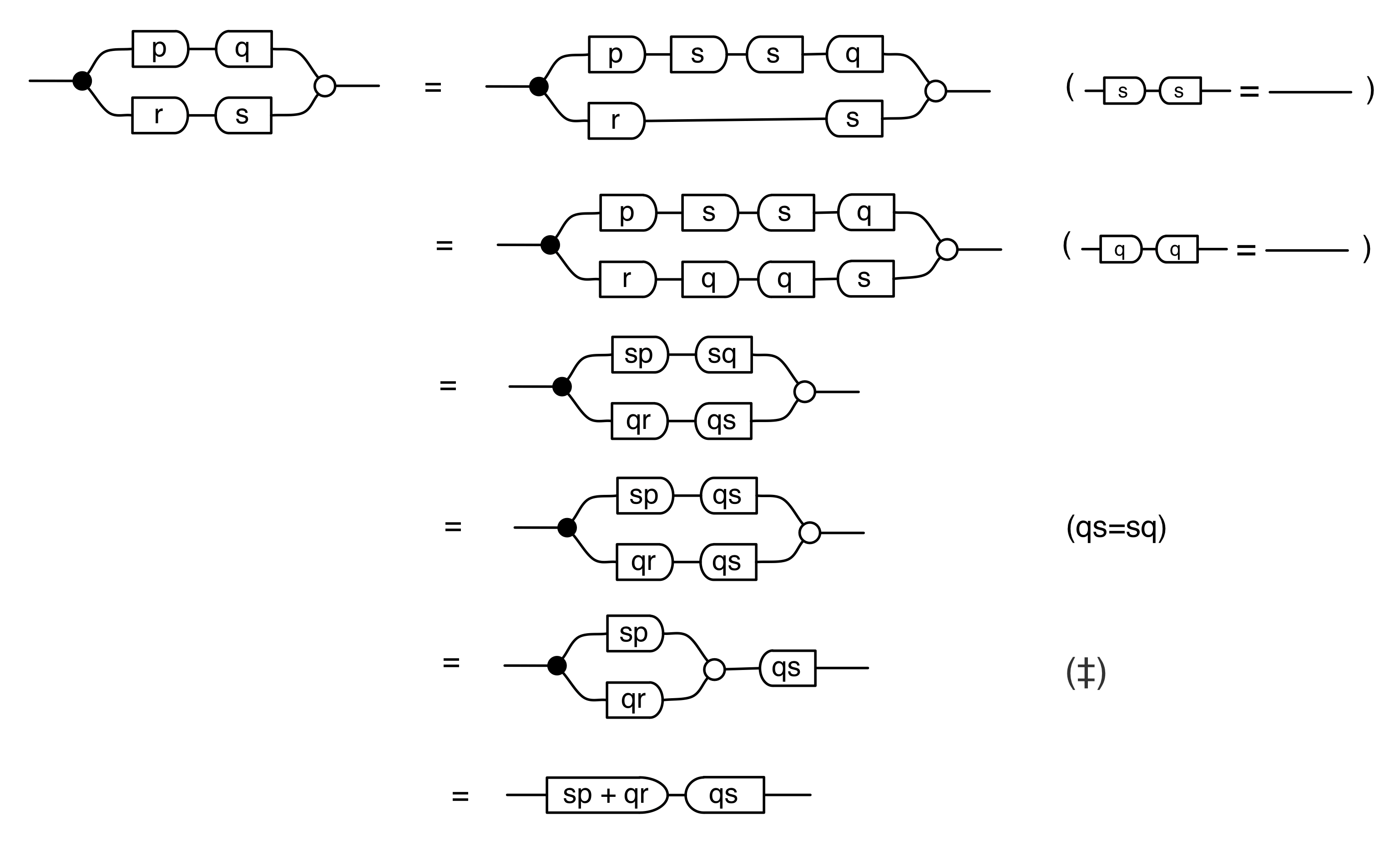
Moreover, the diagrammatic method feels like a high level language when compared to the low level “machine code” of Bourbakian mathematical structures. We saw that the concepts of natural numbers, integers and fractions all follow from the interactions of the basic generators. There was no need to encode these concepts as separate mathematical structures. And the story led to some surprises too: in particular, we had to get over our dividebyzerophobia.
I hope to emphasise the idea of “diagrams as a high level language” in the next ten episodes or so. My plan is to start exploring how string diagrams can help in describing and reasoning about physical systems; in particular we will look at things called signal flow graphs in systems theory. There are some surprises in store: we will look at the idea of feedback in a new way. As we have seen, feedback is a concept that deeply troubles people who believe in causality. If causalists had their way, they’d happy throw the real world away to get away from the problems that feedback brings.
Bourbakism was the effect of the foundational crisis in mathematics of the early 20th century. Mathematicians can feel a little bit more secure today: after all, computer science and the information revolution has been built on mathematics and formal logic. Mathematicians also no longer seem to care very much about foundations, and computers mean that we don’t need to taylor notation for ease and speed of calculation. Instead, we can emphasise what I believe is the true purpose of maths: making complicated, seemingly impenetrable things intuitive and simple.
My sabbatical has finally started. On Monday evening I arrived in Honolulu, and I will be working with Dusko Pavlovic at the University of Hawaii for the rest of the year. Dusko has been working on very exciting things, one of which is to try to understand the “essence of computability theory” with string diagrams, not unlike the kinds of diagrams that we’ve been using on this blog. He uses them to form a theory called monoidal computer. You can check out an introductory paper here. I’m really excited to find out more and hopefully contribute something interesting.
I will also, hopefully, have more time to write.
Continue reading with Episode 31 – Fibonacci and sustainable rabbit farming.


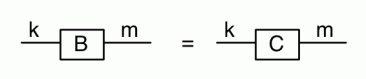
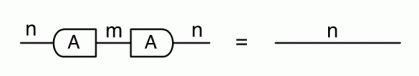

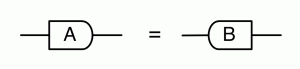
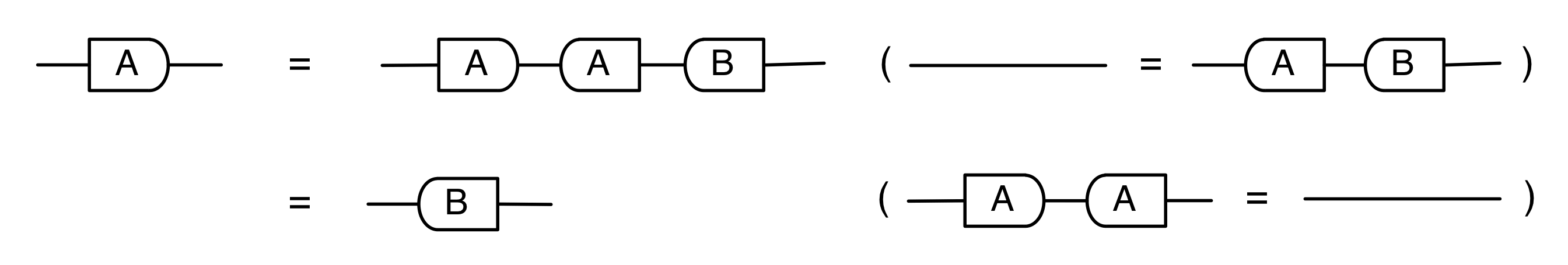
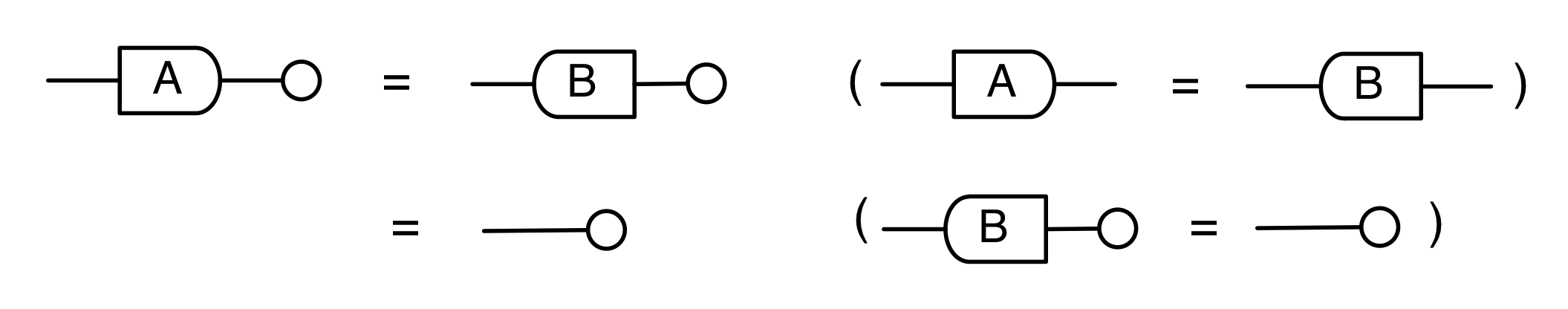


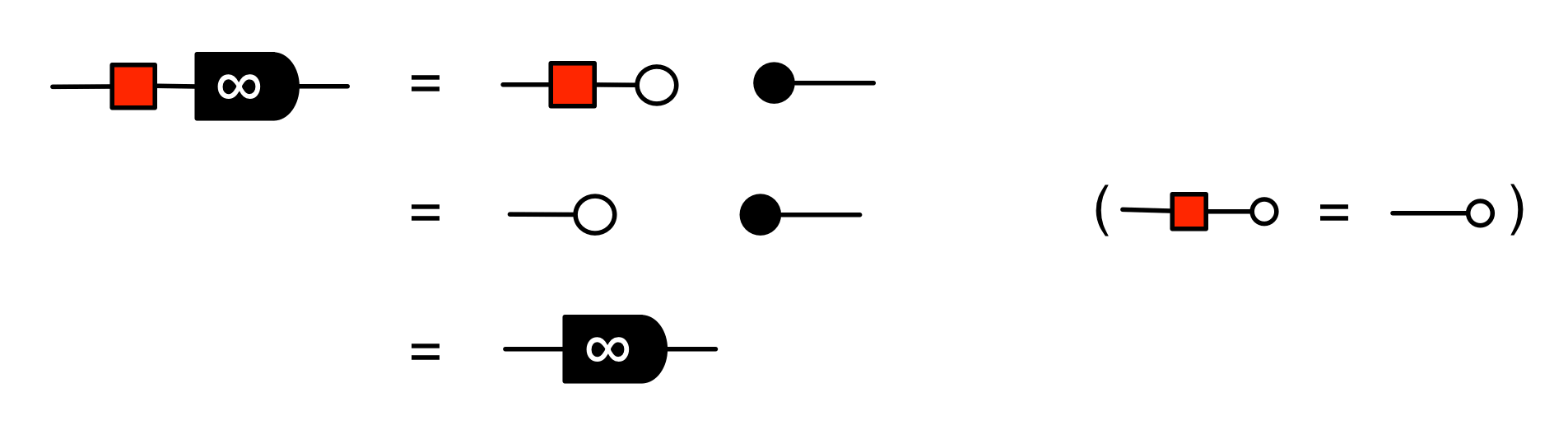
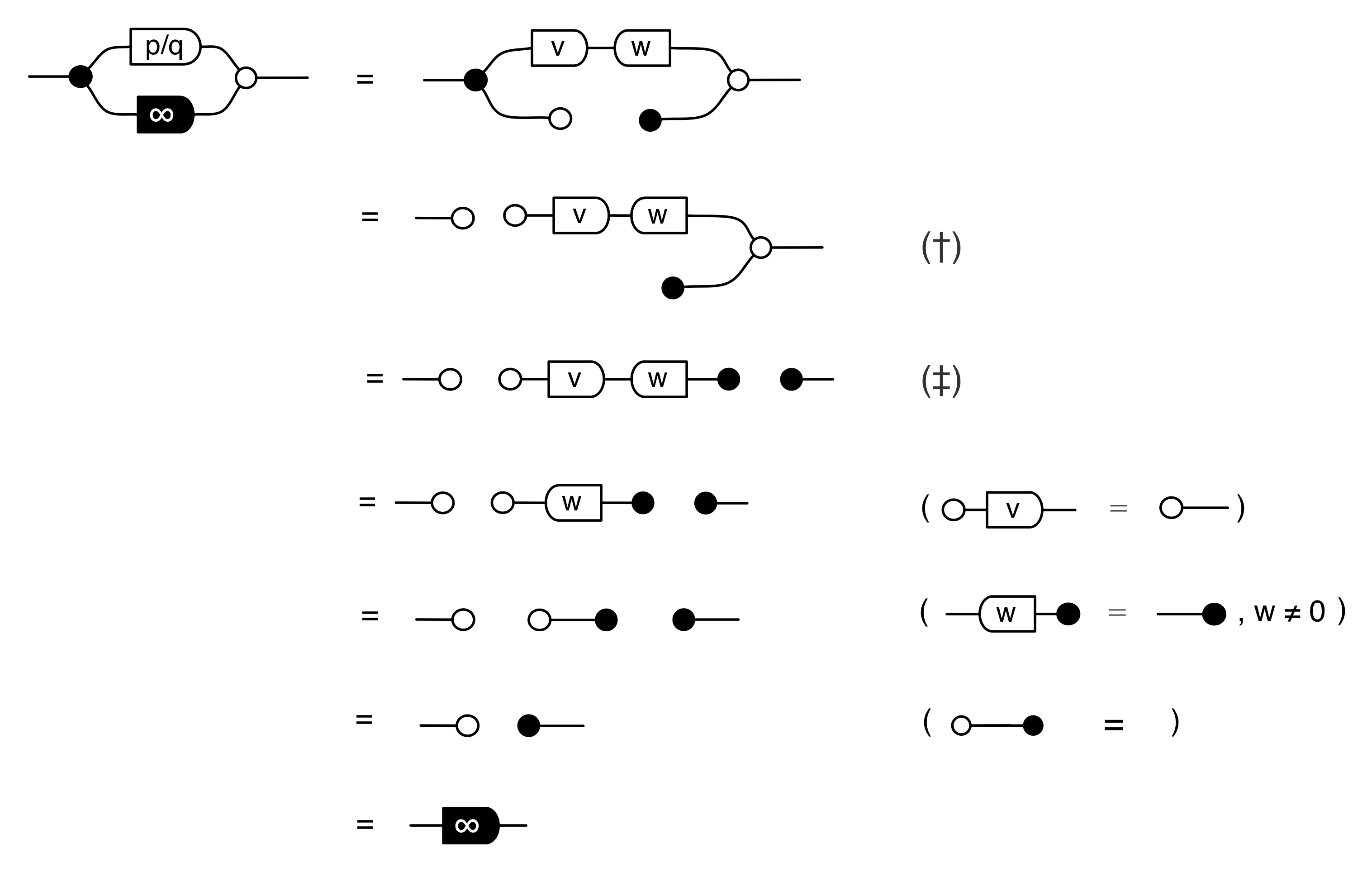
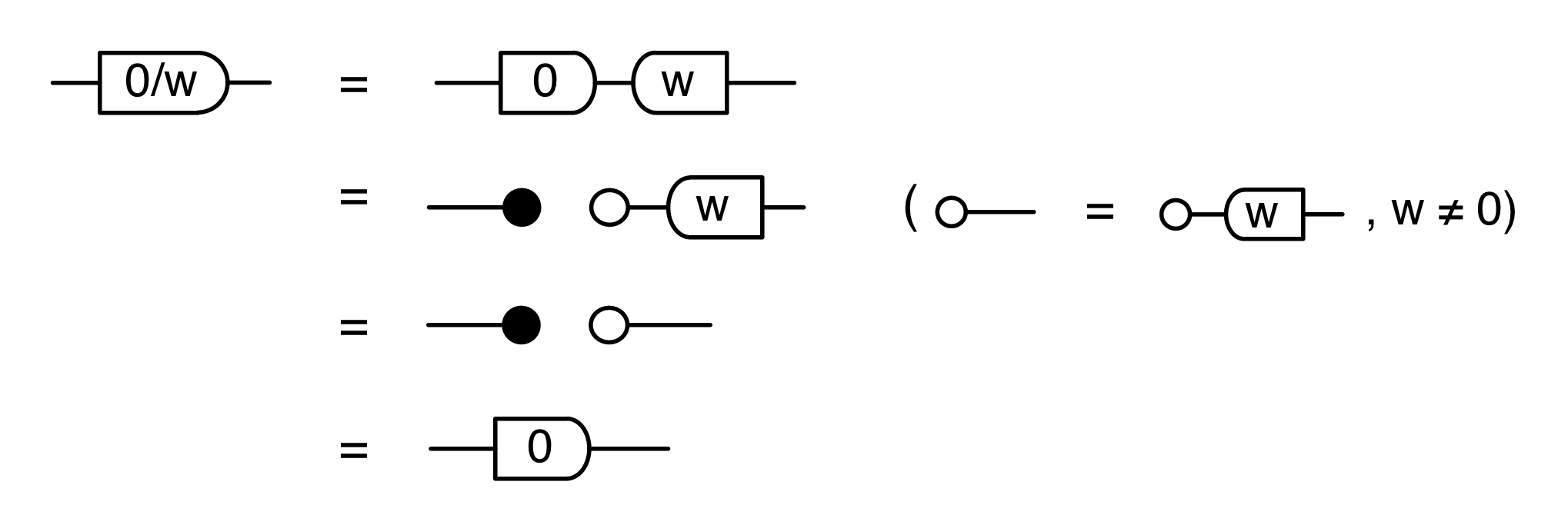
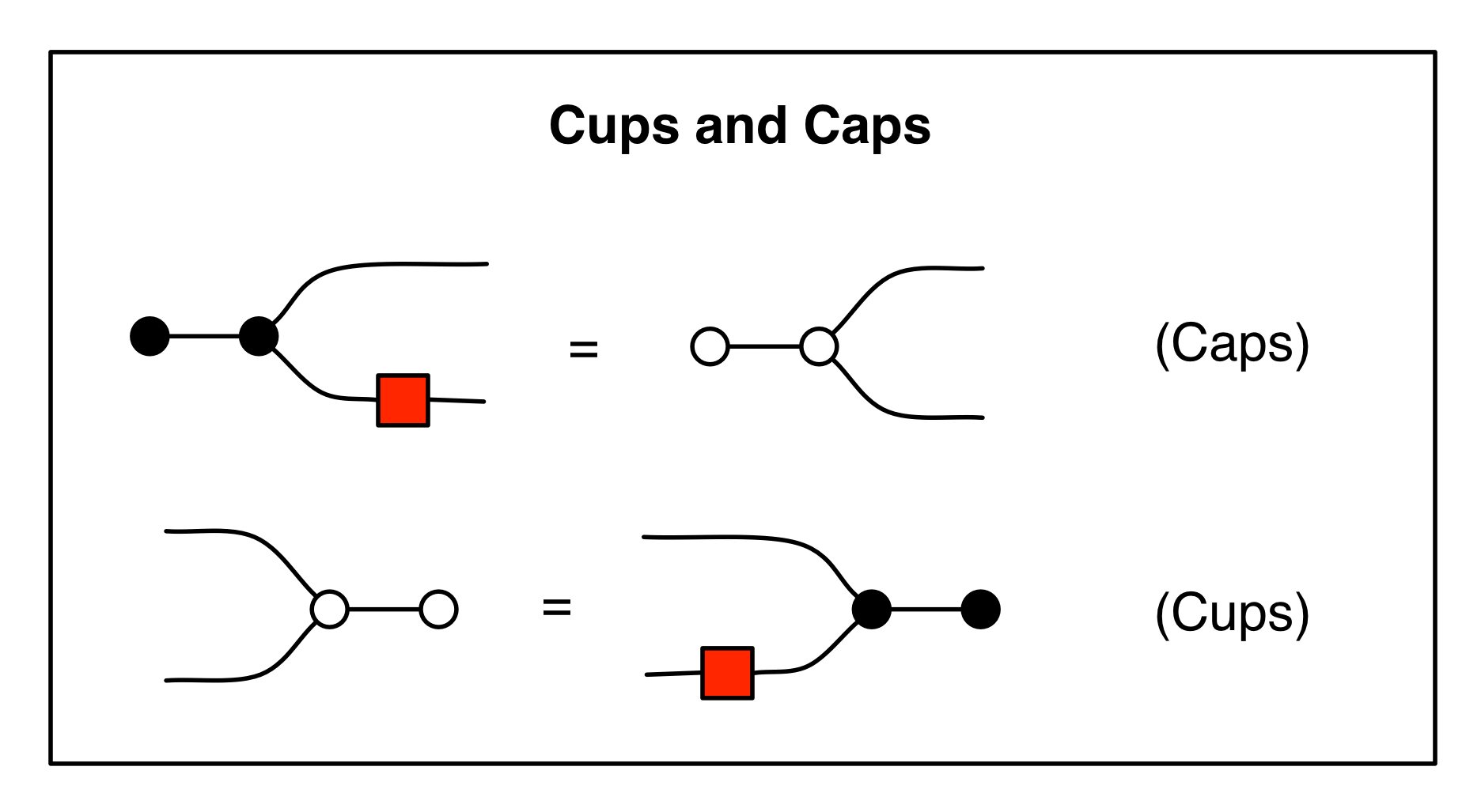
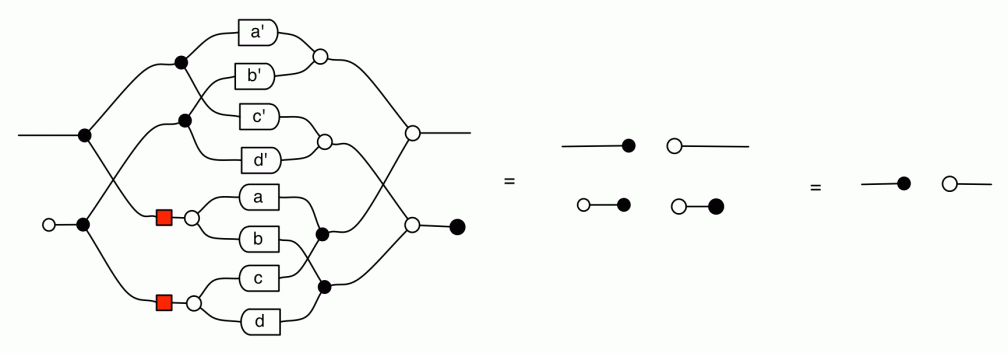 The second equality follows from the
The second equality follows from the 

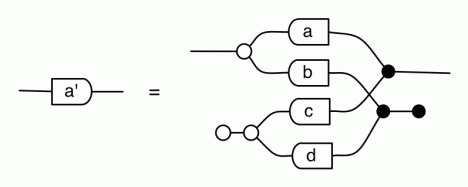



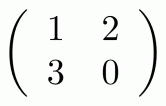
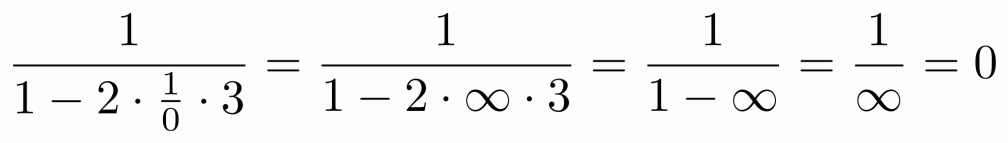


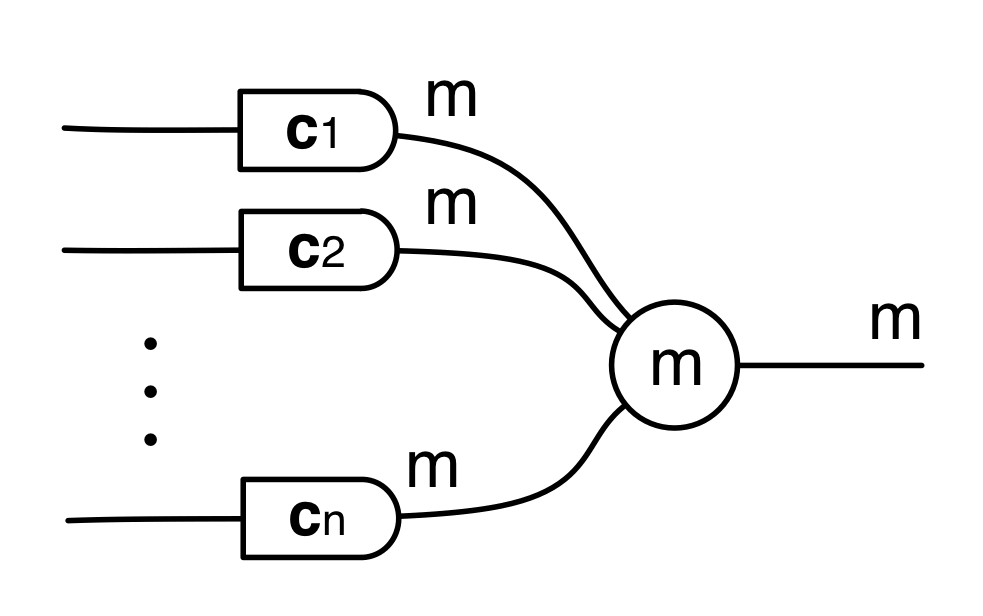




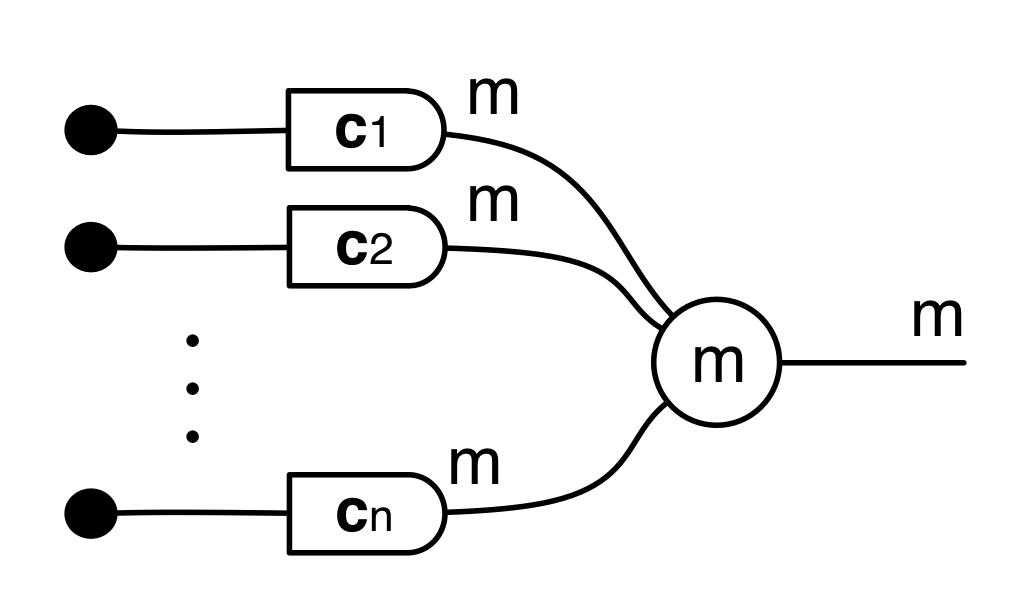




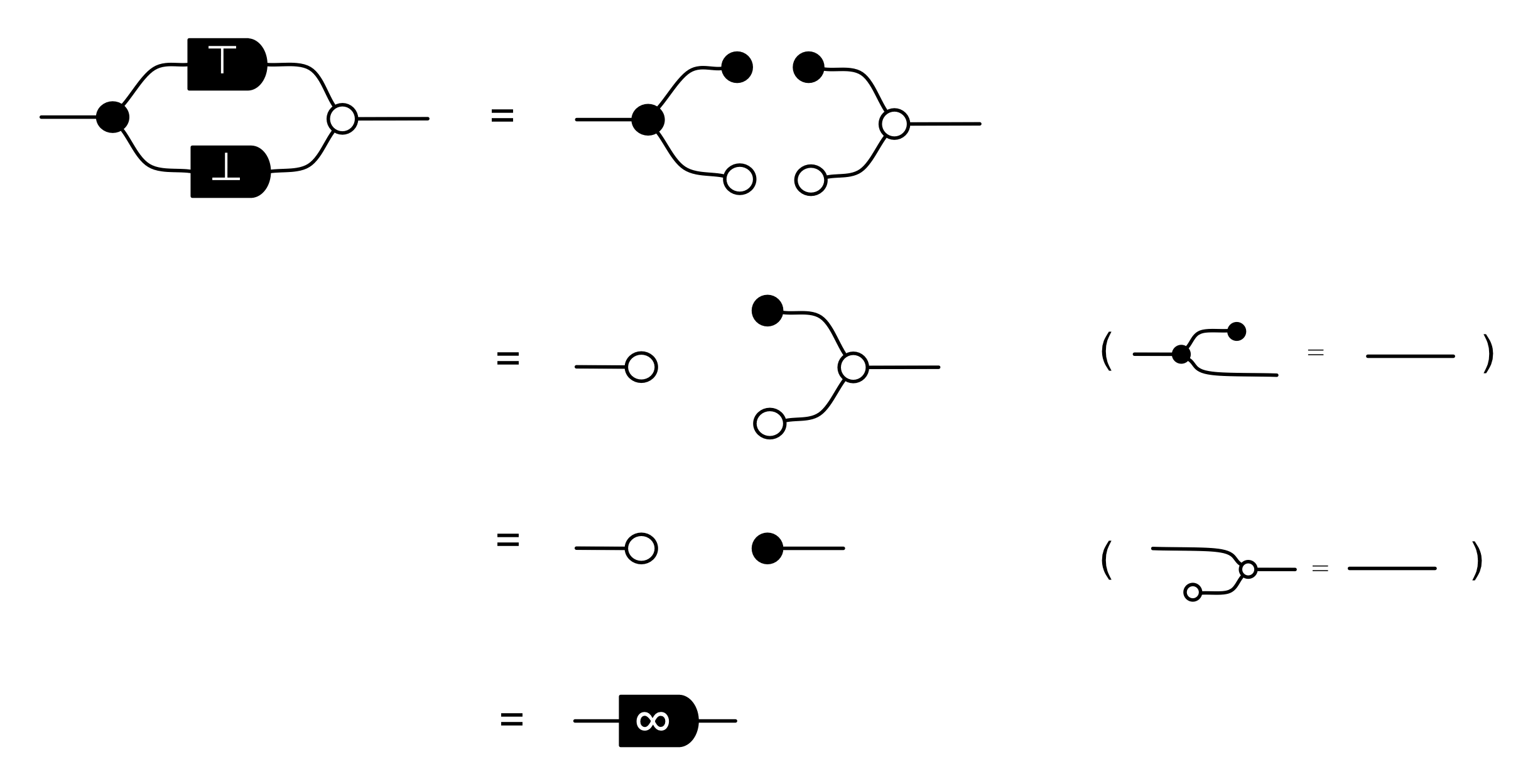
 The answer is that it’s a constraint: it only accepts
The answer is that it’s a constraint: it only accepts 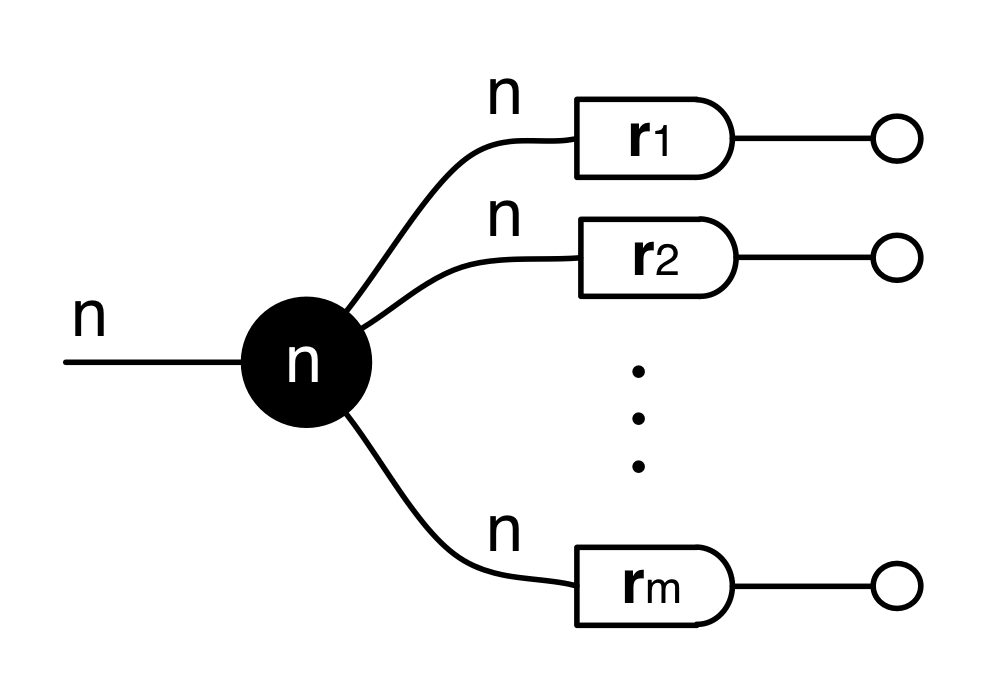







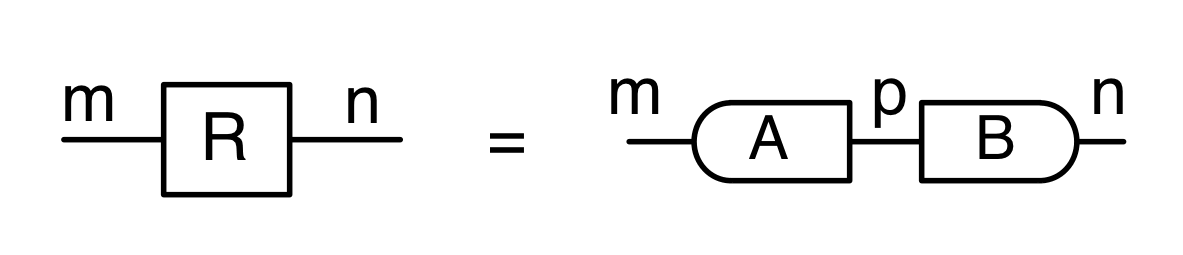





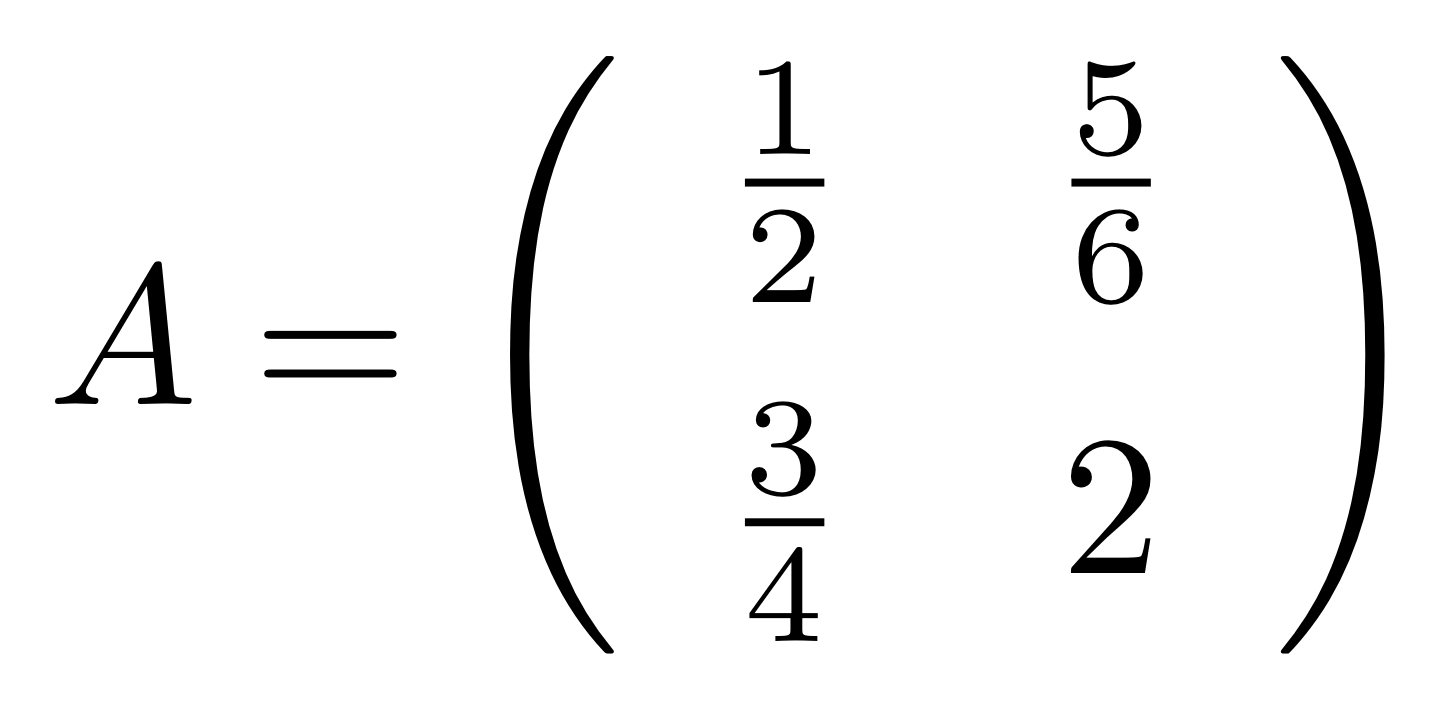
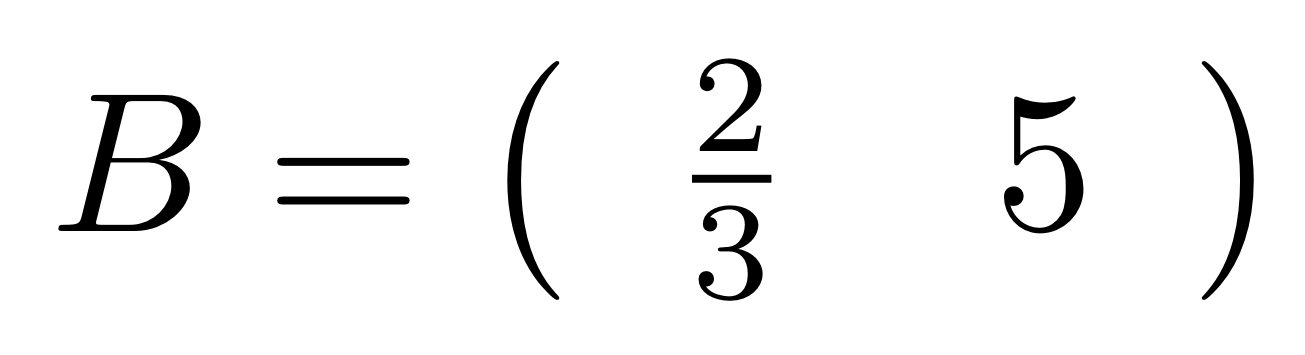
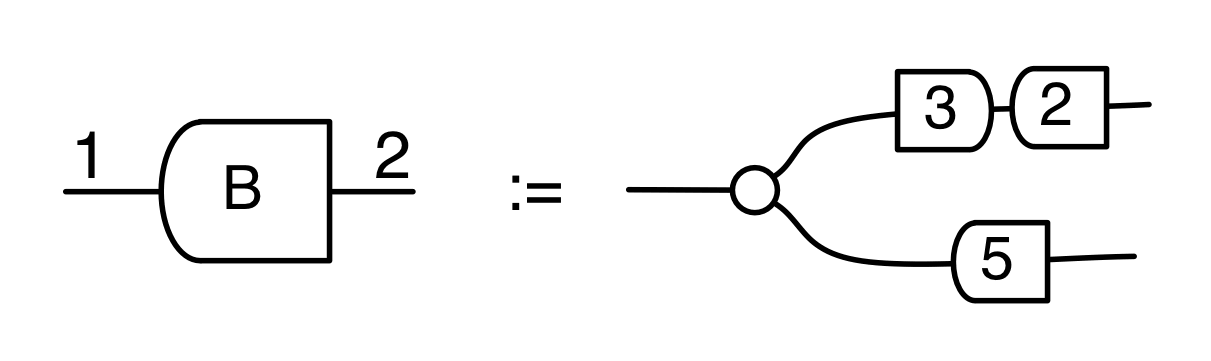

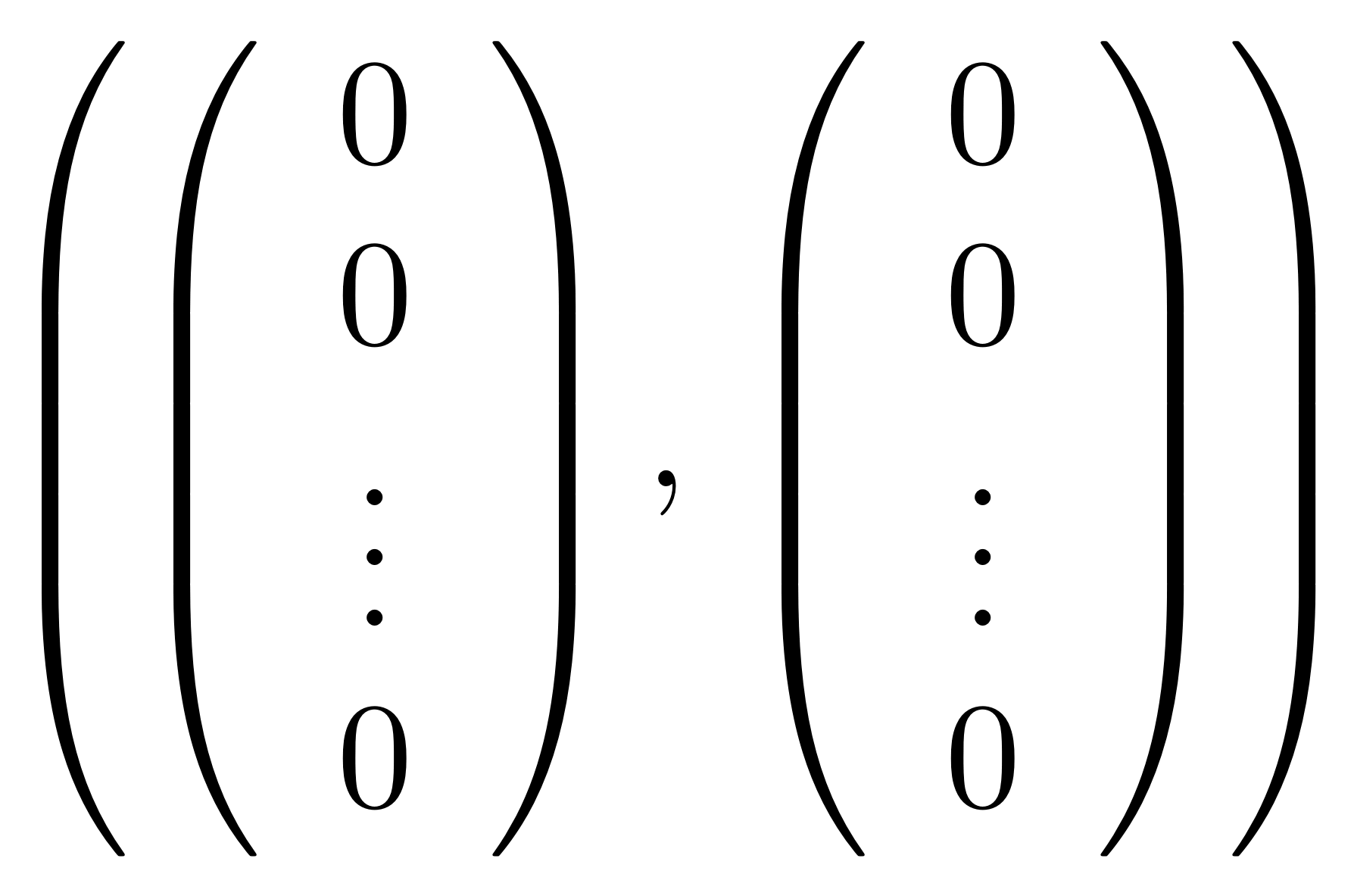
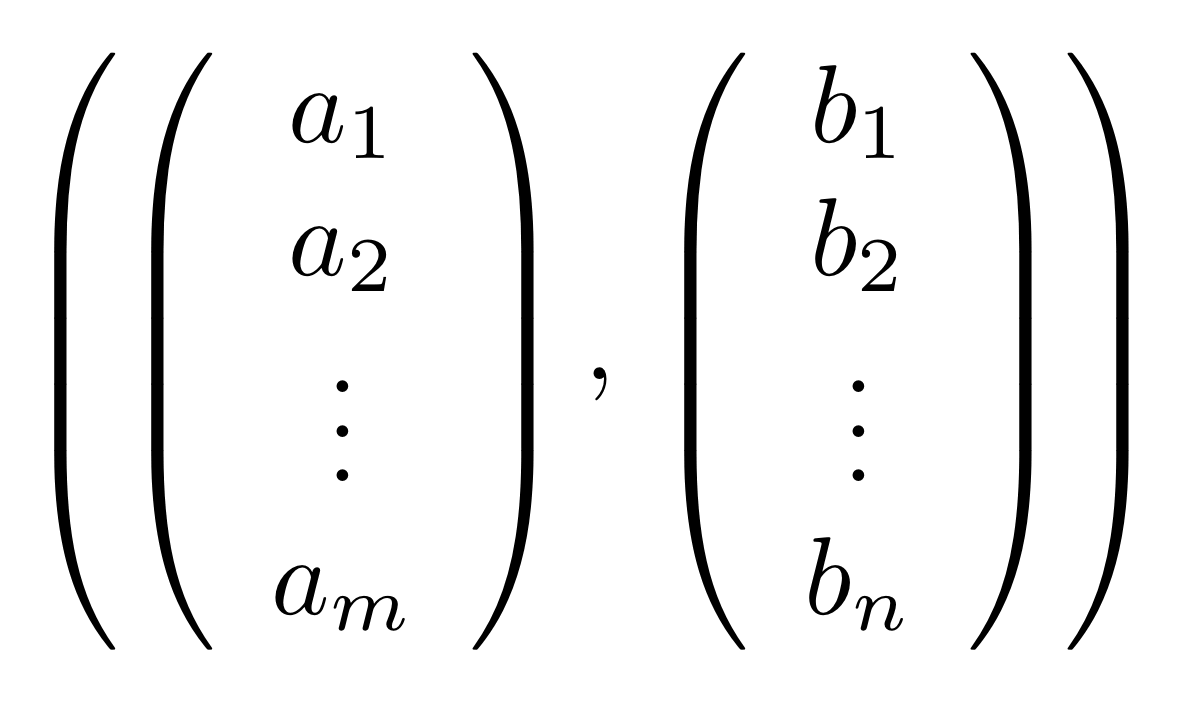
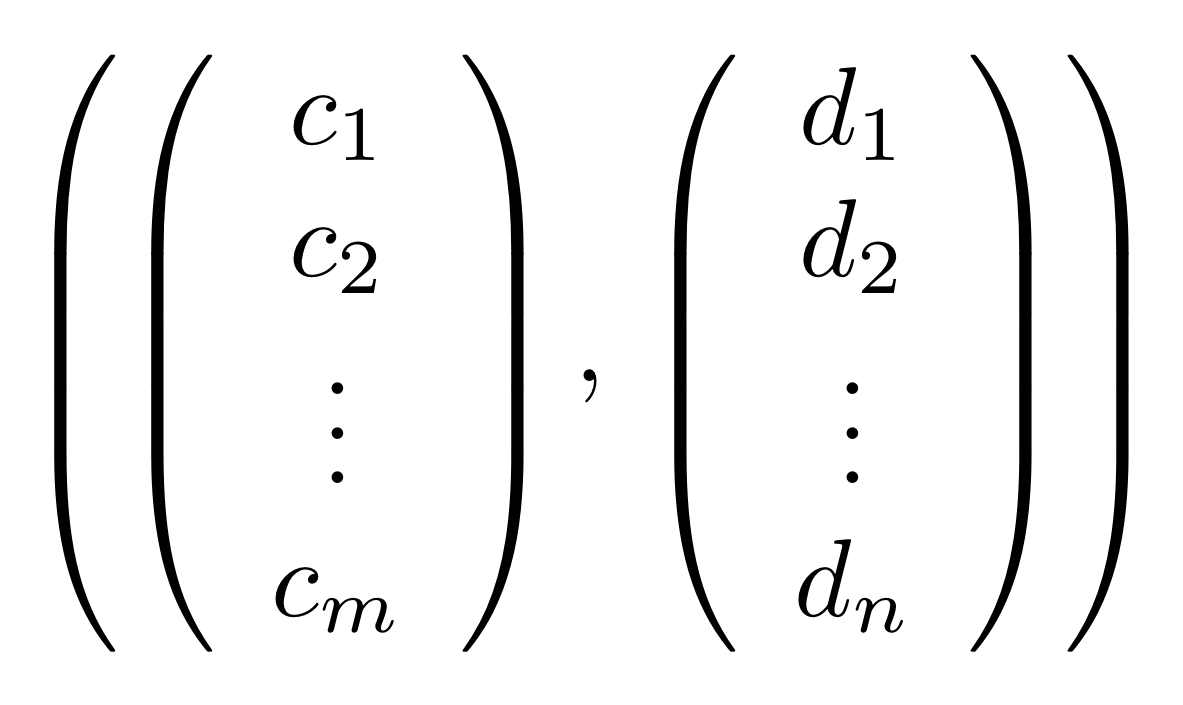
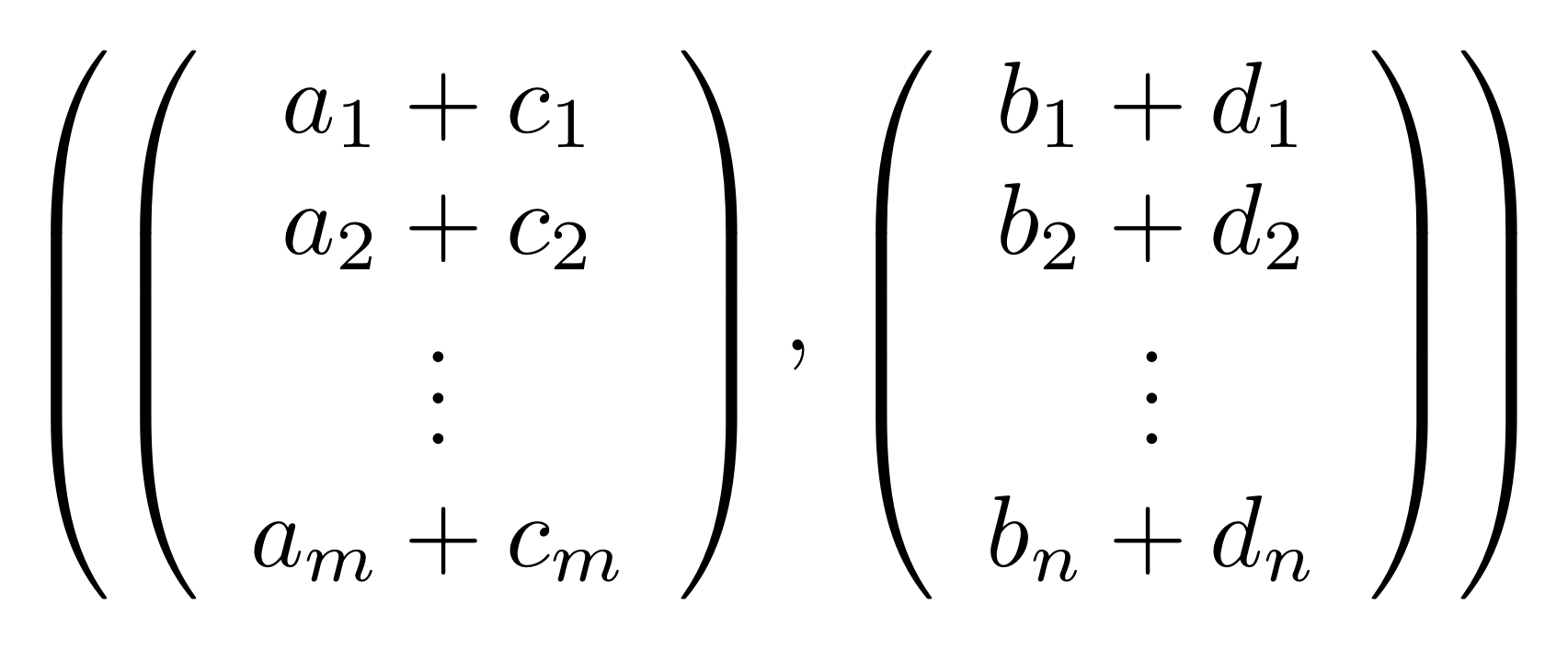
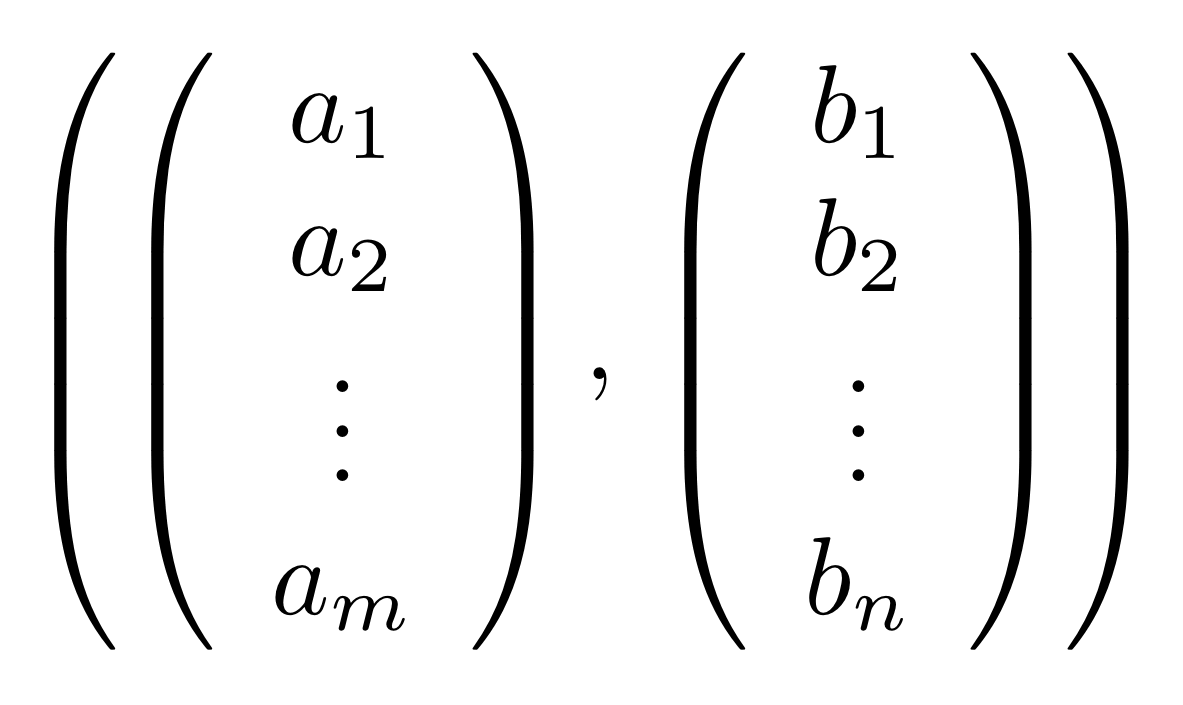









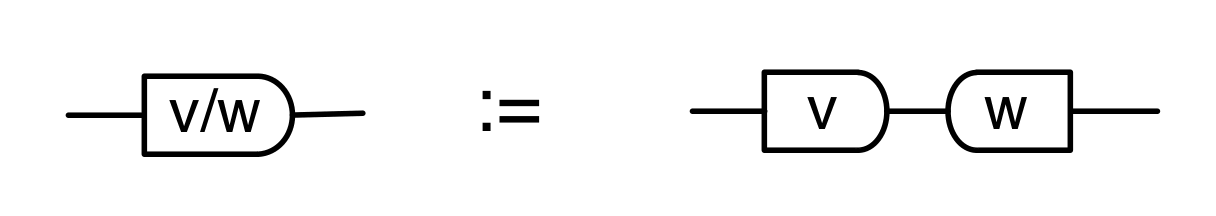



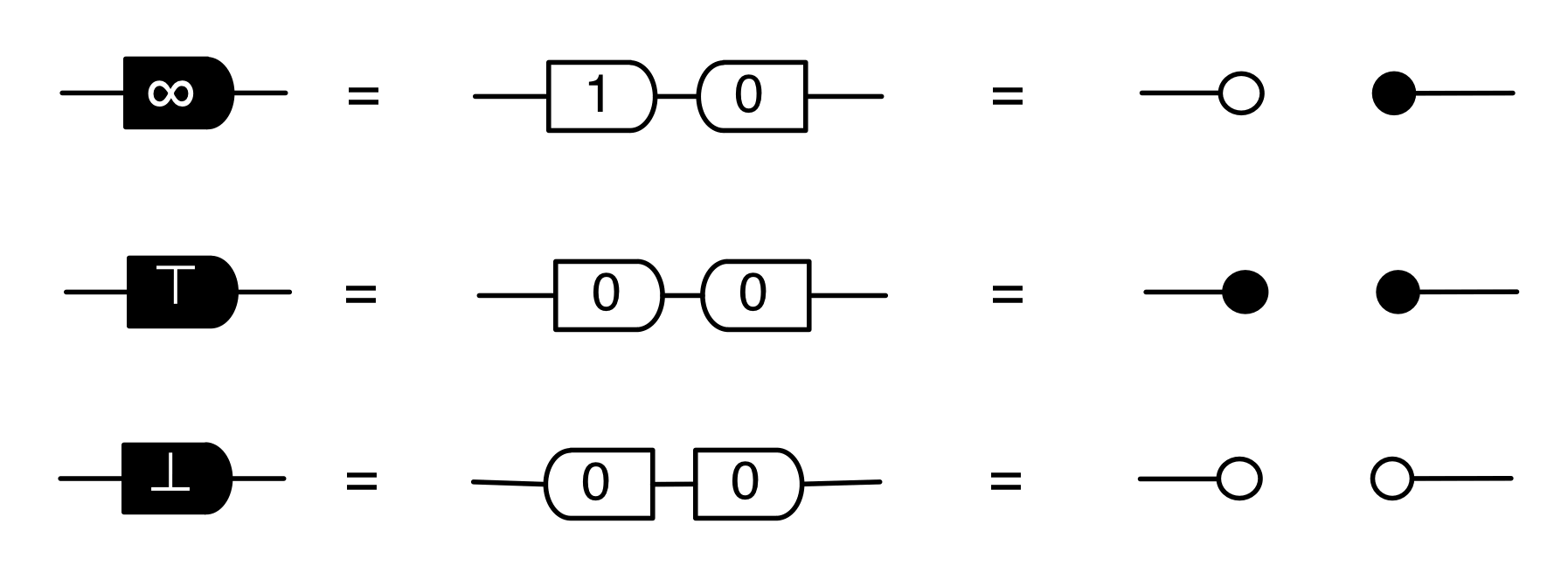




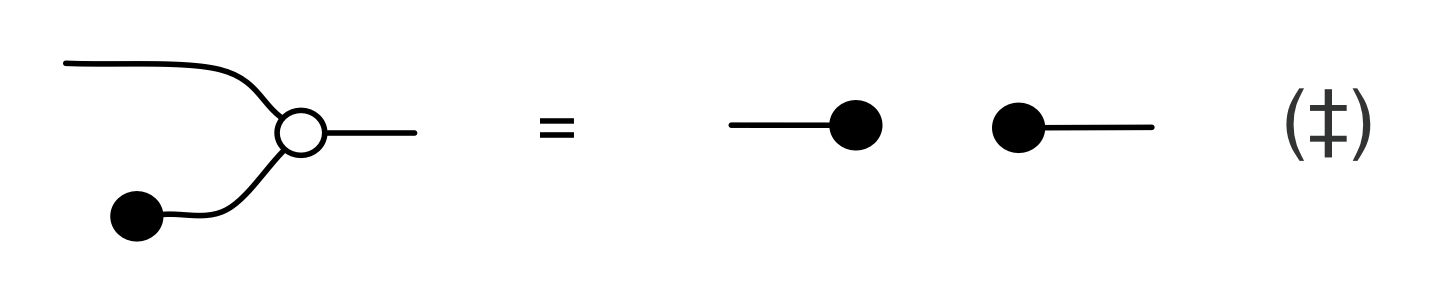

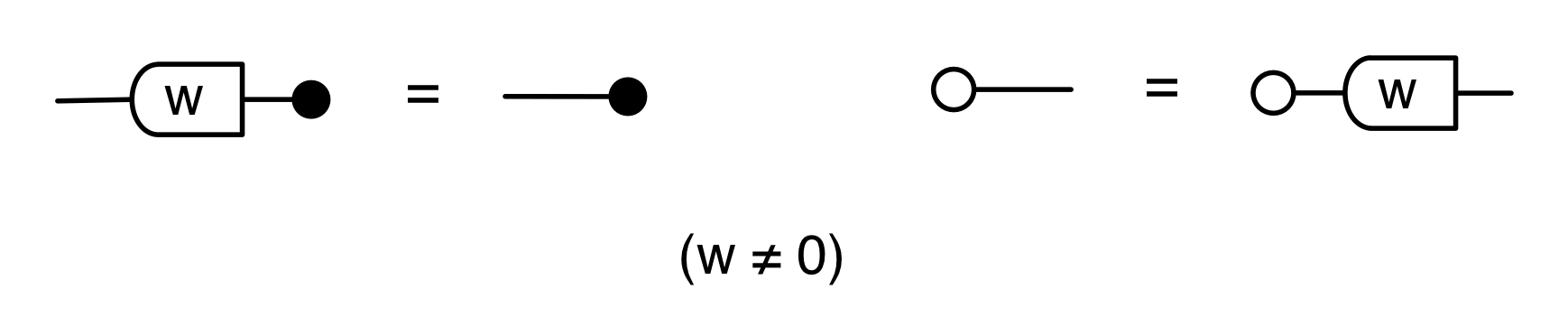





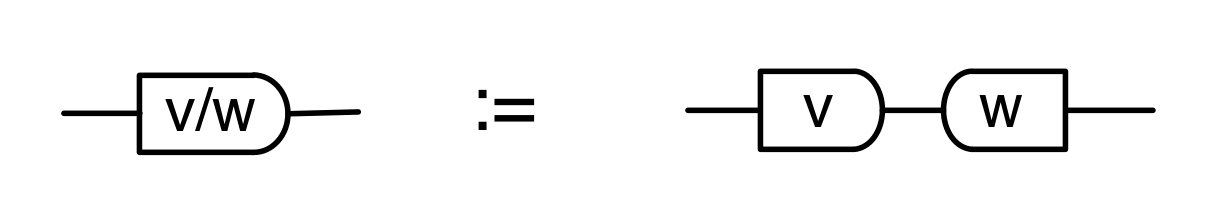





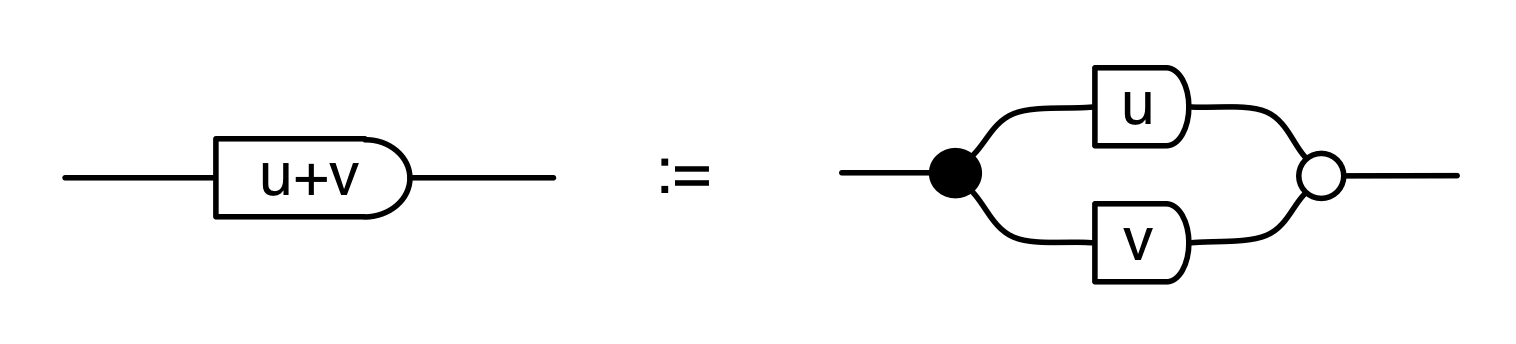






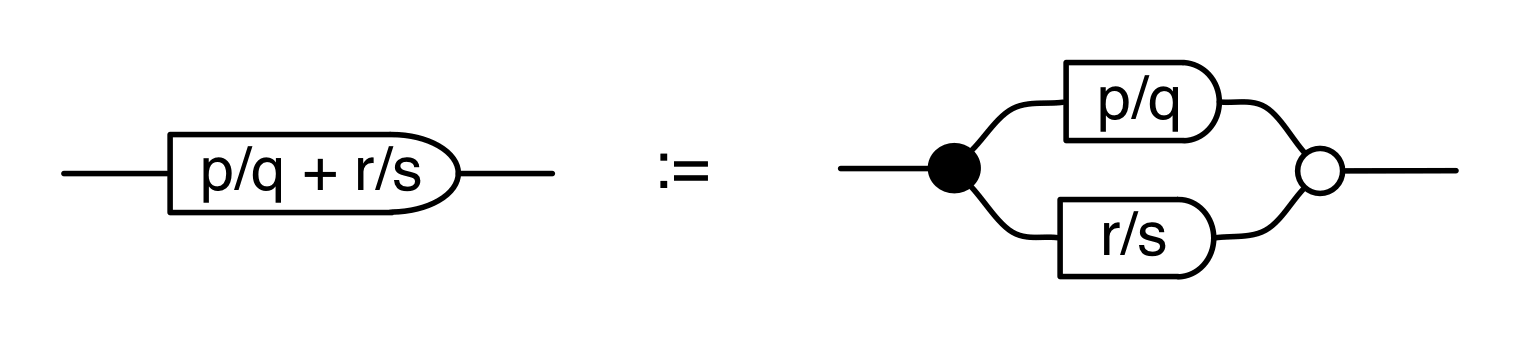

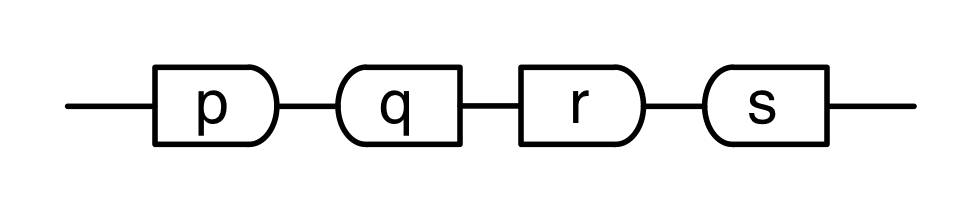

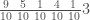 .
.
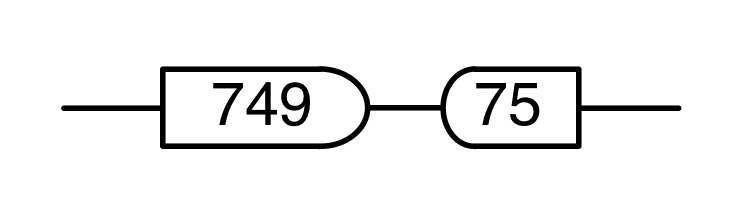


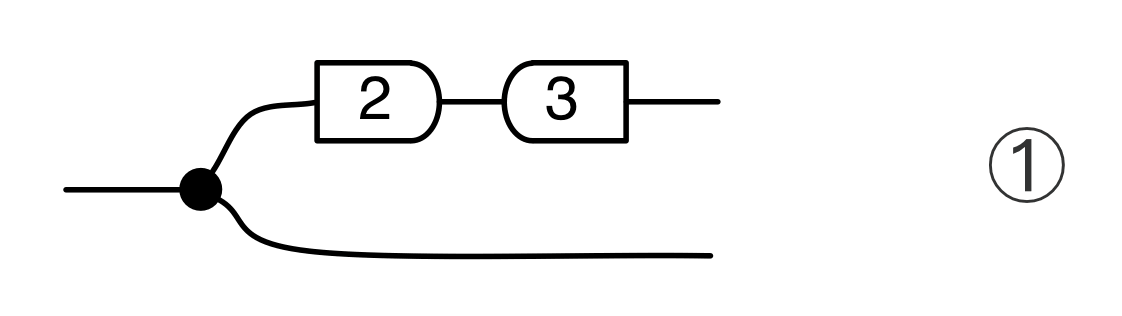
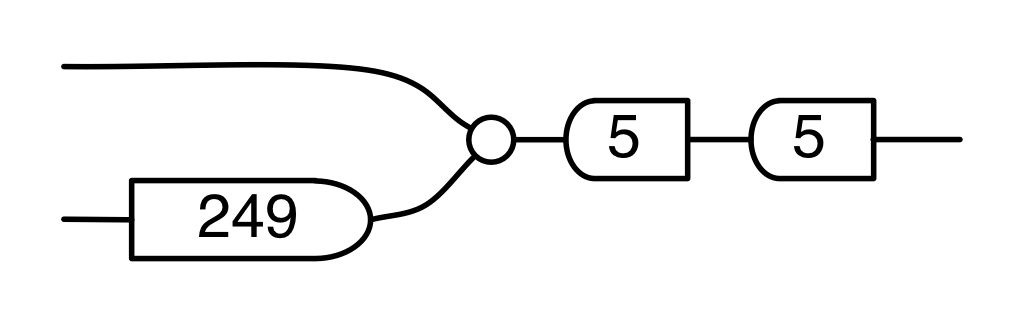




 , the
, the 


















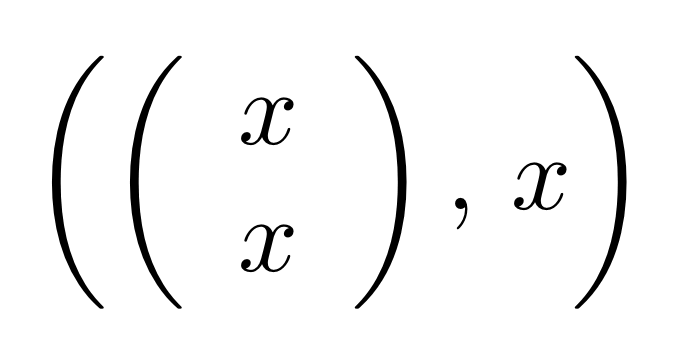










































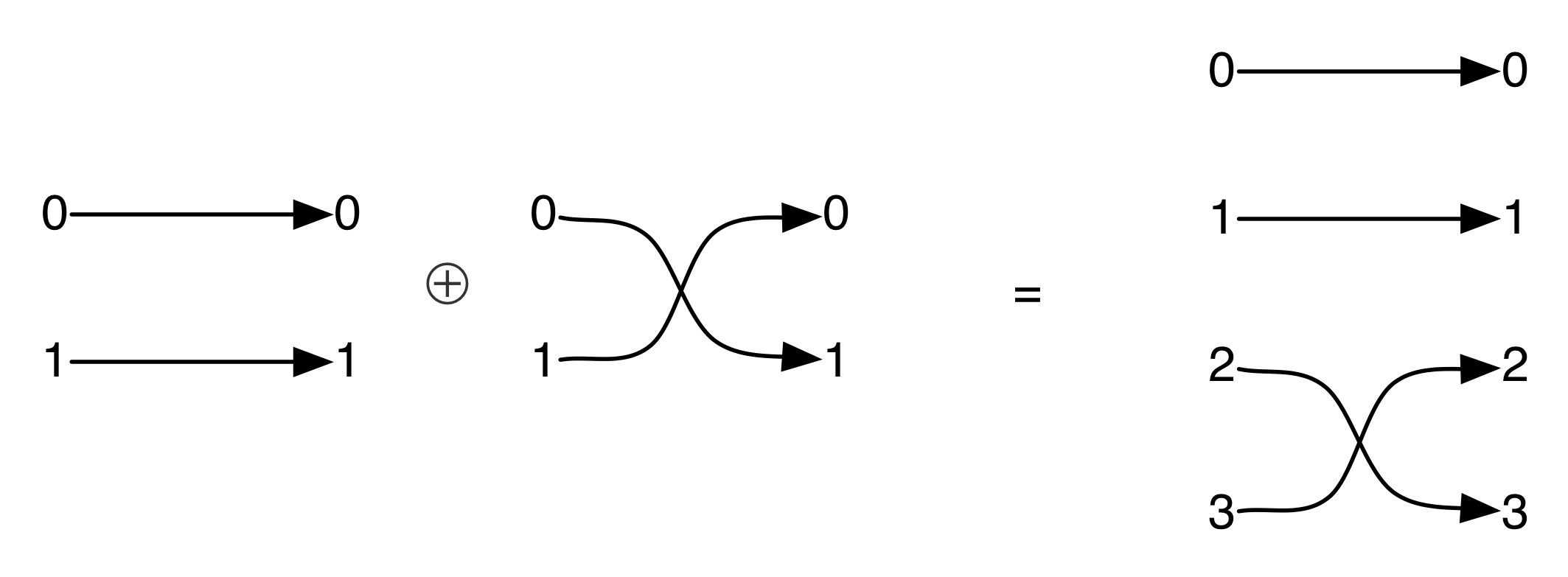
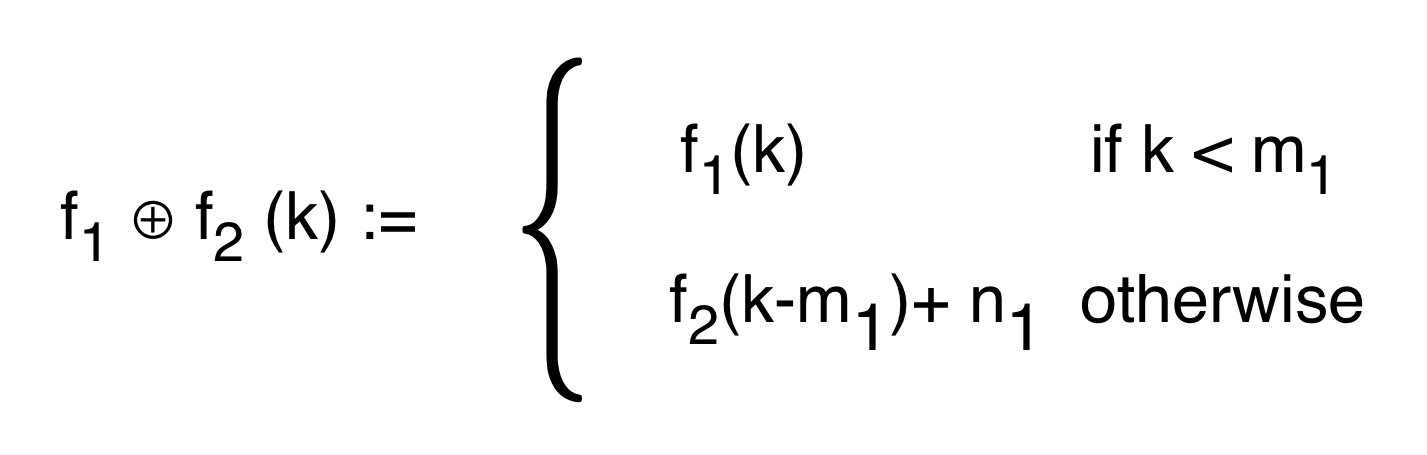
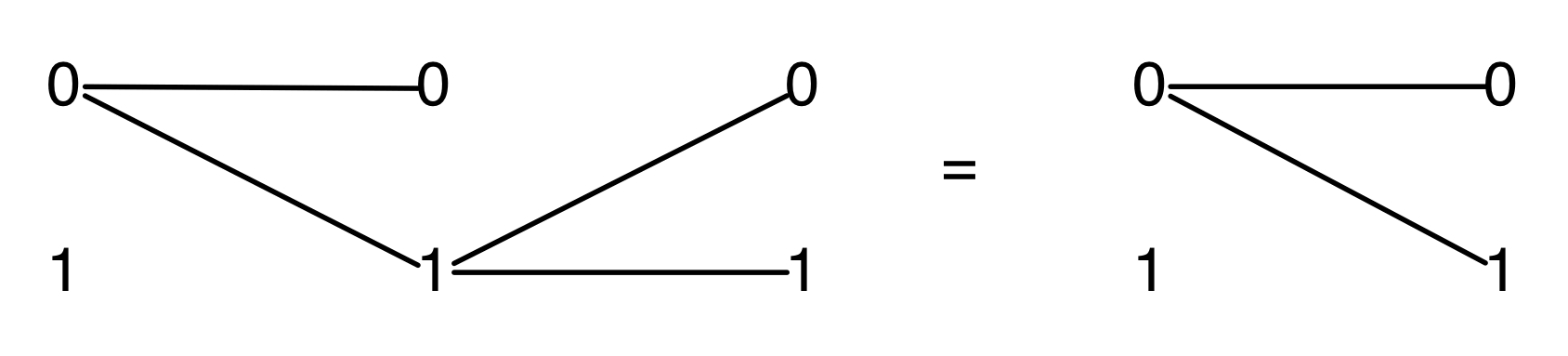
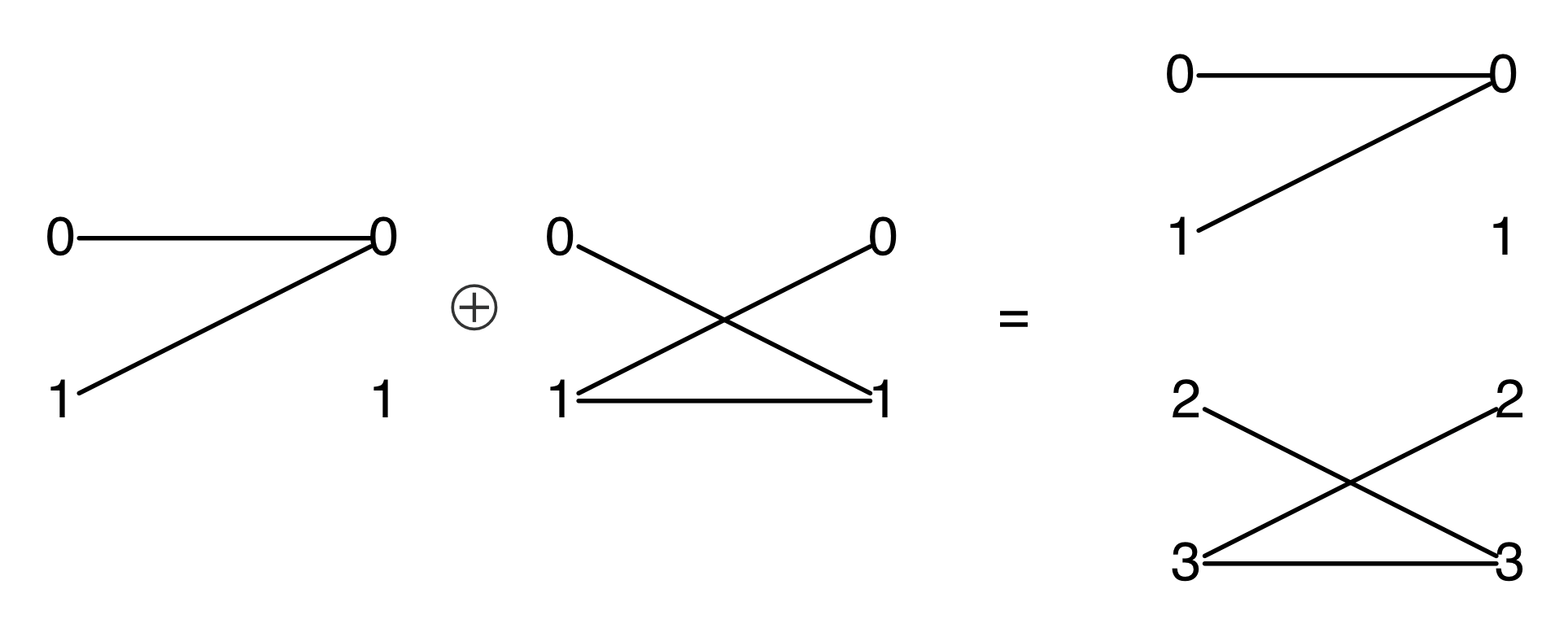


{kind=link}
{kind=link}
{kind=link}
{kind=link}
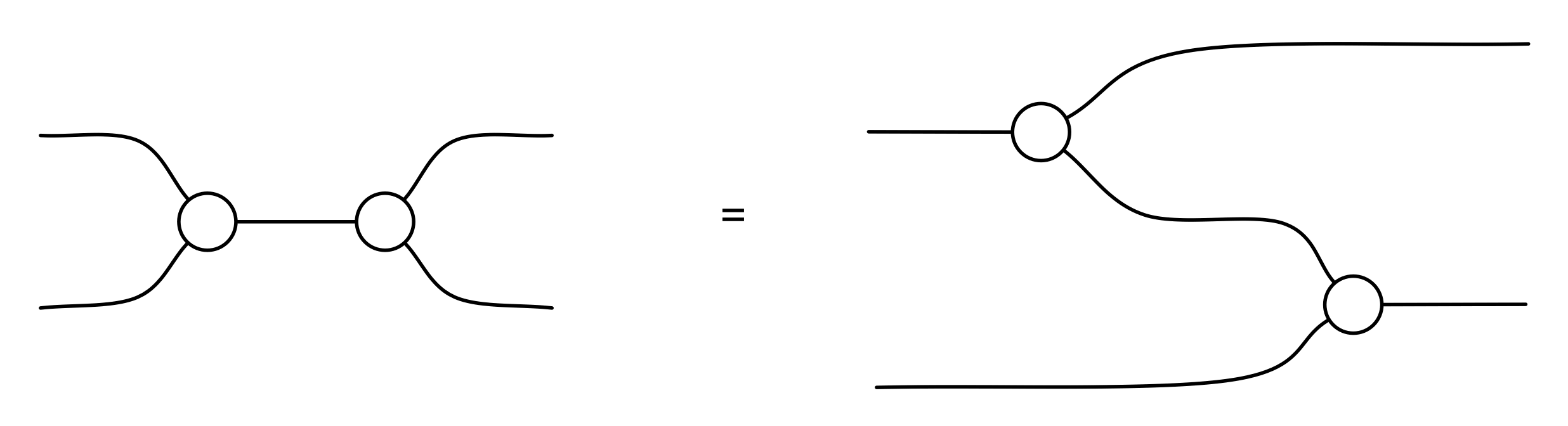{kind=link}
{kind=link}
{kind=link}