
This is an important episode in the story of graphical linear algebra. We return to our intuitions, the ones we started with all the way back in Episode 3. It’s high time we replace them with something much more useful.
In our diagrams so far, we have been saying that numbers travel on the wires from left to right. By the way, all along, we have been rather vague about what these numbers are exactly — and as we expanded our set of generators and their associated equations, we have been getting more specific. So far, we know at least that we have a zero (which is part of the addition structure) and negatives (the antipode).
Let’s call the type of these numbers, whatever they are, Num. Then the addition generator defines a function of type
Num × Num → Num

since there are two arguments x and y (the numbers that arrive on the input wires on the left) and one result x+y (the number that exists on the the output wire on the right). Similarly, we could write down the types for all of the other generators. And in our algebra of diagrams, the composition operation always connects outputs to inputs.
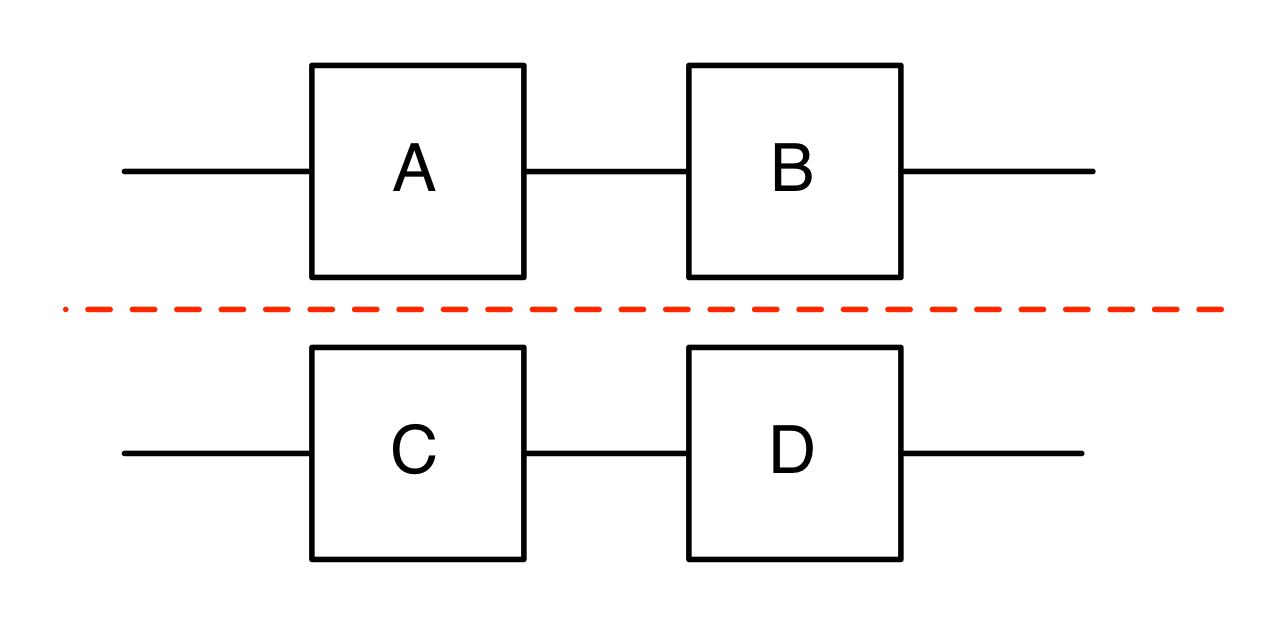
Every diagram thus defines a function that takes a certain number (possibly zero) of inputs to a number (possibly zero) of outputs. In other words, every diagram that we drew conforms to the following idealised—and pretty cliché—idea of a computational system. The picture below could appear in a million papers and talks in computer science and related fields.
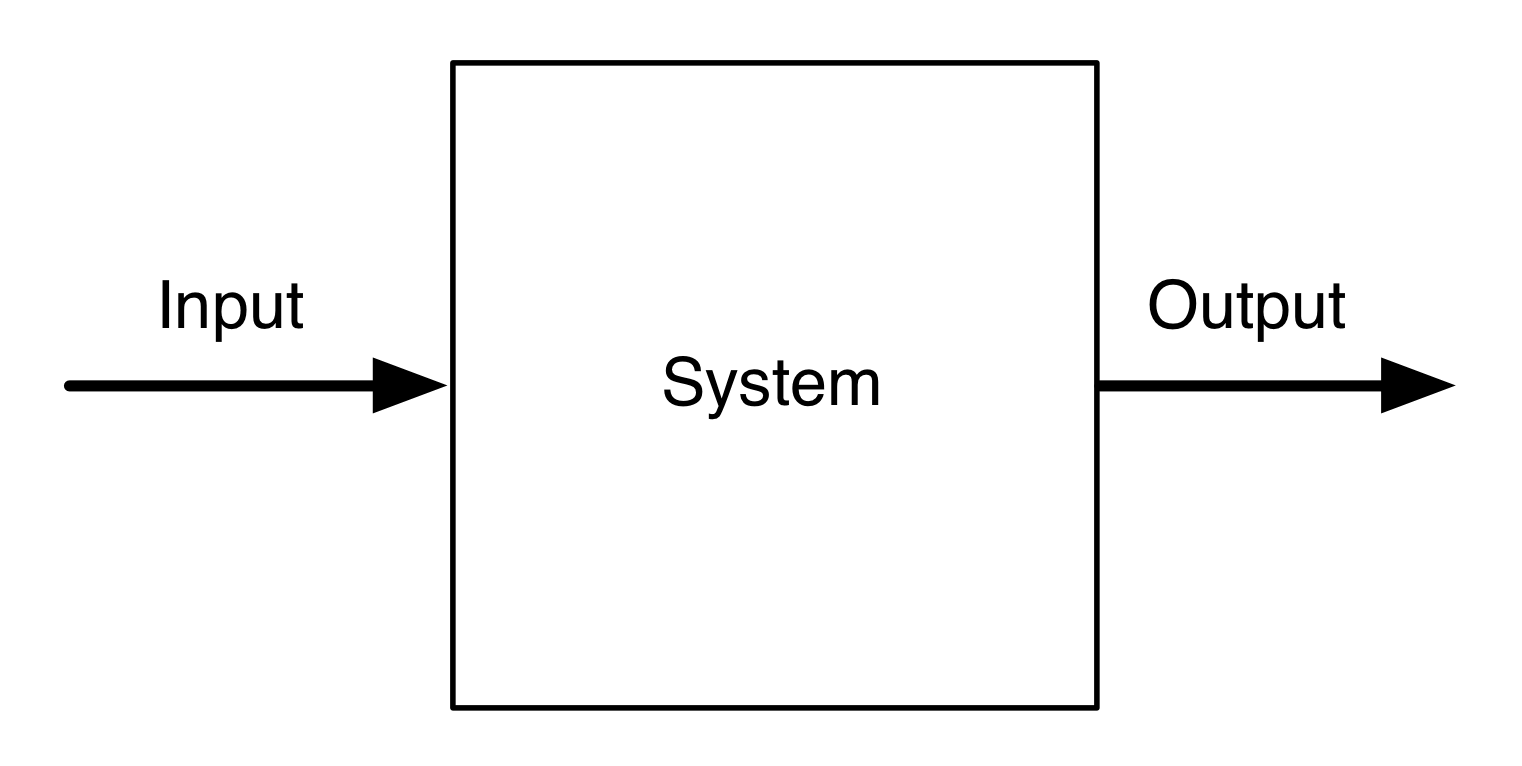
We could even go so far as to say that the inputs we provide are causing the outputs. Let’s not go down that road; it causes a lot of problems. Let me explain why.
(A warning: the rest of this episode is about 90% rant; if you just want the content, feel free to skip to the last section.)
Causality is an enchanting, seductive idea. Imagine: we interact with the world by giving it inputs, and the world responds by returning nice, easily predictable outputs. Life would just be so easy and pleasant if everything around us behaved as functions in the mathematical sense: for every input x there would be an output f(x). And, the cherry on top, imagine if f had a closed form. A nice little theory of everything.
Unfortunately, reality is somewhat more brutal. In 1912, the year the Titanic sunk, Bertrand Russell published a very nice philosophical paper entitled On the notion of cause. It is full of delightful quotes, and here is one of my favourites:
The law of causality, I believe, like much that passes muster among philosophers, is a relic of a bygone age, surviving like the monarchy, only because it is erroneously supposed to do no harm.
Clearly, Russell was a republican. But his paper is mainly a scathing attack on the facile idea of causality: viewing the various components of the physical world as cause-and-effect systems.
Of course, it is extremely useful to engineer systems that behave in a cause-and-effect manner: our carefully constructed civilisation relies on it. If you buy a car, you would not be very happy if nothing happened as you pressed the accelerator pedal. Similarly, a lamp should do something when you flick the switch. Clearly we are causing the car to go and the light to go on by interacting with those systems appropriately.
The problem arises when we try to use our fuzzy “common-sense” human intuitions of causality to understand the physical, non-manufactured world around us, or even the sub-components of engineered systems. Causal preconceptions affect the way we approach reality: to get the outputs we want, all we need to do is find the right inputs. When a person with this world view sees something happening, they ask why, what caused it? This question may seem quite reasonable at first.
Quoting Feynman:
Aunt Minnie is in a hospital. Why?
Because she went out, she slipped on the ice and broke her hip. That satisfies people.
If you haven’t seen it, go ahead and watch the video, it’s very entertaining. Feynman is addressing the difficulty of answering a question like “Why do magnets repel each other?”. One of the messages of the video is that it is difficult to apply “common-sense” to understand the physical world. In “common-sense” the questions “why?” and “what caused it?” are closely linked. And the idea of something causing something else, away from our carefully engineered human civilisation, becomes more flimsy the more one thinks about it.
But maybe this world view is harmless, like the monarchy? They (the monarchy) do bring in loads of tourists, after all. So maybe causal thinking gets us to ask the right questions, e.g. Newton and the Apple incident. What caused the apple to fall?
Not quite. Causality encourages sloppy thinking that is far from harmless: it is killing people, while costing billions in the process. If this sounds like an outrageous hyperbole, a cautionary tale is recounted in Jonah Lehrer’s article Trials and errors: Why science is failing us. Check it out, despite the clickbait title it’s worth a read. Full disclosure: Lehrer is an interesting guy. He seems to have been transported to life from a stock character in some Shakespearean play: first a stratospheric rise from science blogger to best-selling author with a cushy staff writer gig for the New Yorker. Then an equally steep fall from grace—apparently he faked some Bob Dylan quotes for one of his books—so spectacular that it merited two chapters in Jon Ronson’s So you’ve been publicly shamed. But let’s not throw out the baby with the bath water.
Lehrer writes that in the early 2000s, Pfizer, the multi-billion dollar pharmaceutical company, pumped a lot of money into the development of a drug called torcetrapib, which tweaked the cholesterol pathway—one of the most studied and seemingly well-understood systems in the human body—to increase the concentration of HDL (“good cholesterol”) at the expense of LDL (“bad cholesterol”). Here’s a diagram.
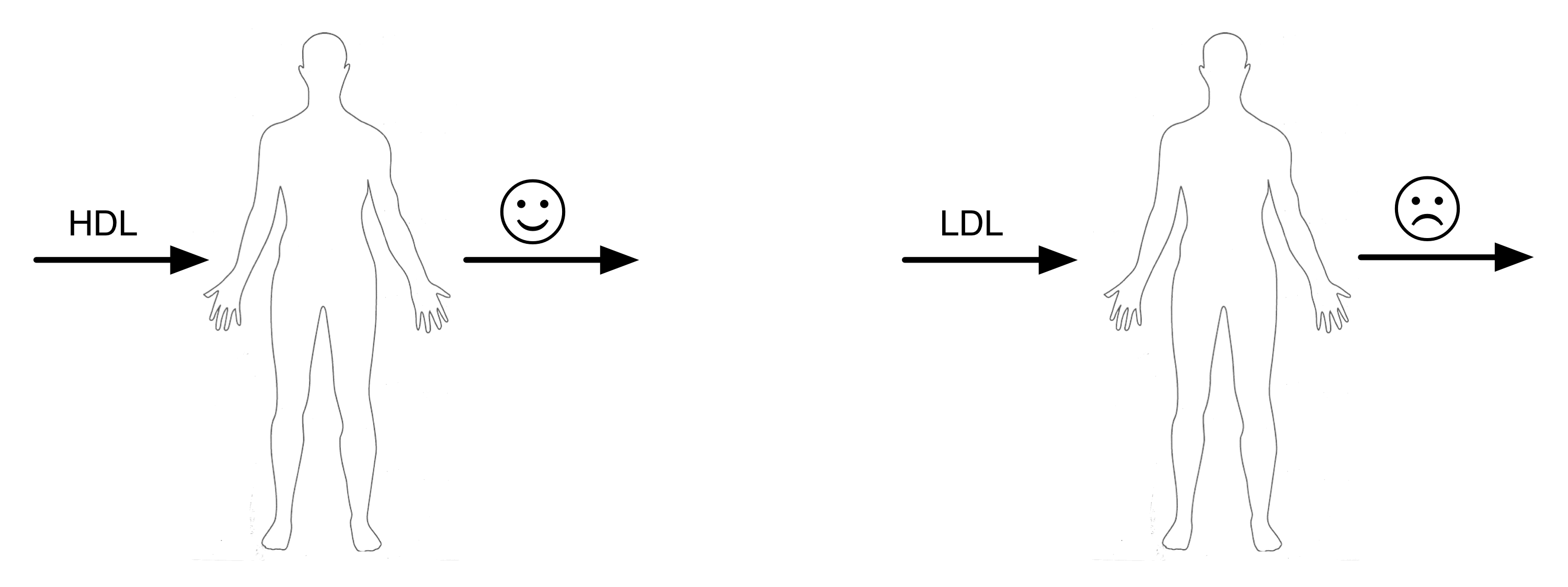
It actually did exactly that; increased HDL and decreased LDL. But there seems to be a deeper problem concerning the diagram above: the simplification involved in considering some chemical as a “good input” and another as a “bad input”. Long story short, quoting Lehrer:
Although the compound was supposed to prevent heart disease, it was actually triggering higher rates of chest pain and heart failure and a 60 per cent increase in overall mortality. The drug appeared to be killing people. That week, Pfizer’s value plummeted by $21 billion (£14 billion)
It’s pleasant and probably quite lucrative—research grant wise— to call HDL “good” and LDL “bad”. It seems likely, however, that they are not inputs in any useful sense; they are components of a complex system, the cholesterol pathway, which is part of a larger, more complex system, the human body.
Causal thinking and complex physical systems don’t mix very well. Still, the causality meme is as strong as ever, more than 100 years after Russell’s paper. A wonder drug (input) that cures cancer (output) is just around the corner. But you need to donate now.
So what is it about complex systems that makes them so difficult for humans to understand? Why is it that HDL or LDL might not be inputs in any meaningful sense? And what does all of this have to do with graphical linear algebra?
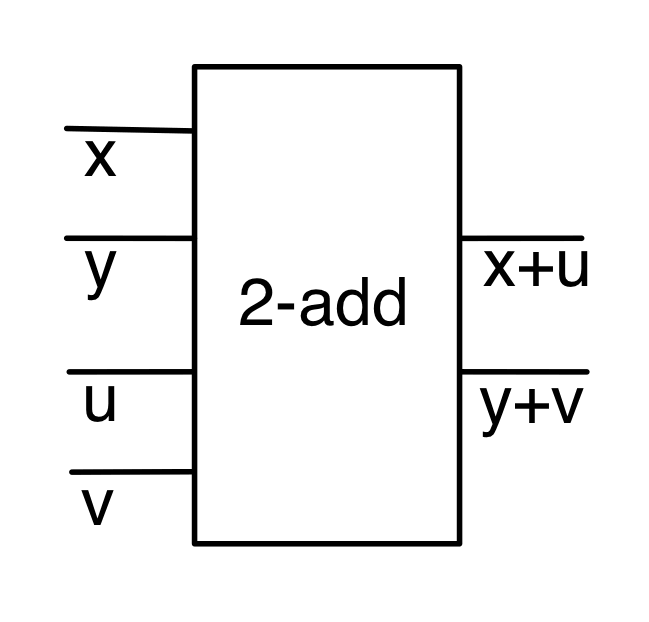
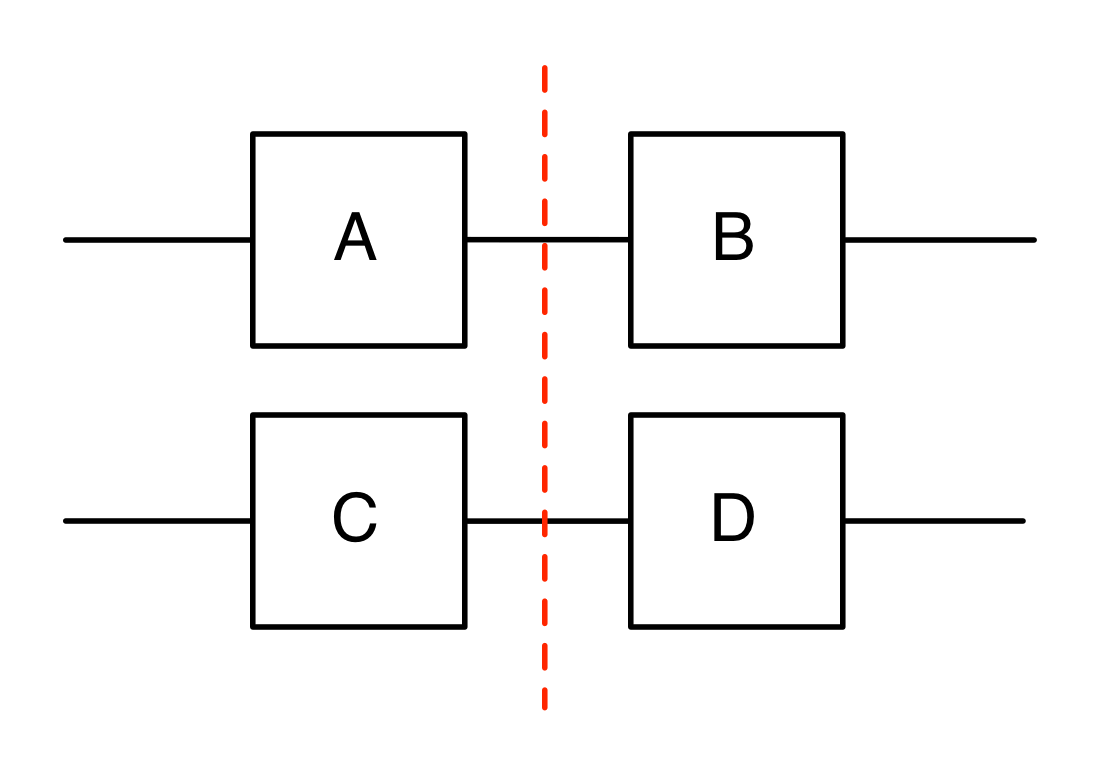
One of the most famous, the most studied, and yet the most mysterious features of complex systems is feedback: the somewhat circular idea that an output of a system can be plugged back in as an input. So, suppose that we have a nice, easy causal system with two inputs and three ouputs, as follows.
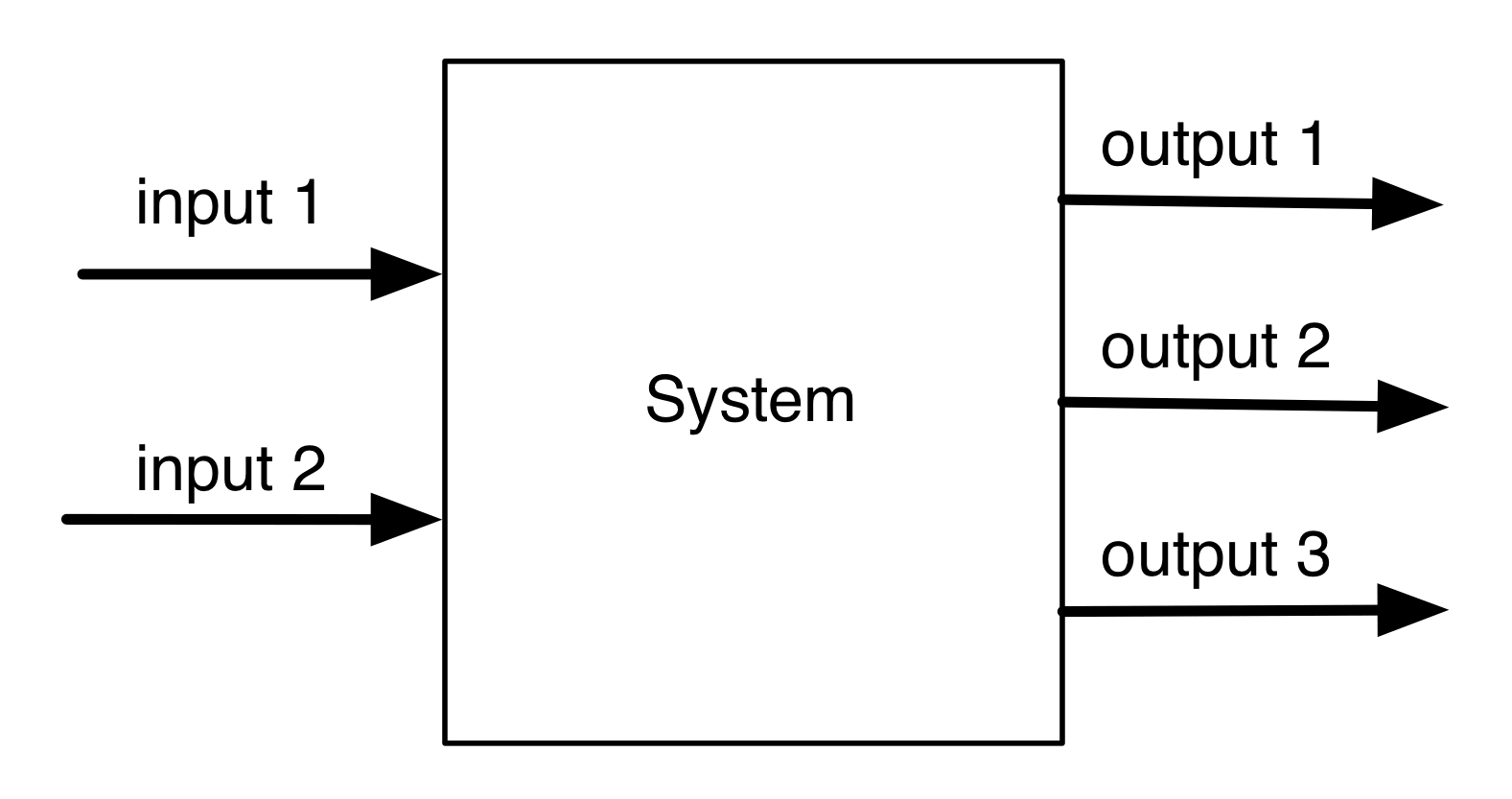
Now, what happens if I plug the first output in as the first input? I get the following system which now seems to have only one input and two outputs.
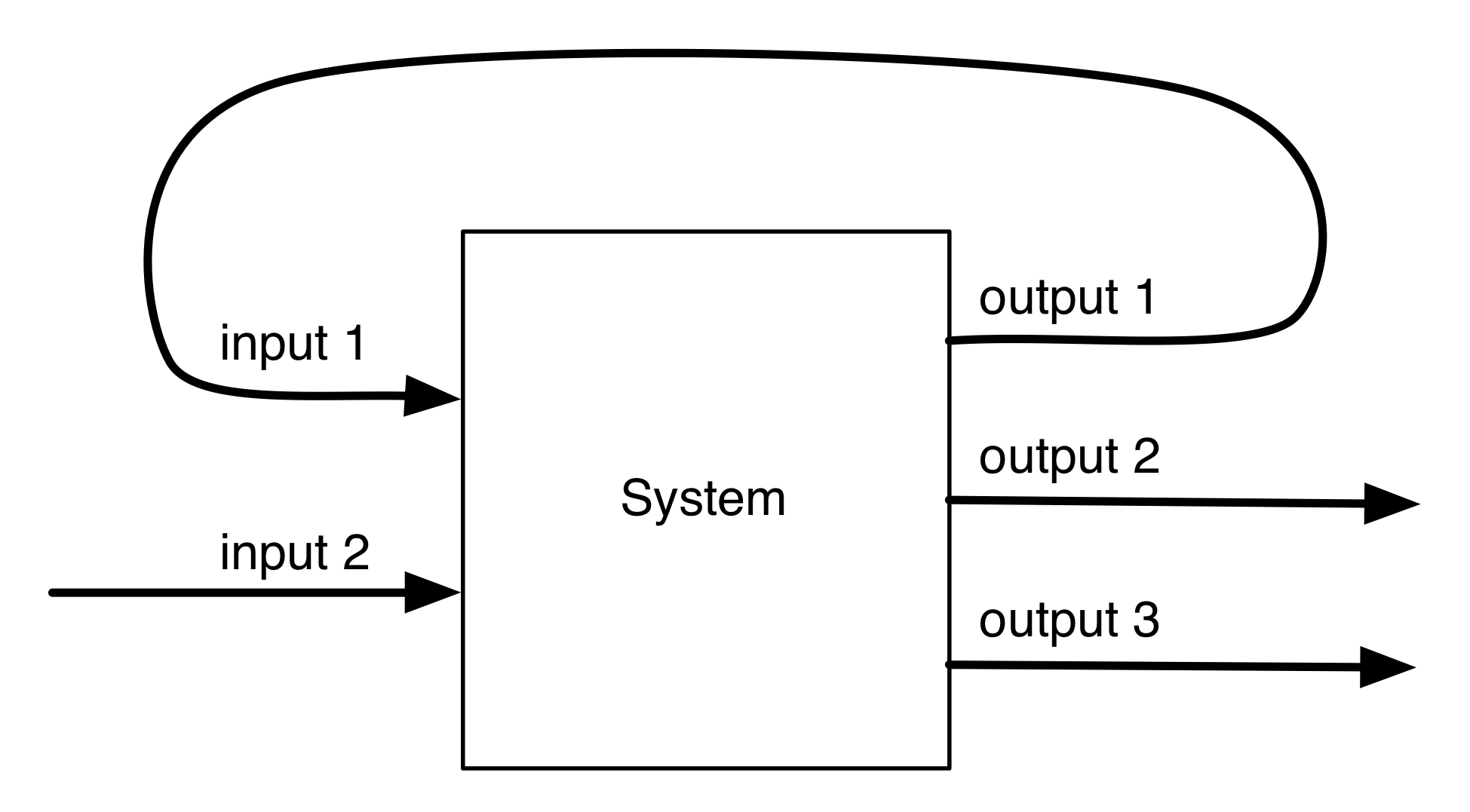
The idea of recursion, which we have seen in many of our syntactic sugars, is related and similarly circular: we used the sugar within its definition. It maybe made your head spin at first, but as long as one is careful, recursion is extremely useful. Similarly with feedback; and nature has figured this out. Many physical systems have feedback loops of some kind. Cholesterol—surprise!—is regulated by a feedback process.
Look again at the diagram above: three out of the four wires seem to be straightforward; they are either inputs or outputs. But what is the status of the feedback wire: is it an input or an output? What about the data that passes along it, numbers, bits, cholesterol, force, charge, whatever? Is that data an input or an output? This is one place where the input/output causal analysis begins to fall apart.
So how did we create our causal civilisation, with cars, trains and lamps, from a non causal physical world? Of course, this is where engineering comes in, and at the science end of engineering it is the topic of an entire field of study, control theory.
Control theory has undergone a little anti-causality revolution in the last thirty years or so, with the emergence of a subfield called the the behavioural approach. Its visionary creator, Jan C. Willems, wrote a bunch of fantastic papers on the subject. A good one to start with is The Behavioral Approach to Open and Interconnected Systems. Willems is immensely quotable, and here’s one quote from that paper:
It is remarkable that the idea of viewing a system in terms of inputs and outputs, in terms of cause and effect, kept its central place in systems and control theory throughout the 20th century. Input/output thinking is not an appropriate starting point in a field that has modeling of physical systems as one of its main concerns.
I would go so far as to claim that graphical linear algebra is the behavioural approach applied to linear algebra. We will discuss what I mean by this, as well as some of the contributions of Willems and the behavioural approach in future posts on the blog. The connections with control theory will become especially apparent when we will use graphical linear algebra to explain the behaviour of signal flow graphs; a formalism used in the study of time-invariant linear dynamical systems.
I just want to address one last point before we get to the content. Why does a guy whose job it is to understand input/output systems rail against inputs, outputs and causality? Isn’t this a little bit like a car manufacturer advertising the merits of bicycles?
Not quite: and the hint is in the quote. What Willems doesn’t like is taking inputs and outputs as the starting point. In more mathematical slang: Willems doesn’t want inputs and outputs as definitions, as assumptions that we make about physical systems, because they are a dangerous fiction—the real world simply doesn’t pander to our sociological, evolutionary hang-ups. Inputs and outputs are more like theorems, they exist because we carefully craft systems so that some variables behave as we would expect inputs or outputs to behave.
Let’s go back to our intuitions, with a view to getting rid of our functional hang-ups.
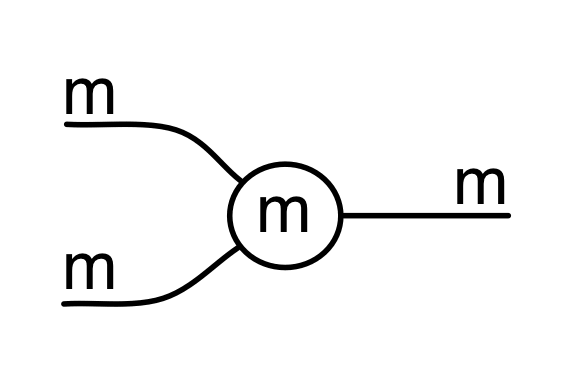
It’s actually pretty simple: instead of thinking of our addition generator as a function of type Num × Num → Num we will view it as a relation of type Num × Num ⇸ Num.
If you have not seen relations before, I will briefly explain the basics in the next episode. And we will start to see what the change in perspective in allows us to do. For now, just a brief taste.
By moving from functions to relations we are no longer thinking of the gadget above as taking two inputs to an output; we are thinking of it as determining a kind of contract: the only behaviours allowed by the addition generator are situations where numbers x and y appear on the left and x + y appears on the right.
This means that we loosen the causal associations: we can no longer simply say that the two numbers on the left are inputs and the number on the right is an output.

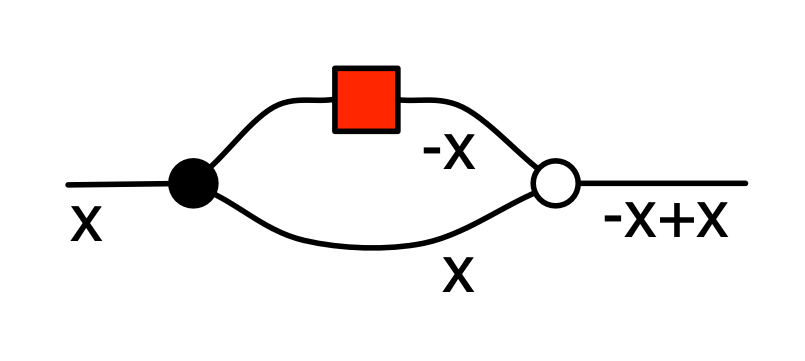
In fact, for the addition generator, if I know the values on any two wires I can figure out the value on the third. For example, if the value on the first left wire is 2 and the value on the right wire is 1 then I can figure out from the contract that the value on the second left wire is -1, since 2 + -1=1. So we can quite reasonably also consider the first left wire and the right wire as inputs and the second left wire as an output.
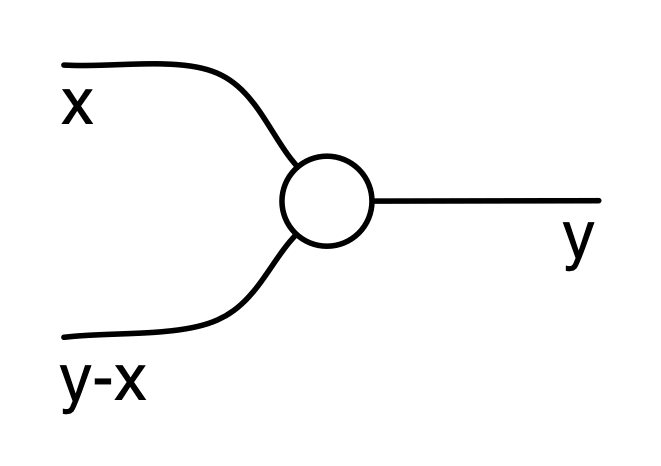
But instead of tying ourselves up in knots, it is just better to just stop using the words inputs and outputs for now. We will come back to them only when they become useful.
I gave a tutorial on graphical linear algebra at QPL ’15 two weeks ago. I just about managed to finish the slides on time! If you want a preview of what’s coming up on the blog you can take a look here. The videos of my talks will be released on the Oxford Quantum Group youtube channel; the ones that are there currently cut off after 1 hour, but this will be fixed soon.
I’m also going holidays starting next week, so the next episode will likely arrive sometime in early September.
Continue reading with Episode 21 – Functions and relations, diagrammatically







































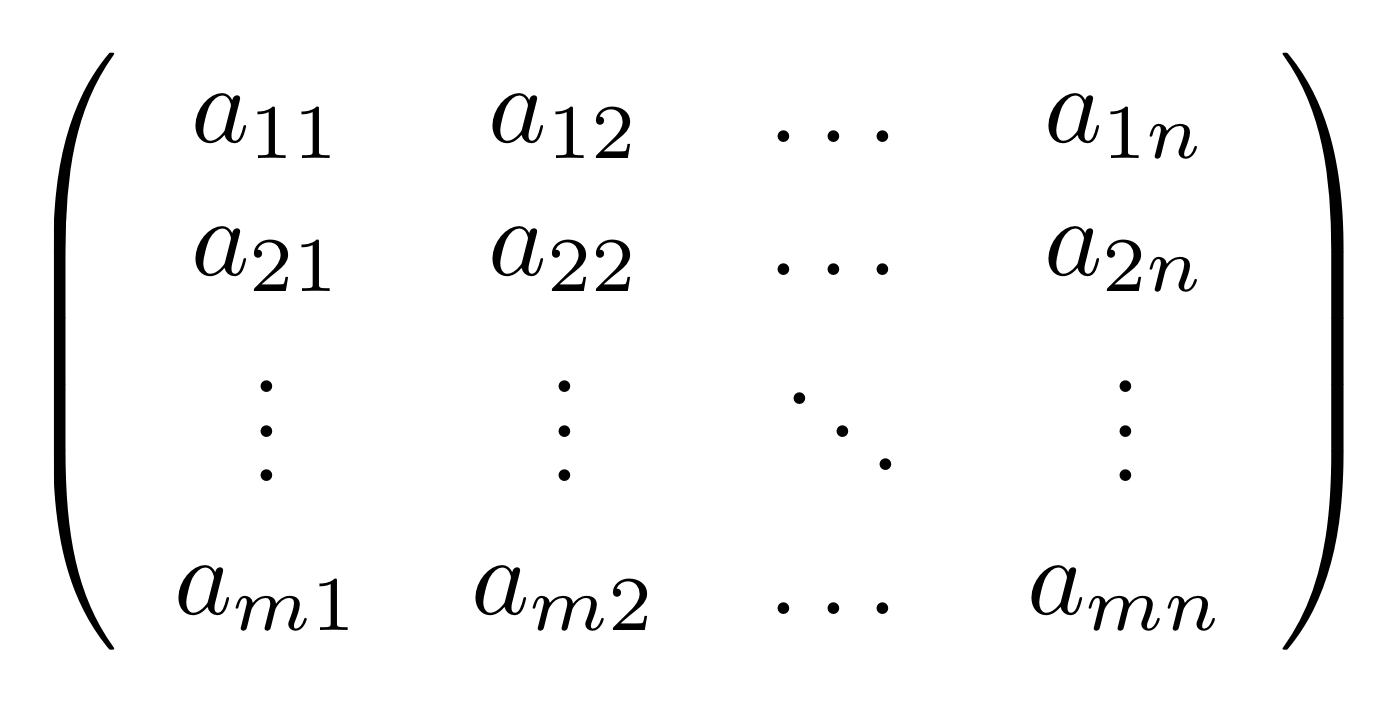
































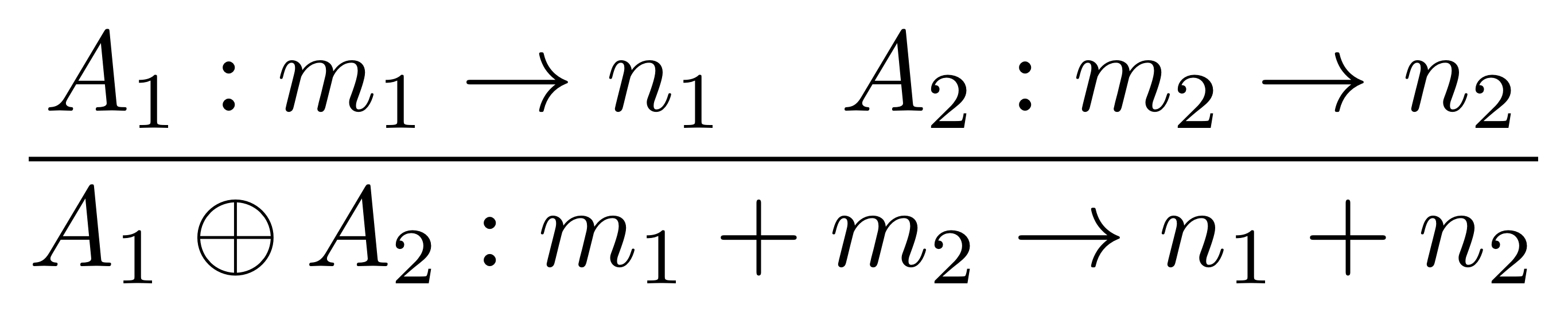


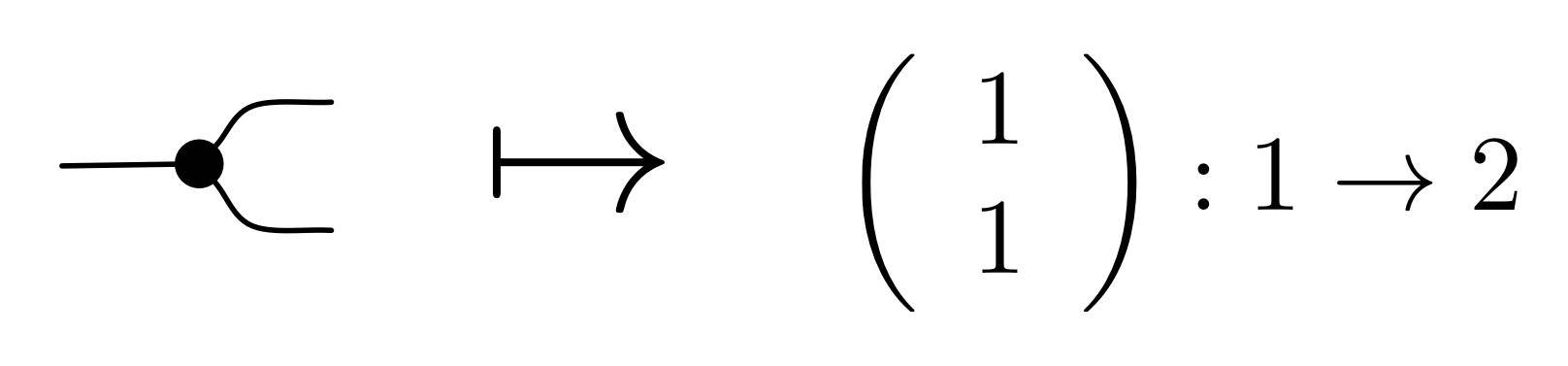
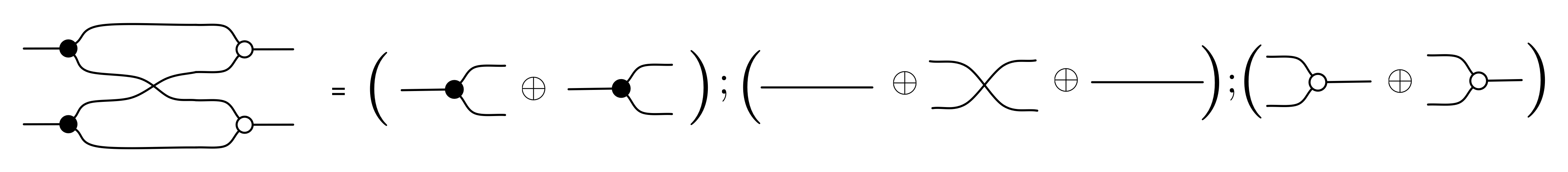
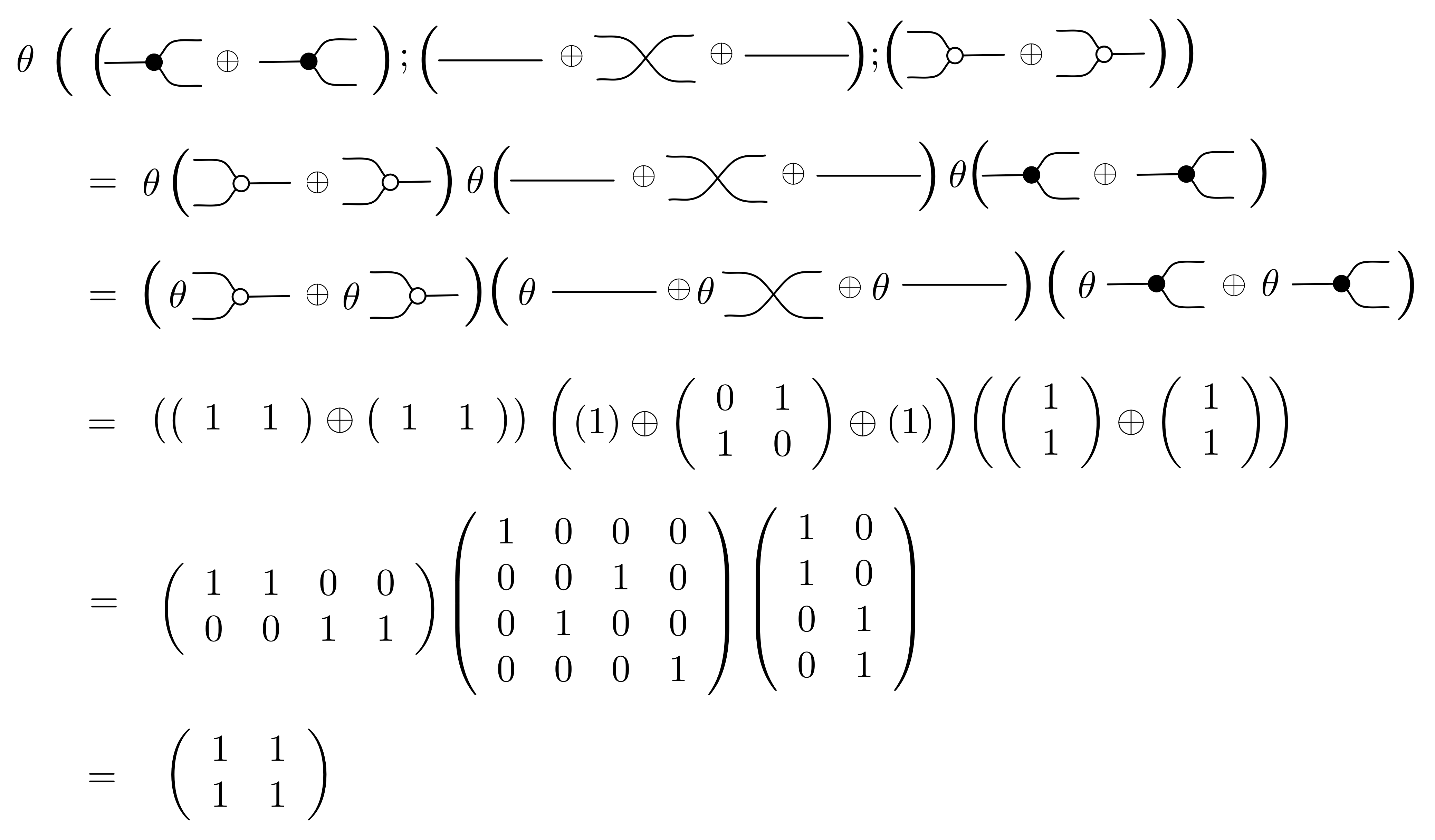
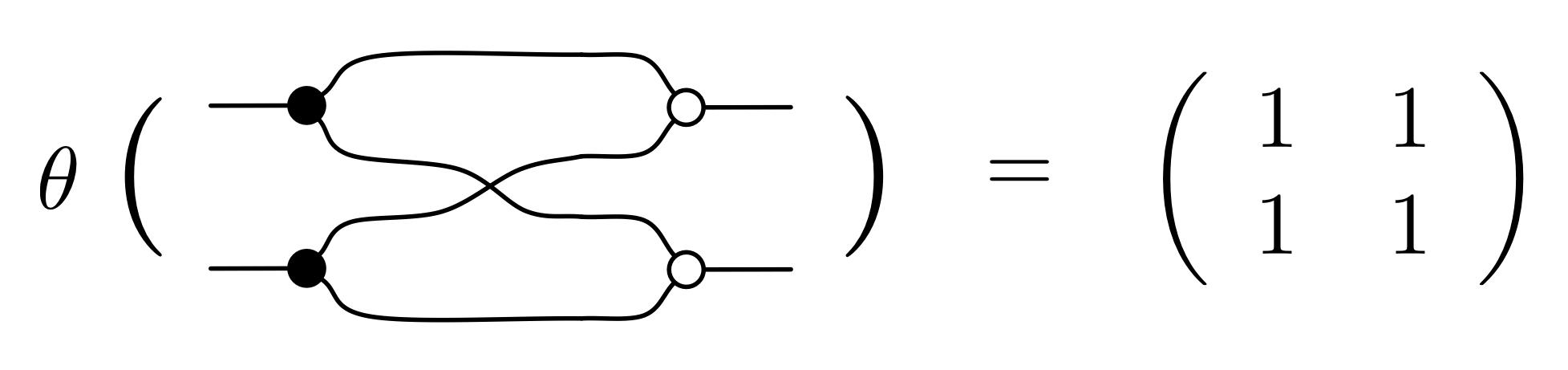
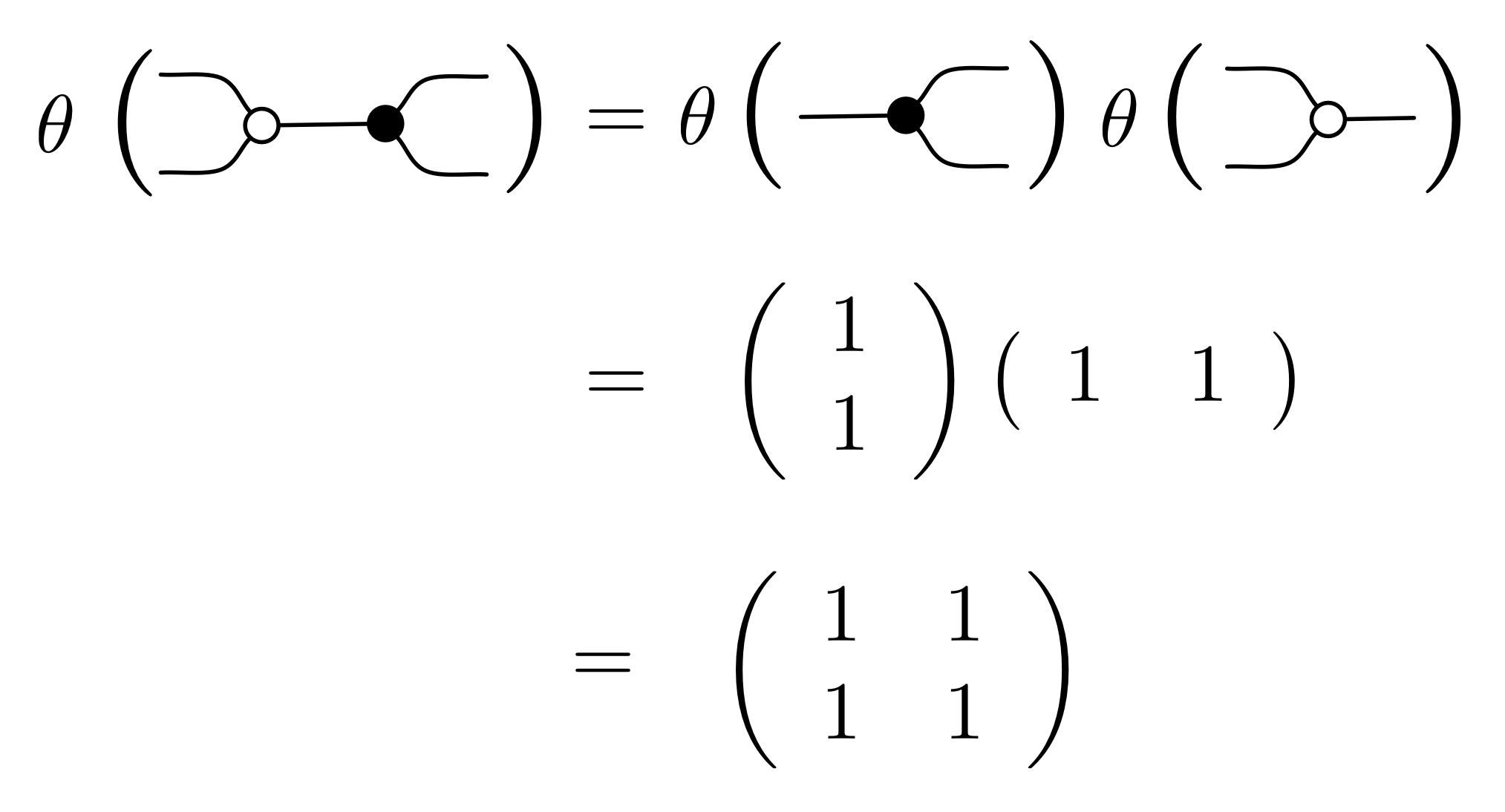

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}