
There are two common ways to interpret the information represented by a matrix. Roughly speaking, it boils down to whether—when looking at a grid of numbers—you choose to see a list of columns, or a list of rows. The two interpretations are symmetric, and this is nicely captured by this blog’s obsession, the graphical syntax. And as we will see, the two ways of looking at matrices will lead us to two different, symmetric ways of understanding linear subspaces.
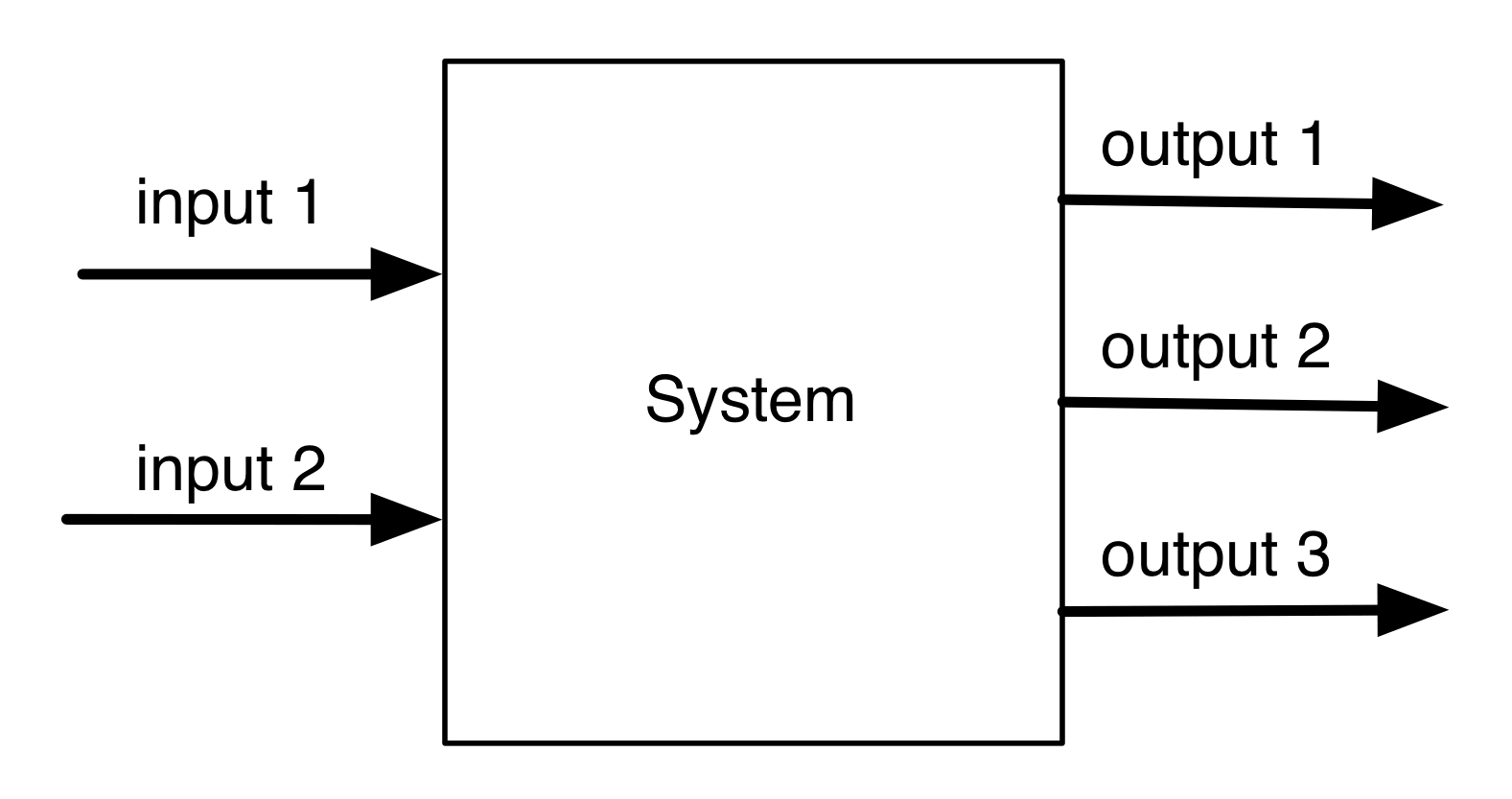
Consider an m×n matrix A, drawn with our graphical sugar for matrices as a gadget with n wires entering on the left and m wires exiting on the right, like so:

A can be viewed as consisting of n column vectors c1, c2, …, cn . Each of the c‘s is individually a m×1 matrix, so it has one wire entering on the left and m wires existing on the right. We can then wire up A, emphasising the column vectors, like so: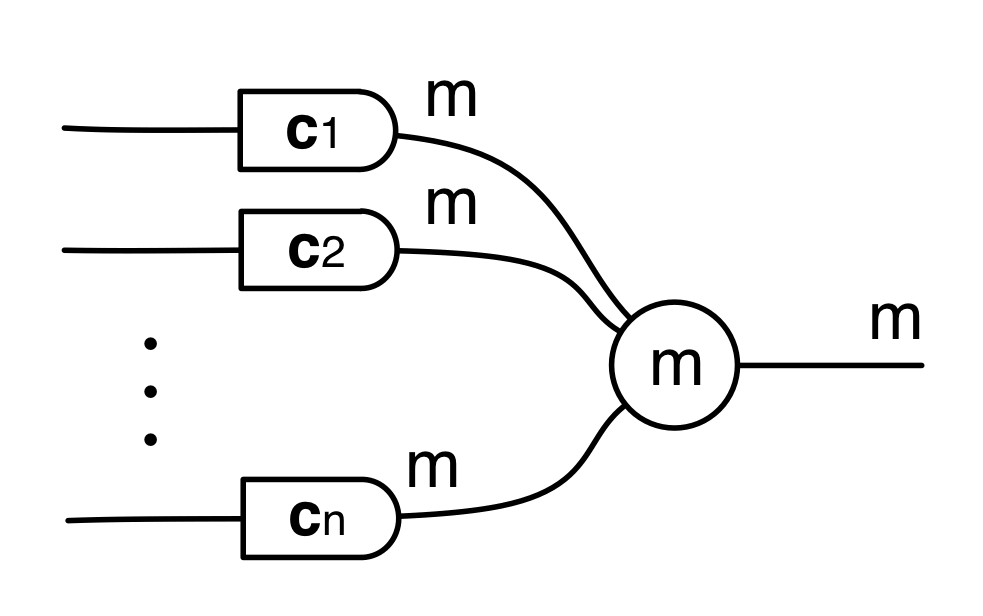
Alternatively, we can view the same matrix A as consisting or of m row vectors r1, r2, …, rn, with each having n wires on the left and one wire exiting on the right. This leads to drawing A like this: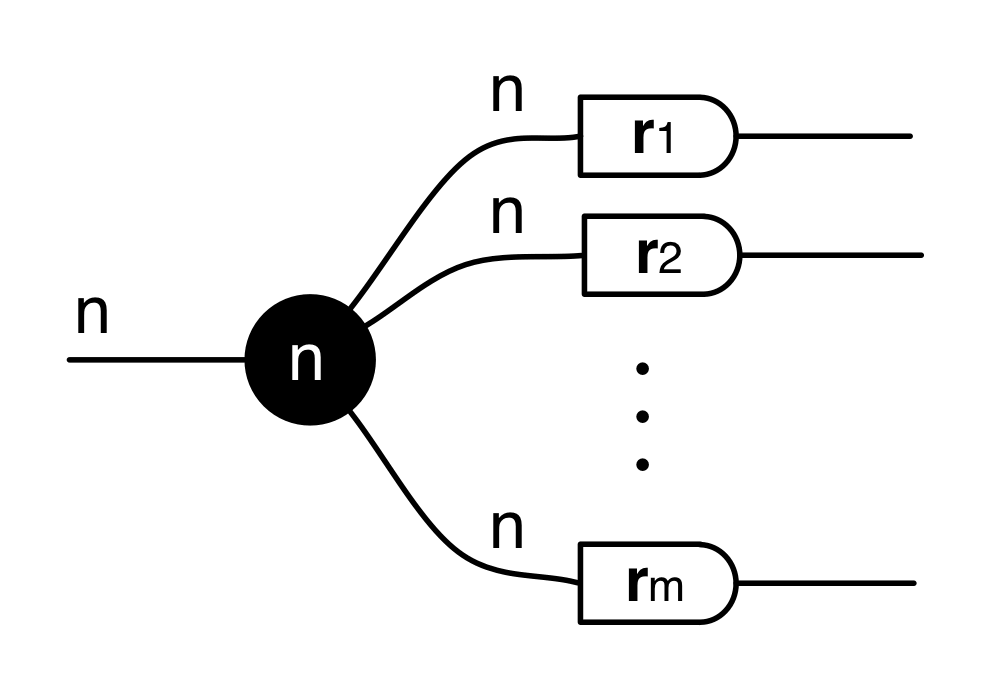
Even though in both cases we are talking about the same matrix—the same raw data—it turns out that the two different points of view lead to two quite different interpretations.
Let’s work through a concrete example. Consider the matrix

which has no particular significance; I just pulled it out of a hat, so to speak. But it’s usually a good idea to have a particular, concrete object to work with, and this one does the job.
Emphasising the columns, it can be drawn like this:
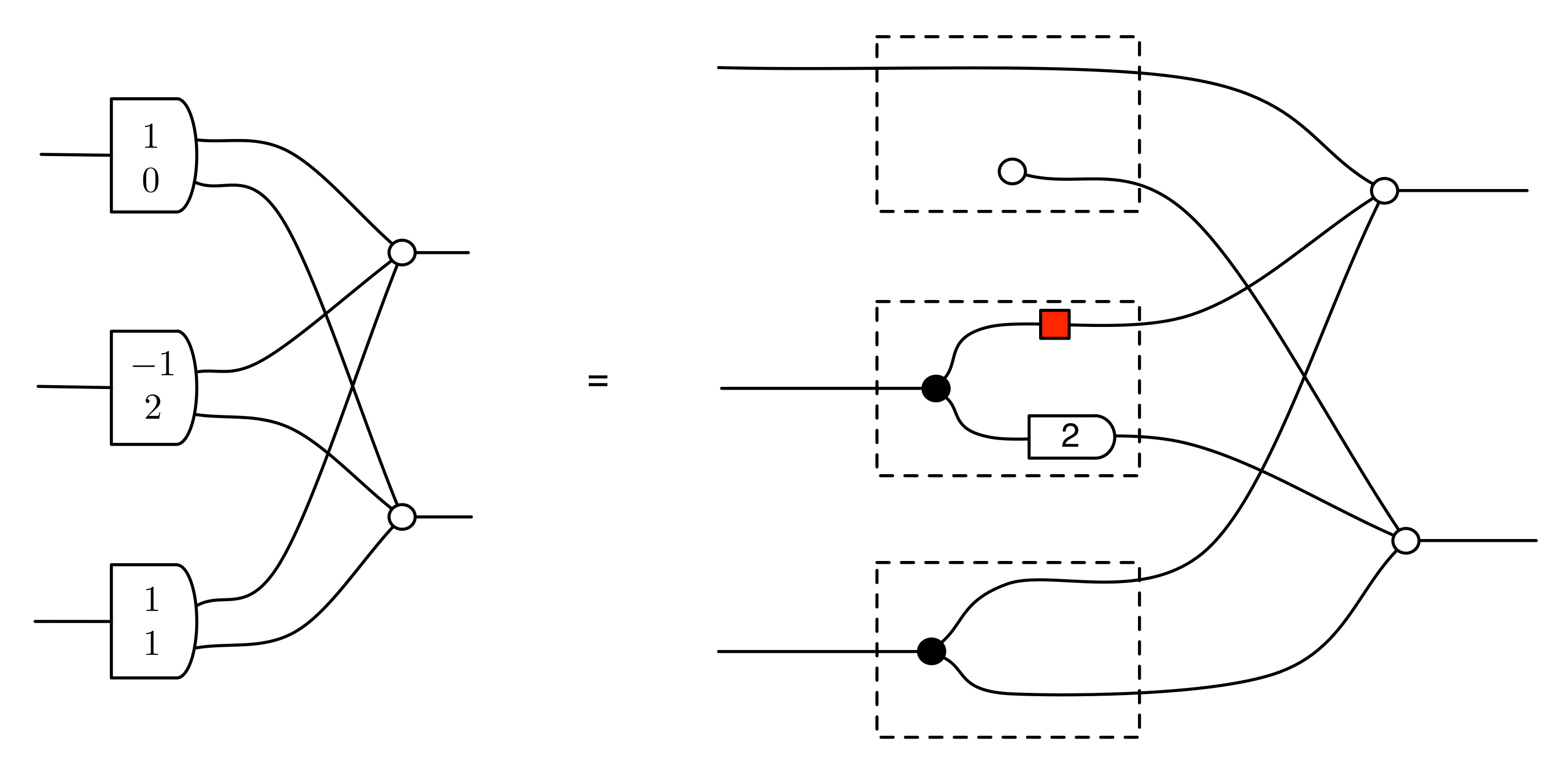
Or we can focus on the rows, as shown below.

Viewing a matrix as a list of columns leads to the first interpretation of what a matrix means: a recipe for of transforming n vectors—that is, columns of of n numbers—into m vectors, i.e. columns of m numbers.
Indeed, let’s take another look at A drawn in the way that emphasises its columns.
We can imagine the n dangling wires on the left as being n different inputs. Now each ci takes an input number and produces a column of m numbers. At the end, the n columns, each of size m, are simply added up.
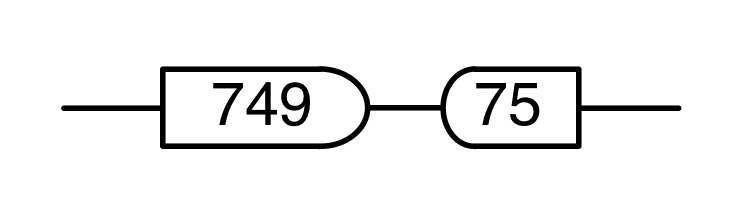
Let’s work through an example to see how this works, using the concrete matrix from before.

Here, our input vector consists of 5, 1 and -2. Each input results in two outputs, according to the recipe within each column block. They are then added up, e.g. 5+(-1)+(-2)=2 in the first output. Using the standard linear algebra jargon, we have produced a linear combination of the column vectors:

In our worked example above we took one particular, quite arbitrary choice of inputs: 5, 1 and -2. This leads to a natural question: exactly which vectors can be produced by this circuit, supposing that we are free to choose any inputs whatsoever.
In the example above, it turns out that all outputs can be produced by picking the appropriate inputs. But this is not always going to be the case; for example, if all the columns consist of only zeros then clearly only the zero output is possible.
The general question is, then, the following: given column vectors c1, c2, …, cn, which m vectors can be written as a linear combination
α1c1 + α2c2 + … + αncn?
How can we express this idea in our graphical language?
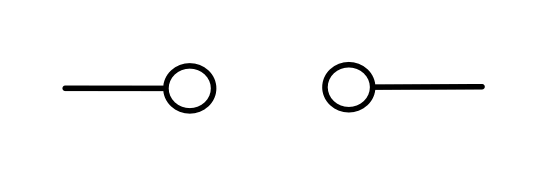
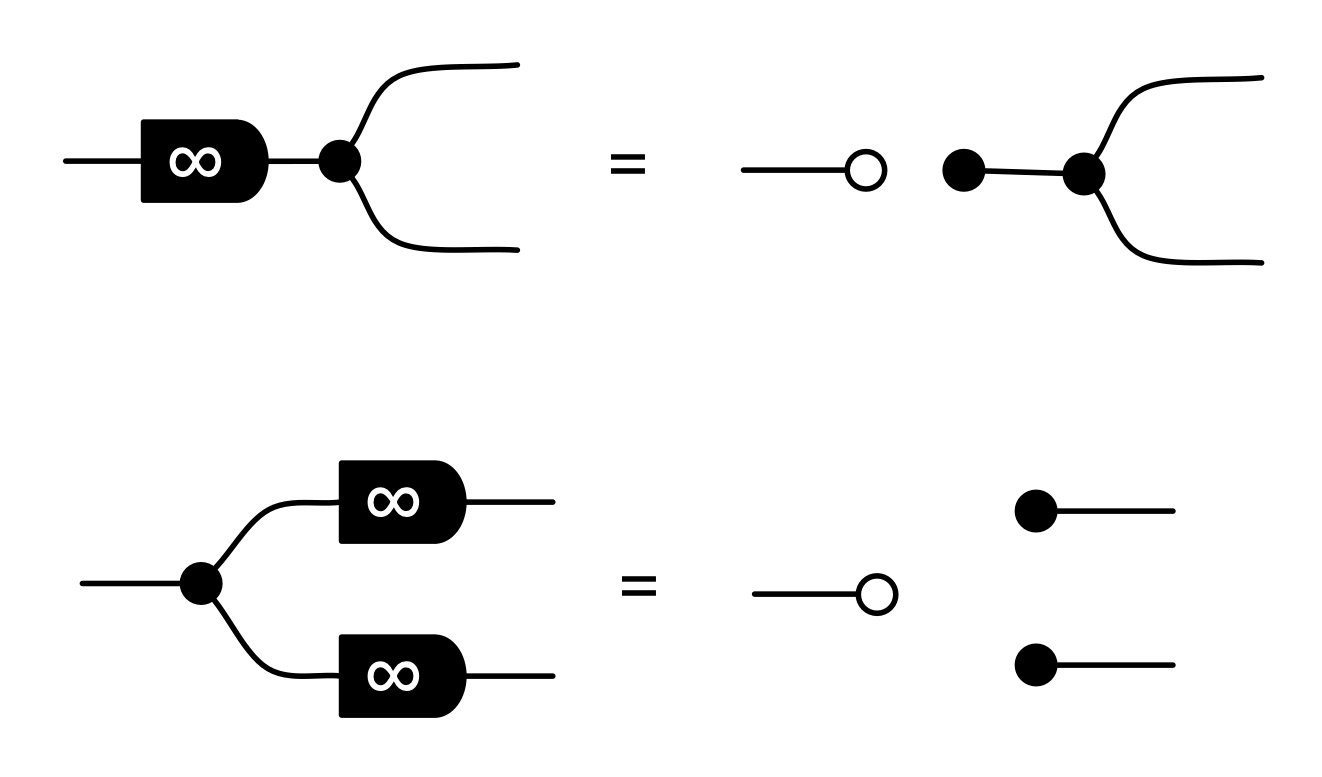
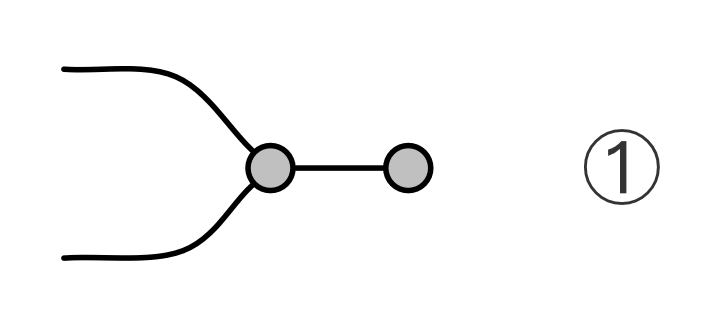
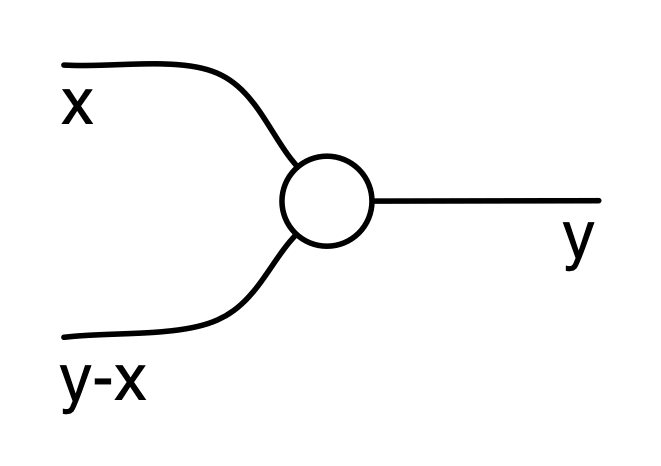
It turns out that the idea of considering all possible inputs is simple to describe. It is also quite intuitive. First, let’s return to our venerable discard generator.
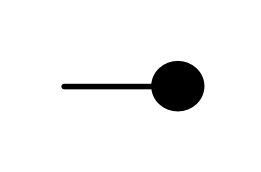
Recall that our intuition, backed by the functional semantics, is that this simply discards any number given to it. With matrices, we usually like to think of numbers flowing from left to right. So what are we to make of discard’s mirror image?
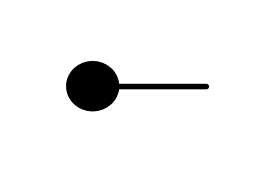
Well, if the discard can throw away any number, then a nice way to think about its mirror image is that it can generate any number. So, to get back to our original question, we can talk about the linear subspace of Qm generated by the matrix A by simply considering all the possible inputs to each column. Like so.
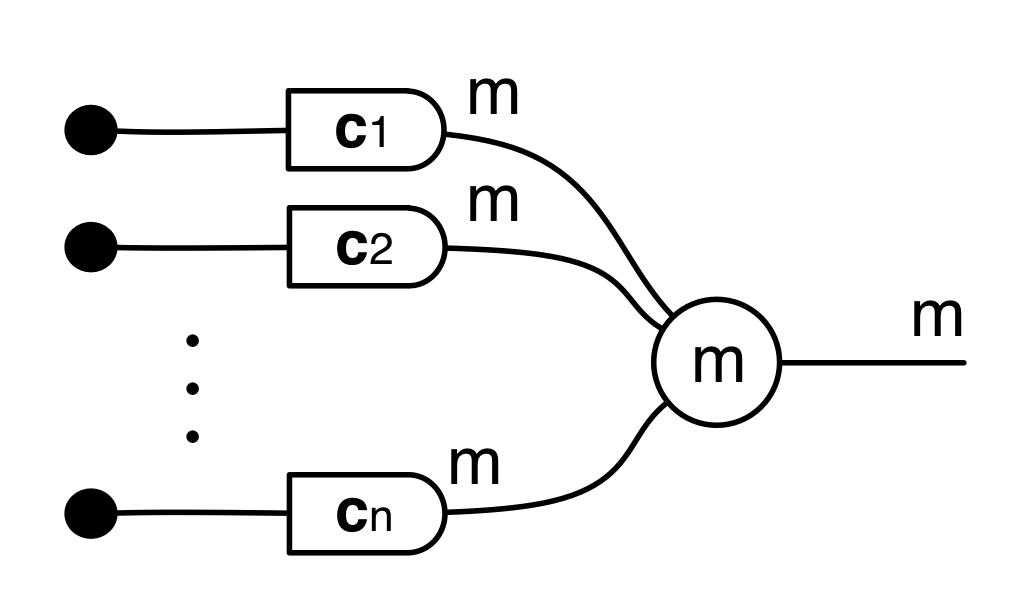
The diagram now represents the subspace that consists of all the linear combinations α1c1 + α2c2 + … + αncn of A‘s column vectors, where each α is a fraction. More precisely—as we have discussed in the last episode—the diagram gives us a linear relation of type Q0 ⇸ Qm, which we can (since Q0 contains only one element) then simply think of as a subspace of Qm.
This subspace is quite famous and has several names; it’s variously called the image, range, or column space of A, or the span of c1, c2, …, cn. And, using our usual syntactic sugar, we can simply write it as:

I claimed above that our example matrix can produce any pair of outputs. Let’s do the calculation to make sure: it’s a nice little exercise in diagrammatic reasoning.
The image is thus the entire space Q2, so for any pair of fractions p, q we can indeed find inputs u,v,w such that

Viewing a matrix as a collection of rows leads to another popular interpretation of the information that a matrix represents: a list of equations that constrain the inputs. Let me explain.
Drawing A in a way that emphasises the rows, we can think of each ri as encoding a linear combination of the inputs.
For example, going back to our original matrix, let’s label the inputs with variables x, y and z.

So the rows tell us how to combine the various inputs to form the outputs: for example, the first row gives us x-y+z and the second 2y+z.
Here, the natural question is to think of the rows as homogenous equations, and consider the set of solutions, those concrete choices of x, y and z that satisfy them. Homogenous, by the way, means simply that we append = 0 to each linear combination of variables.
So for our running example, we could consider the collection of all the inputs constrained so that they satisfy the two equations:
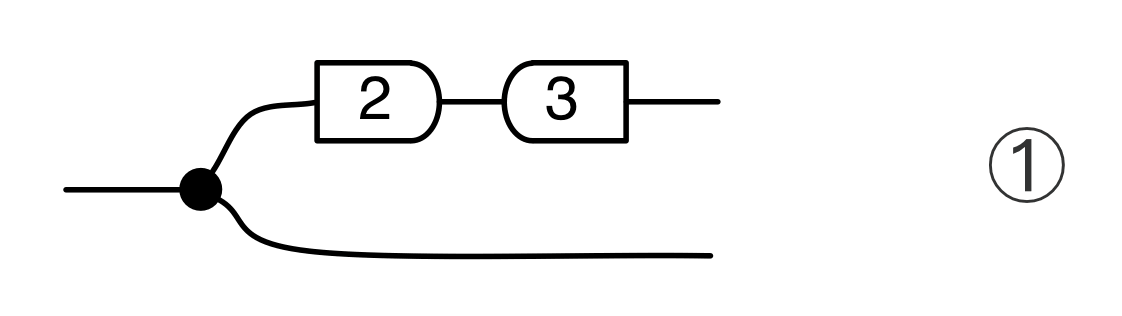
x-y+z = 0 ①
2y+z = 0 ②
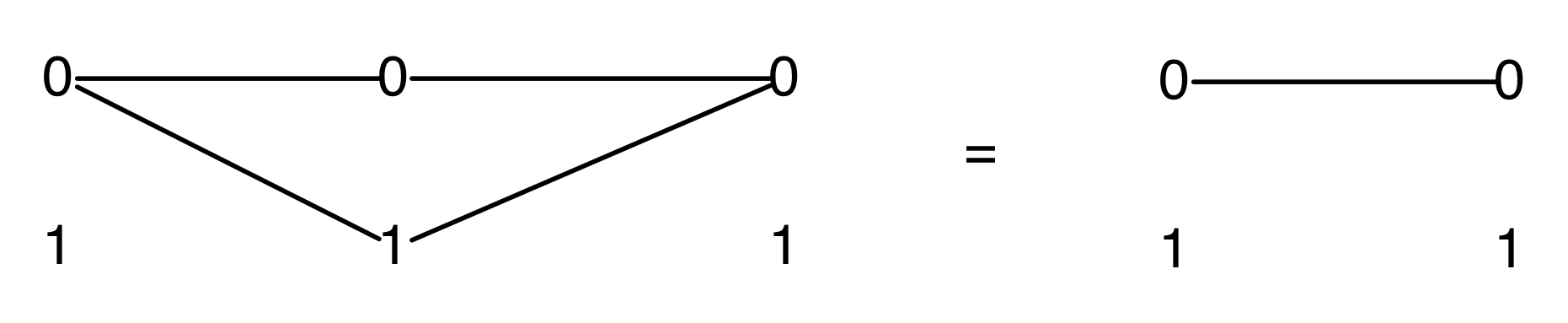
We can also represent this graphically. When we emphasised the columns, we introduced a new intuition for the mirror image of discard. This time we are focussing on the rows, and so, not surprisingly, we will introduce a new intuition for the mirror image of the zero generator.
Recall that the zero generator, in the original left-to-right functional interpretation, simply outputs 0.

So how are we to think of it’s mirror image?
 The answer is that it’s a constraint: it only accepts 0!
The answer is that it’s a constraint: it only accepts 0!
Using this insight, the solution set of the list of homogenous linear equations given to us by the rows of the matrix A is graphically represented as:
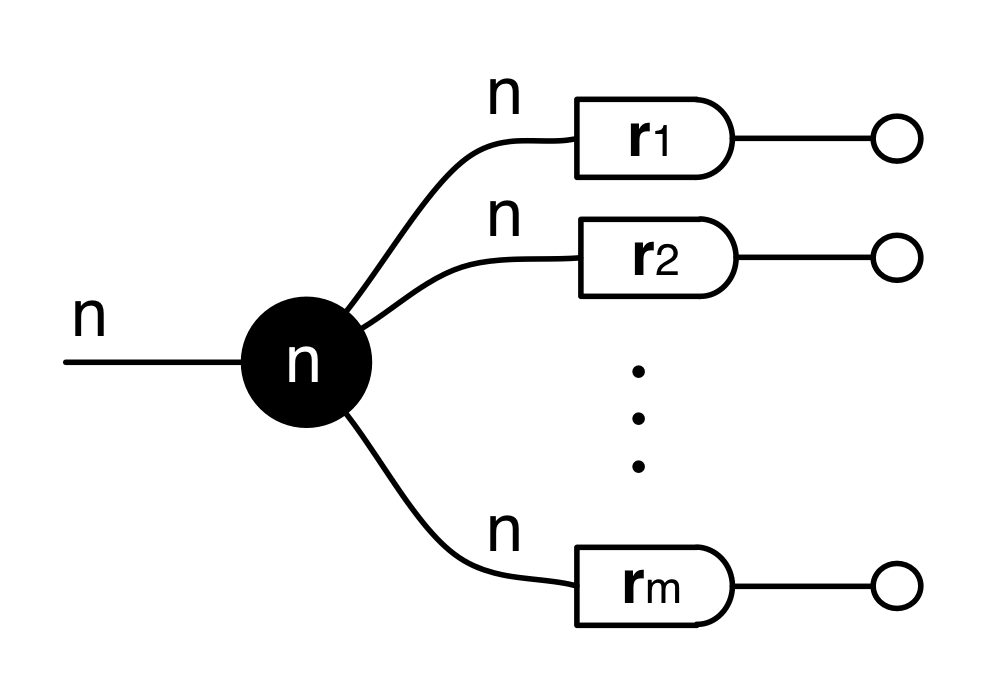
or using our usual sugar:

This is a linear relation of type Qn ⇸ Q0, so for the same reasons as before, it’s pretty much the same thing as a linear subspace of Qn. This subspace is also very important in linear algebra, and is variously called the kernel, or the nullspace of A.
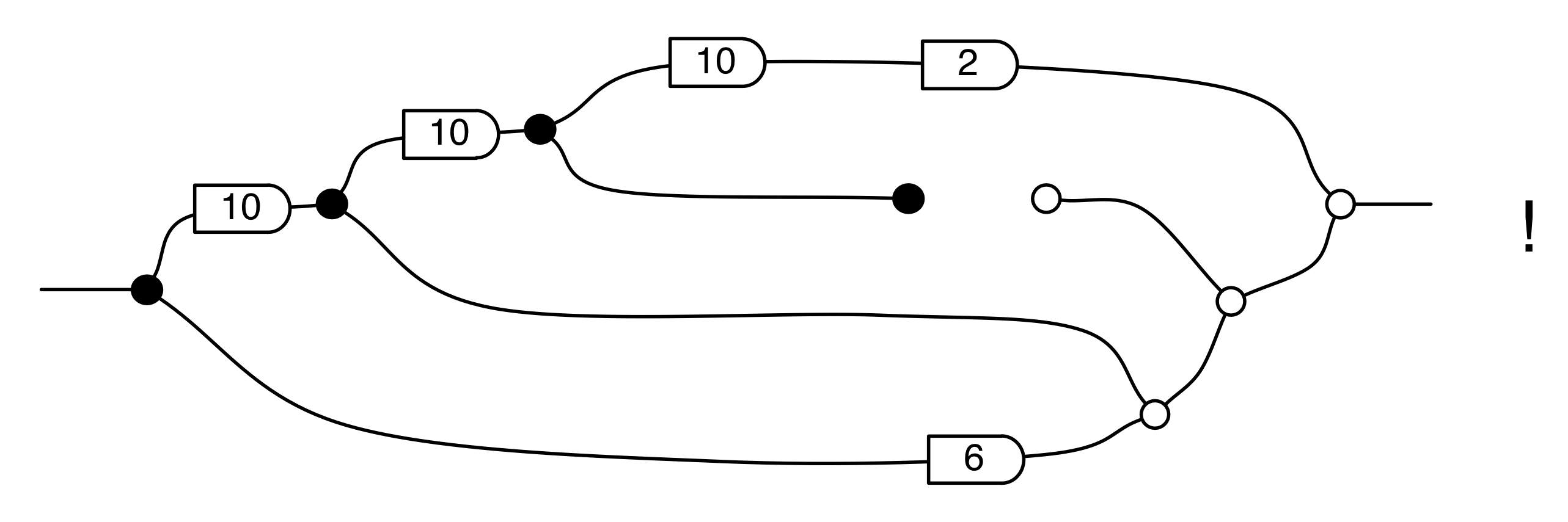
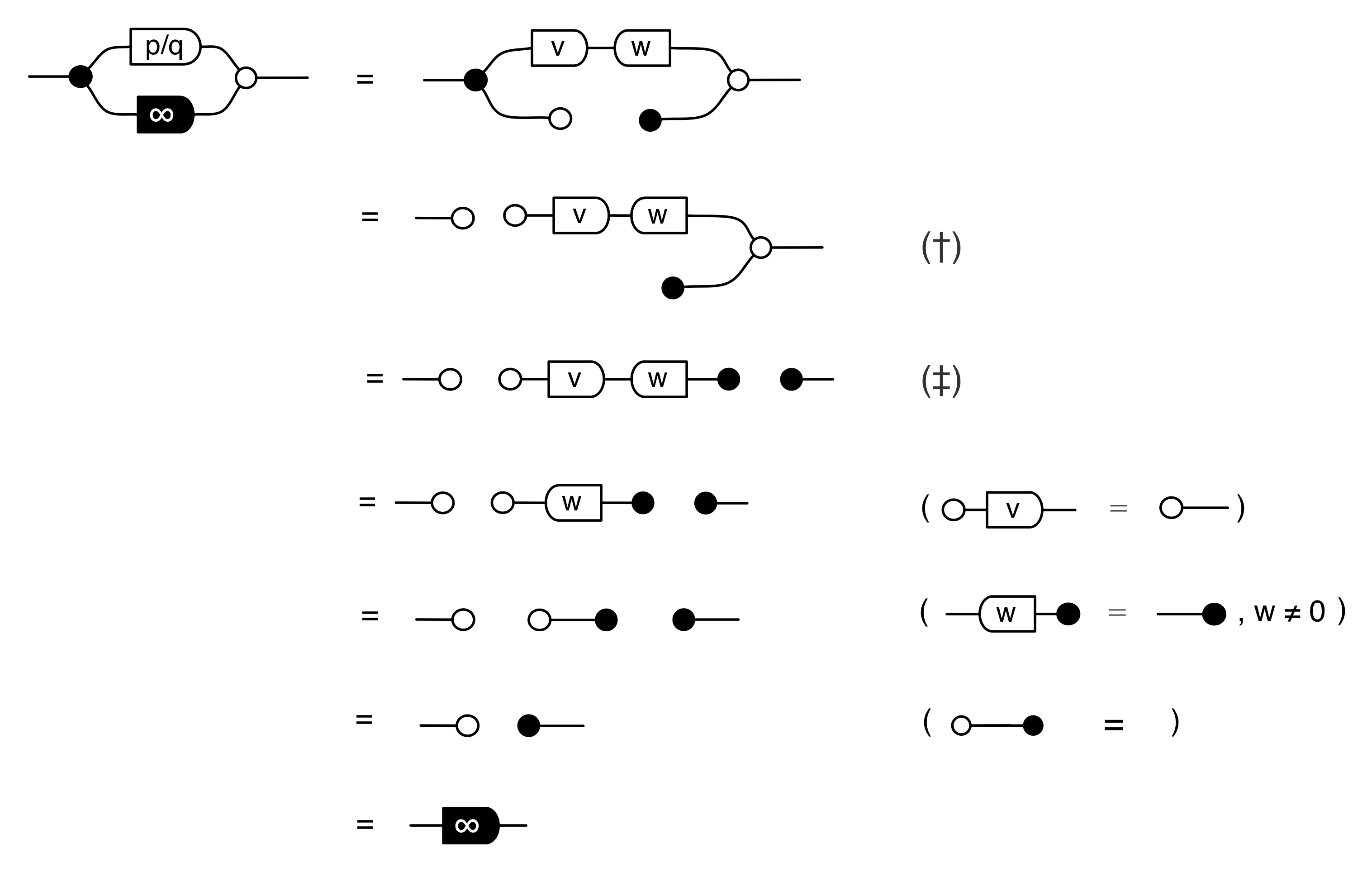
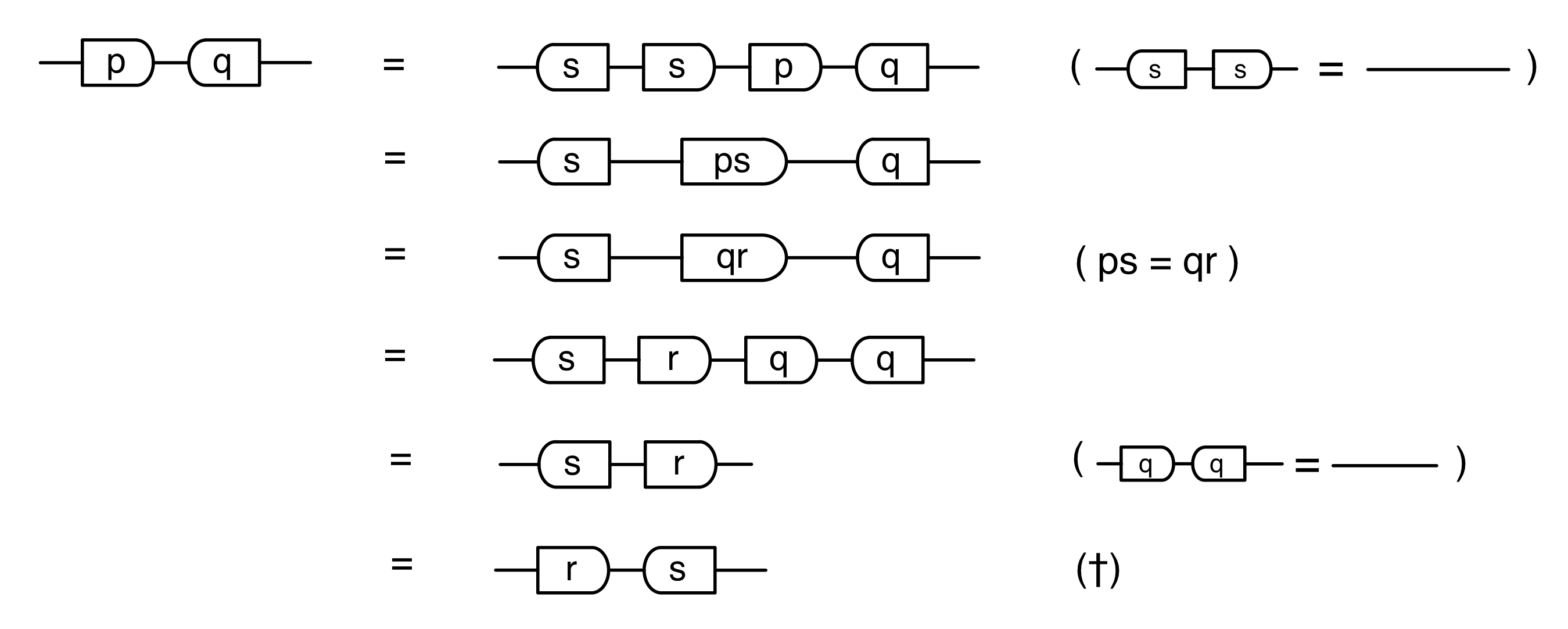
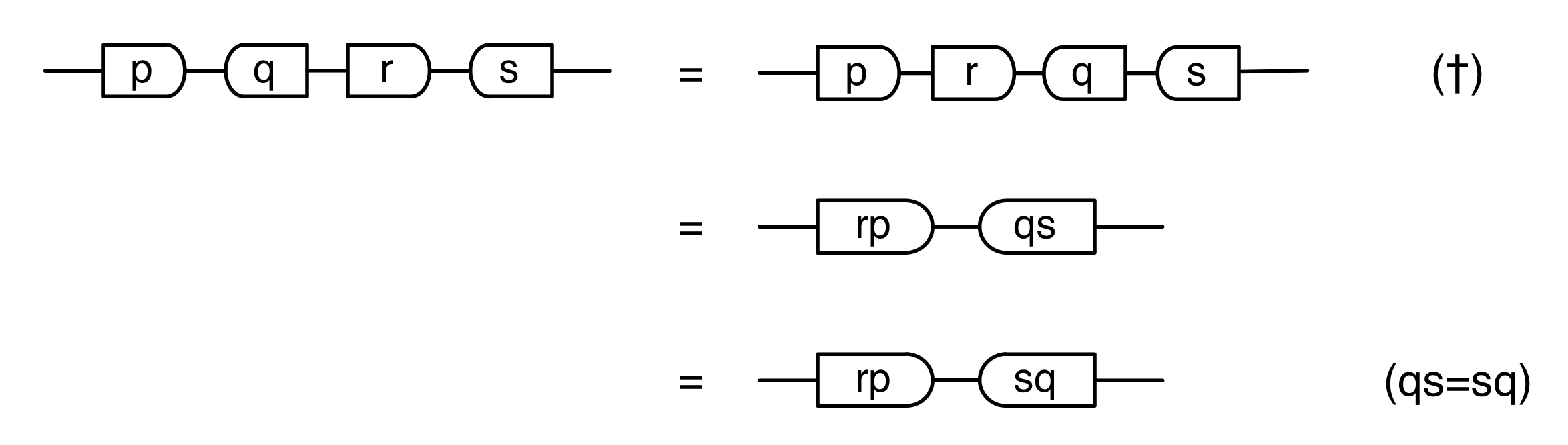
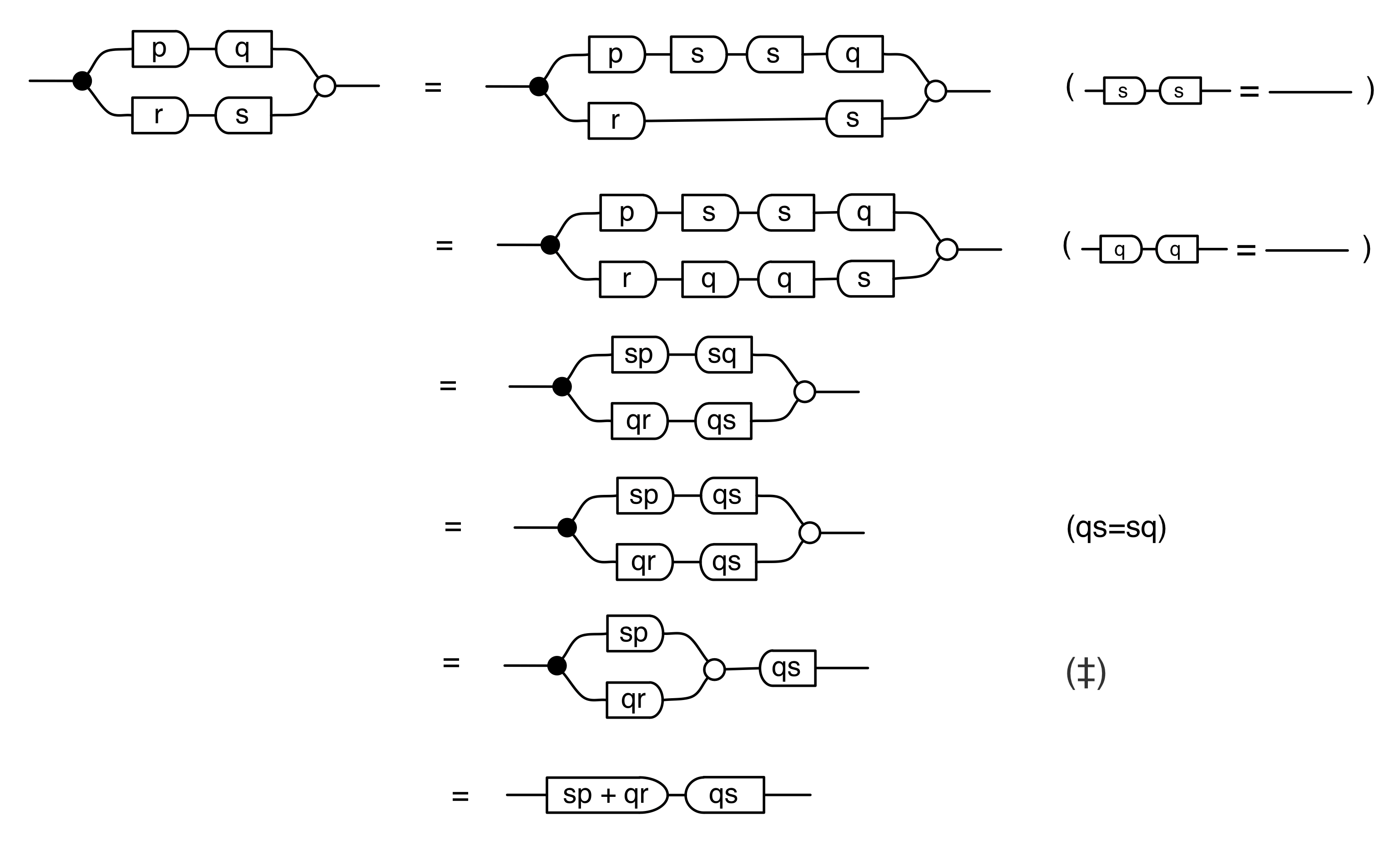
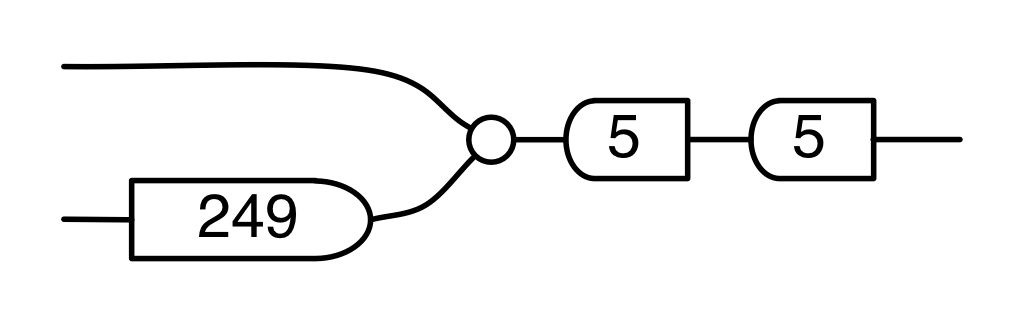
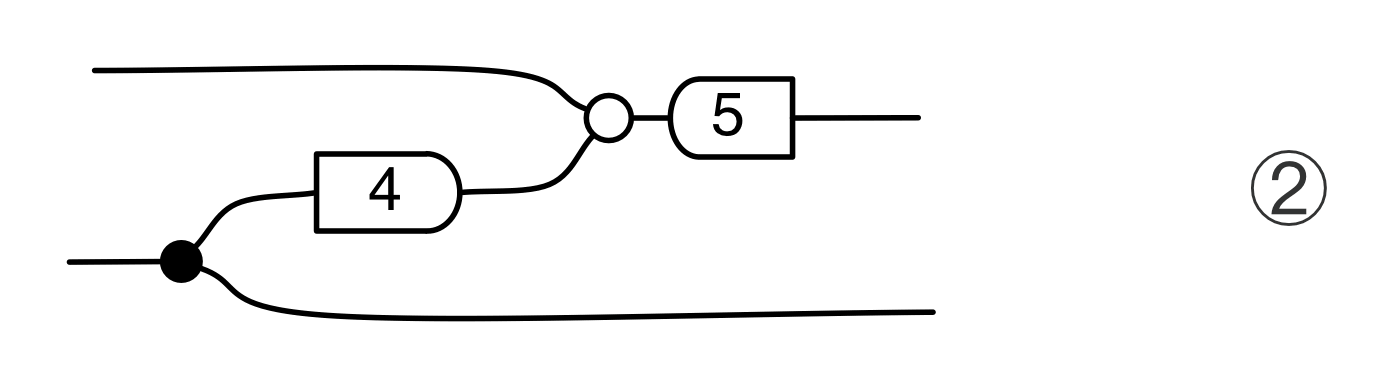
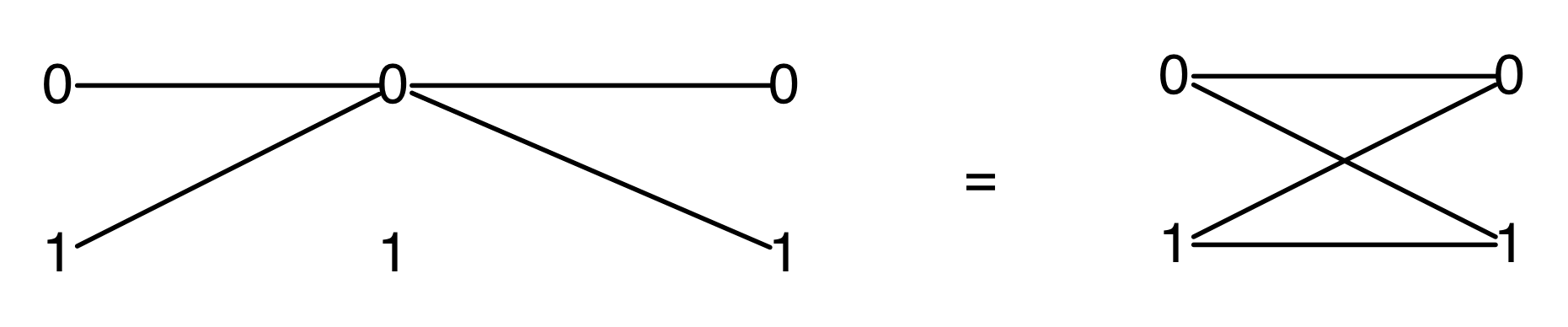
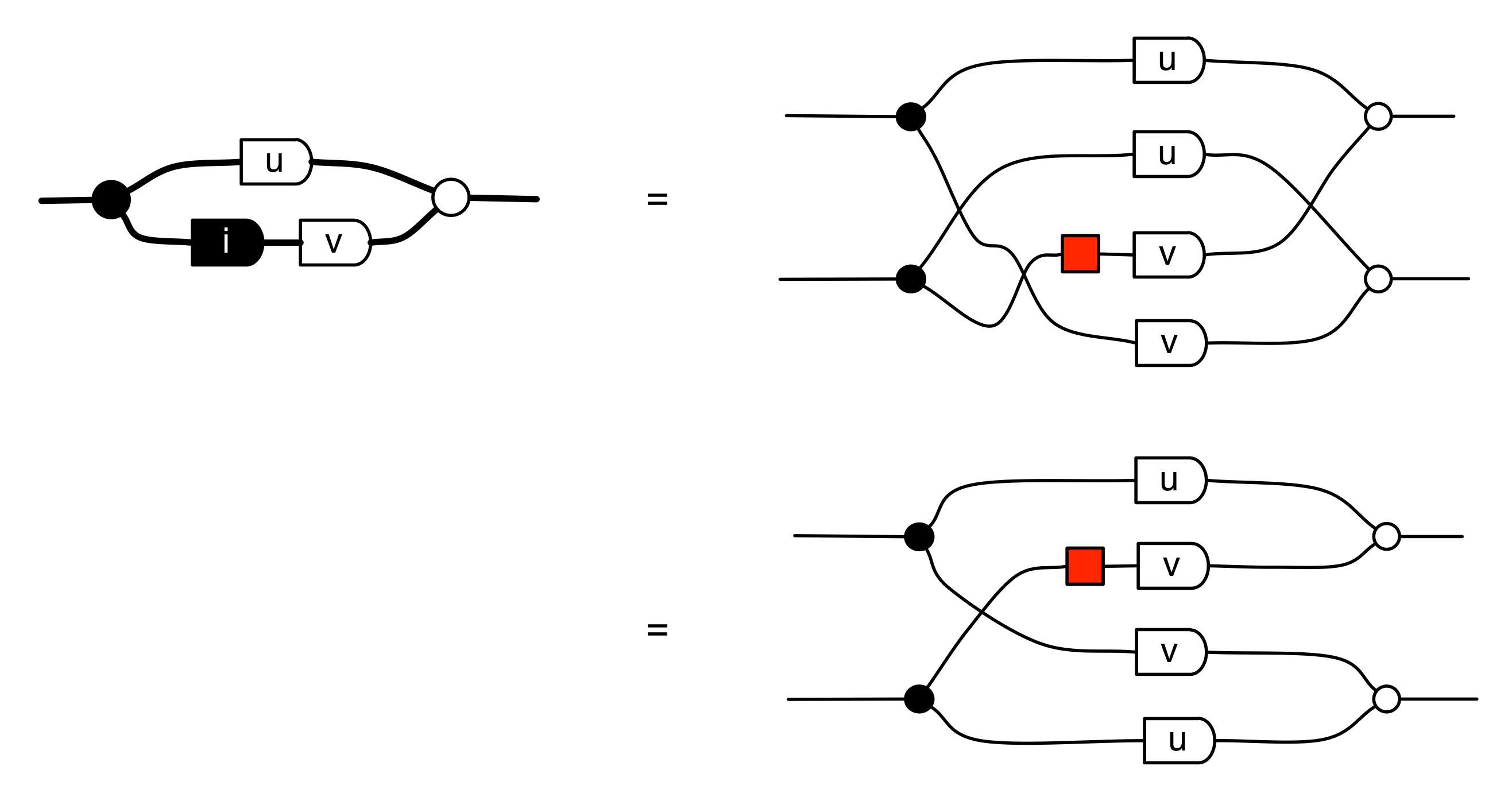
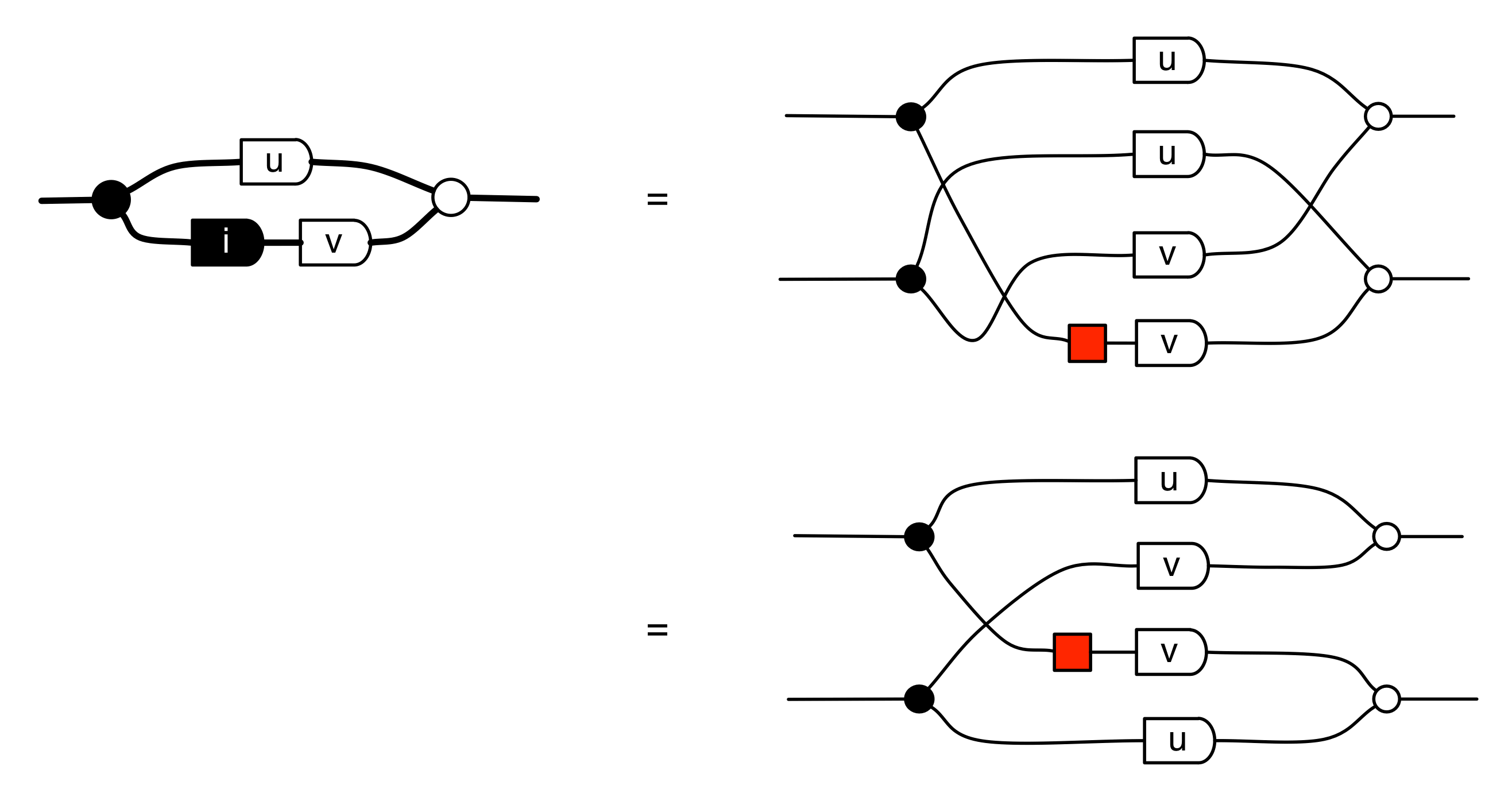
Let’s do a calculation that will give us more information about the kernel of our long running example matrix. The calculation is a bit longer than before, but the details are not so important at this stage.

In the derivation we used the Spider theorem from Episode 23.
Here’s the interesting thing about the calculation: we started with a diagram in which we were thinking of the “flow” as going from left to right, where our inputs had to satisfy some equations. We ended up with a diagram which is easier to understand as going from right to left. Indeed, it’s an example of the kind of subspace that we got by focussing on the columns; it is:

where N is the matrix

In other words, the kernel of M is the same linear subspace as the image of N. This tells us that everything in the kernel is of the form

where α is some fraction. So the solutions of the system of equations ① and ② are x = 3α, y = α, z = -2α.
We have seen that some descriptions of a linear relation can be read “from left to right” and others “from right to left”. Indeed, we have just seen an example of a linear relation that had two descriptions:

So what is really going on here? It turns out that we can think in two ways about every linear relation.
- Every linear relation can be seen as “being generated”, in the way we described the image subspace.
2. Every linear relation can be thought of as consisting of the solutions of homogenous equations, of inputs “being constrained”, the way we described the kernel subspace.
Let’s be more precise about this. We will start by considering the first of the two situations, the “being generated” case.
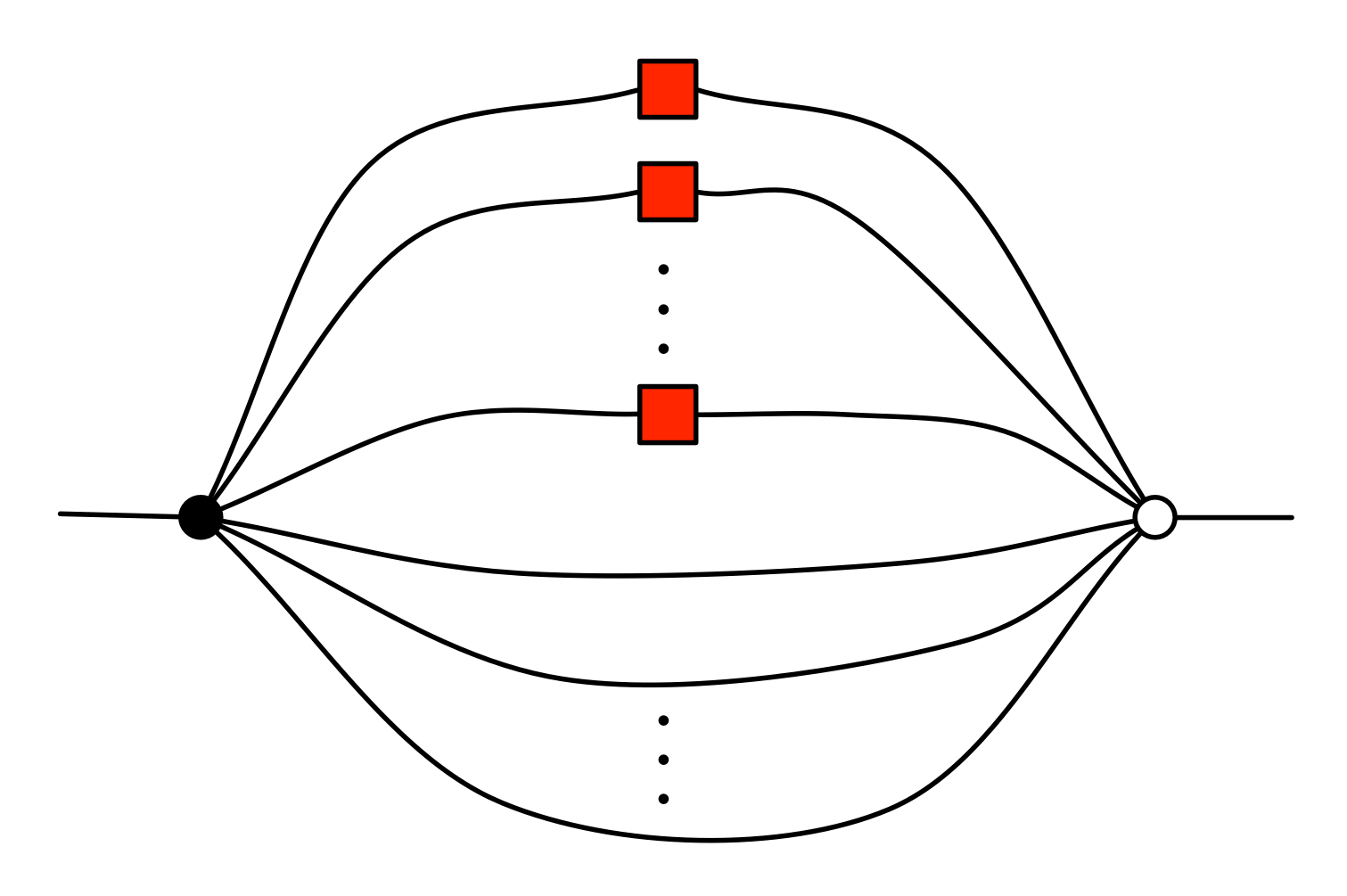
The proof of IH ≅ LinRel—which we haven’t seen yet but we will go through in due course—has one important consequence: for every linear relation R: m⇸n we can find an m×p matrix A and n×p matrix B such that
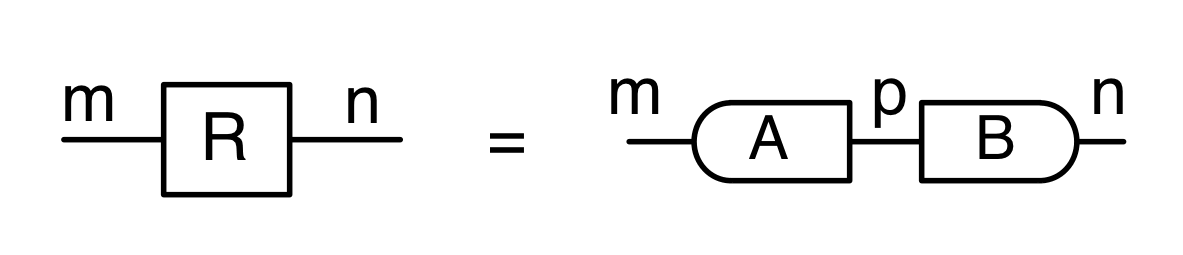
If we have such matrices A, B then we will say that they are a span form of R. Span forms allow us to think of R as being generated. In fact,
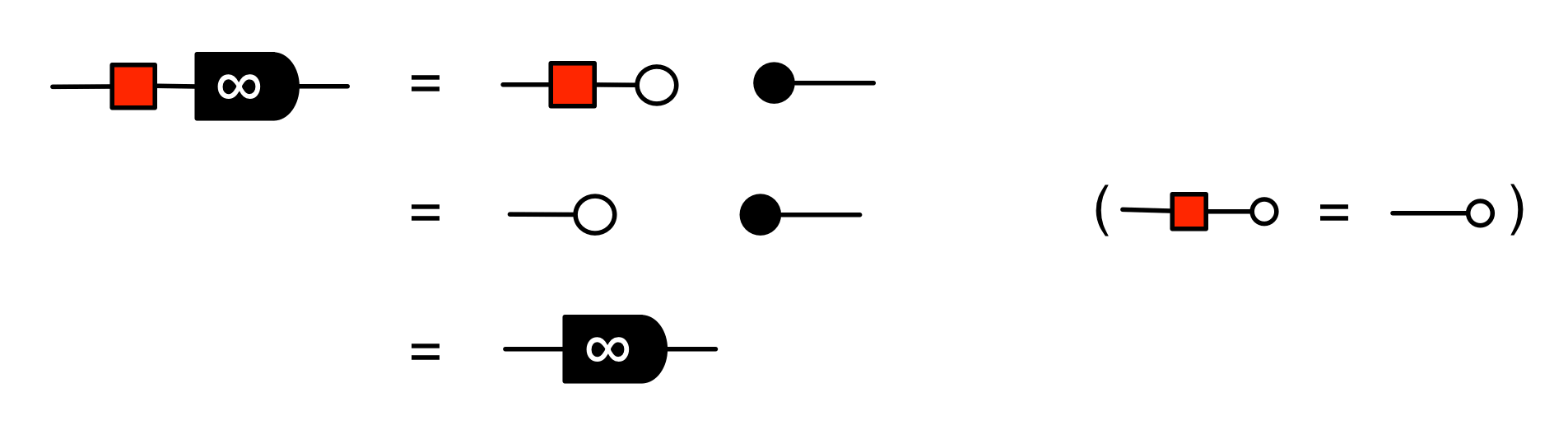
is in span form, since
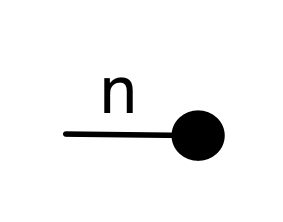 is the graphical representation of the unique 0×n matrix.
is the graphical representation of the unique 0×n matrix.
The proof of IH ≅ LinRel also gives us the “being constrained” case, which is pleasingly symmetric. For every linear relation R:m⇸n, we can, respectively, find q×m and q×n matrices C and D such that

This is called a cospan form of R. Cospan forms capture the idea that a linear relation can be thought of as the solution set of a bunch of homogenous equations. An example is the kernel of a matrix A

since

is the unique m×0 matrix.
One little quirk of history is that the traditional way of doing linear algebra focusses very heavily on the span view, and almost totally ignores the cospan view. One takes a space and finds a basis, one talks about its dimension, etc. But the cospan view is just as expressive, given the symmetries of graphical linear algebra. So, it’s entirely possible that Martian linear algebra has been developed in a way that prioritised the cospan view of linear subspaces. It’s fun figuring out the details, and we will do some of this in the next episode!
I’m having a very heavy start to 2016: originally I was planning to publish this episode in early January, and it’s now early February. The highlight of the month was a trip to Oxford on Friday January 8. I was there to examine a thesis entitled “!-Logic: First-Order Reasoning for Families of Non-Commutative String Diagrams” of (the now Dr.) David Quick, supervised by Aleks Kissinger. I liked the thesis very much: it’s about a logic for string diagrams, much like the ones on this blog. David’s logic supports reasoning about whole families of diagrams, including supporting sophisticated inductive arguments; much more sophisticated and powerful than the kind of induction that we have been using on the blog. I will have to write about it at some point in the future.
I arrived in Oxford quite early, and it was a really beautiful morning. On my walk from the train station to the computer science department I got the urge to take a photo.

The next Friday, January 15, I was in Cambridge to give a talk. That trip was also a lot of fun, and I got the chance to catch up with some old pals. The evening was very pleasant, and I decided to walk from the computer science department to the train station. On the way I took this photo:

I later noticed—and I promise, as much as it looks like it was, this wasn’t planned!—that the photos themselves are quite symmetric: compare the relationship of water to land. Since we spend a lot of time talking about symmetry on this blog, I think it’s somehow appropriate.
Continue reading with Episode 29 – Dividing by zero to invert matrices.
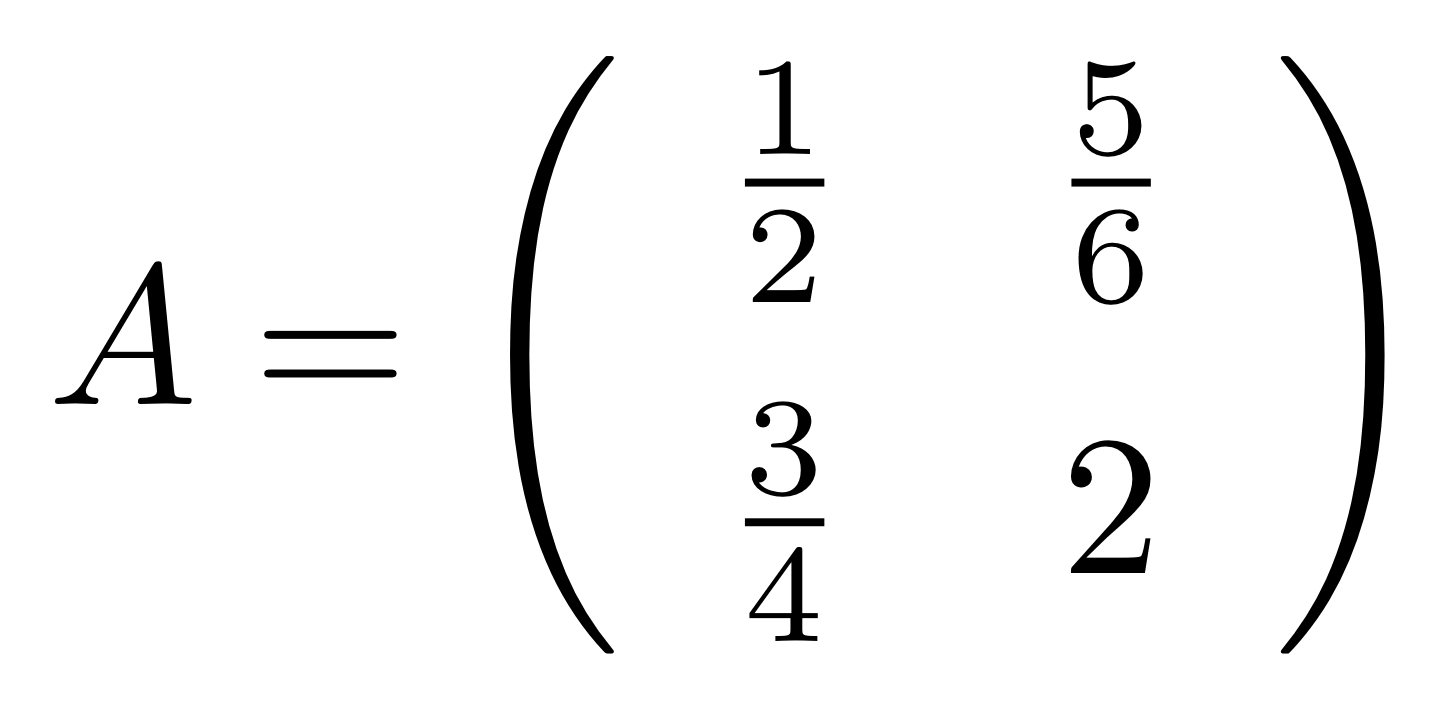
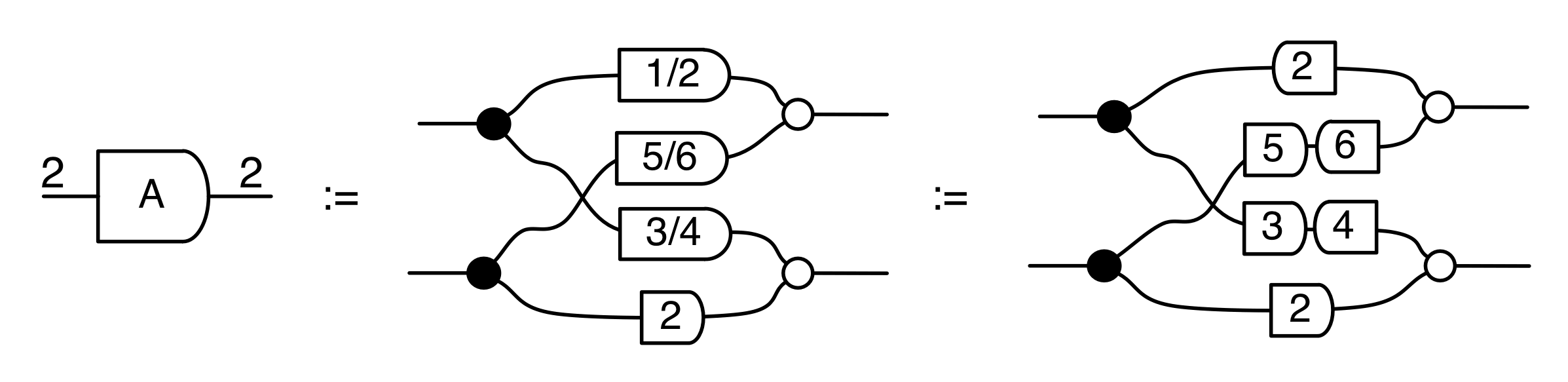
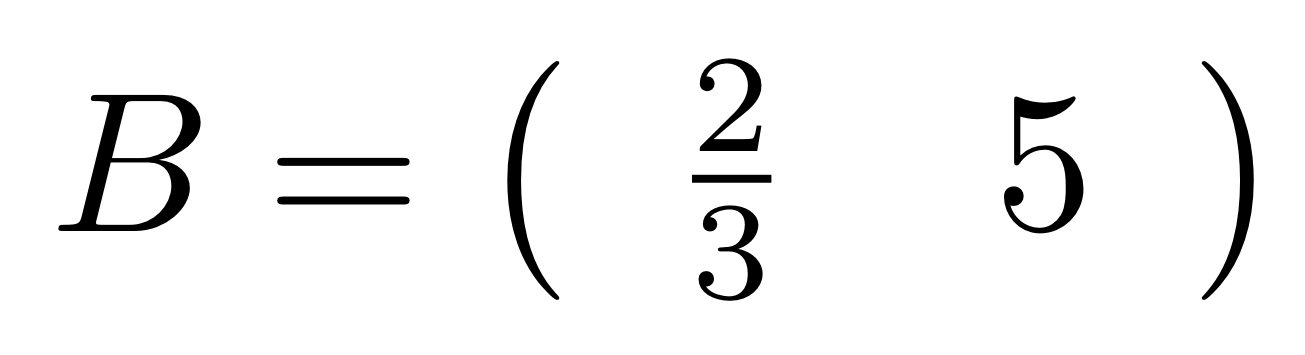
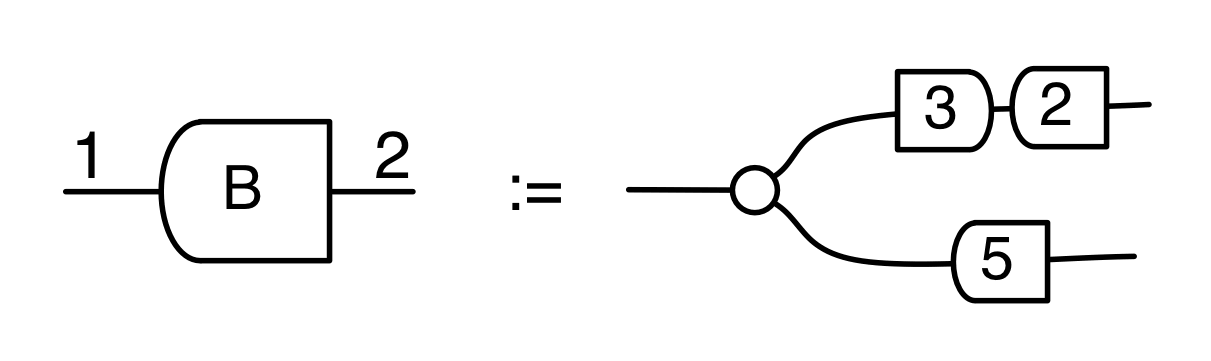

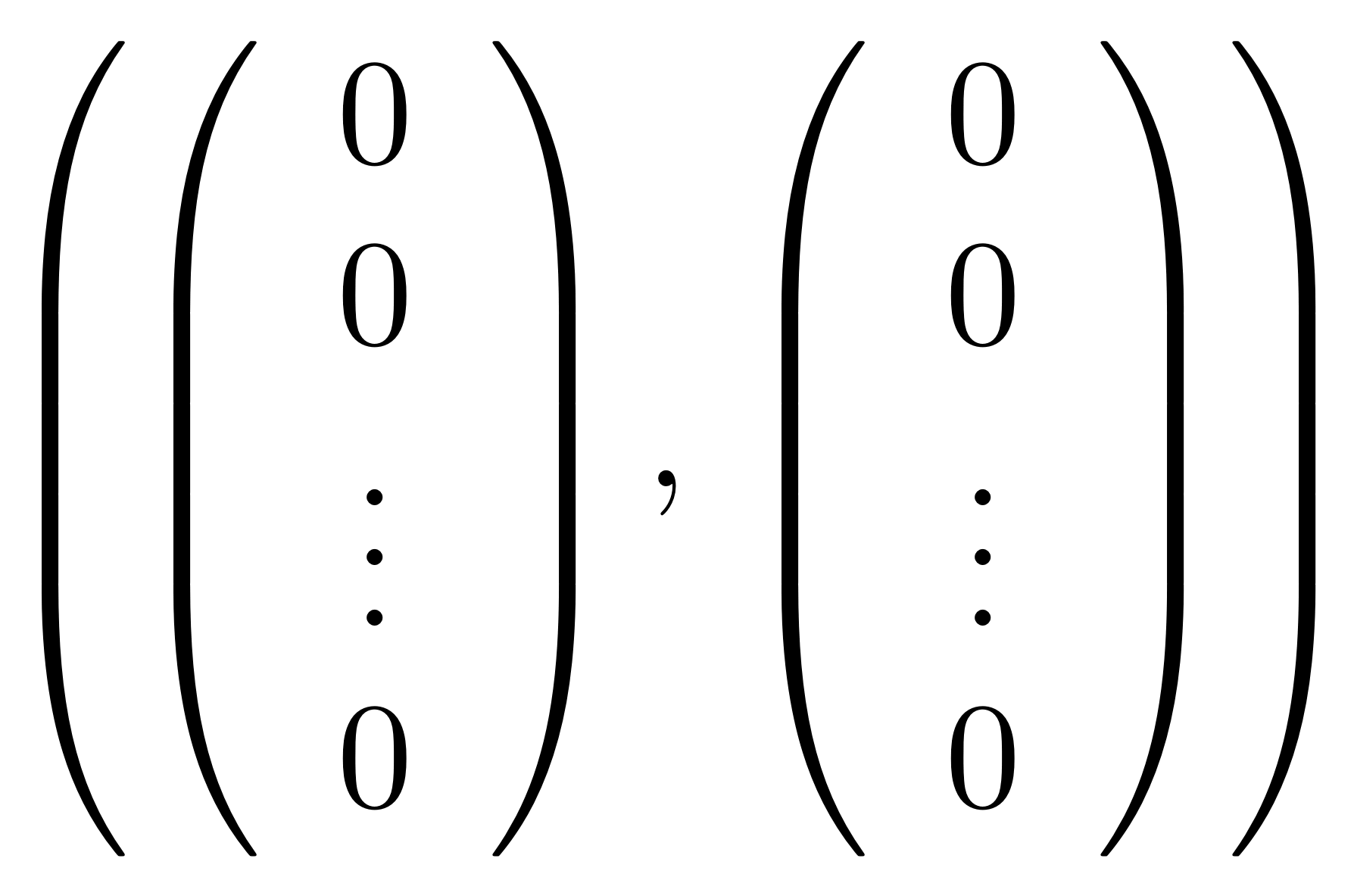
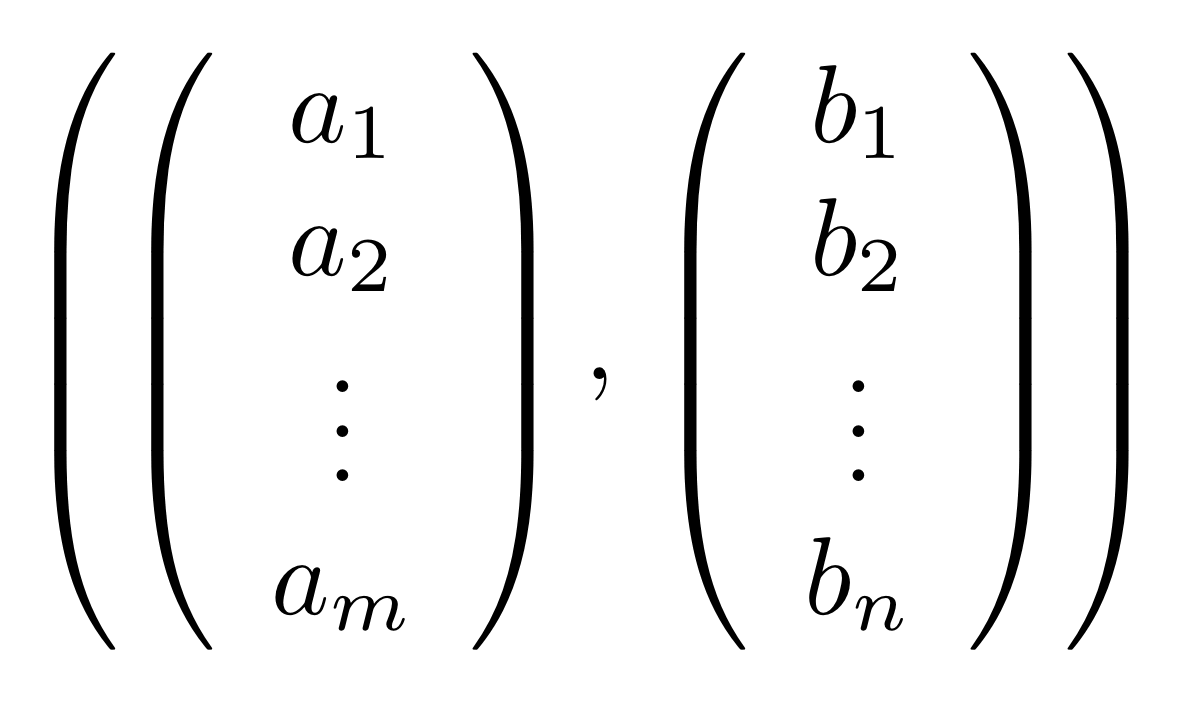
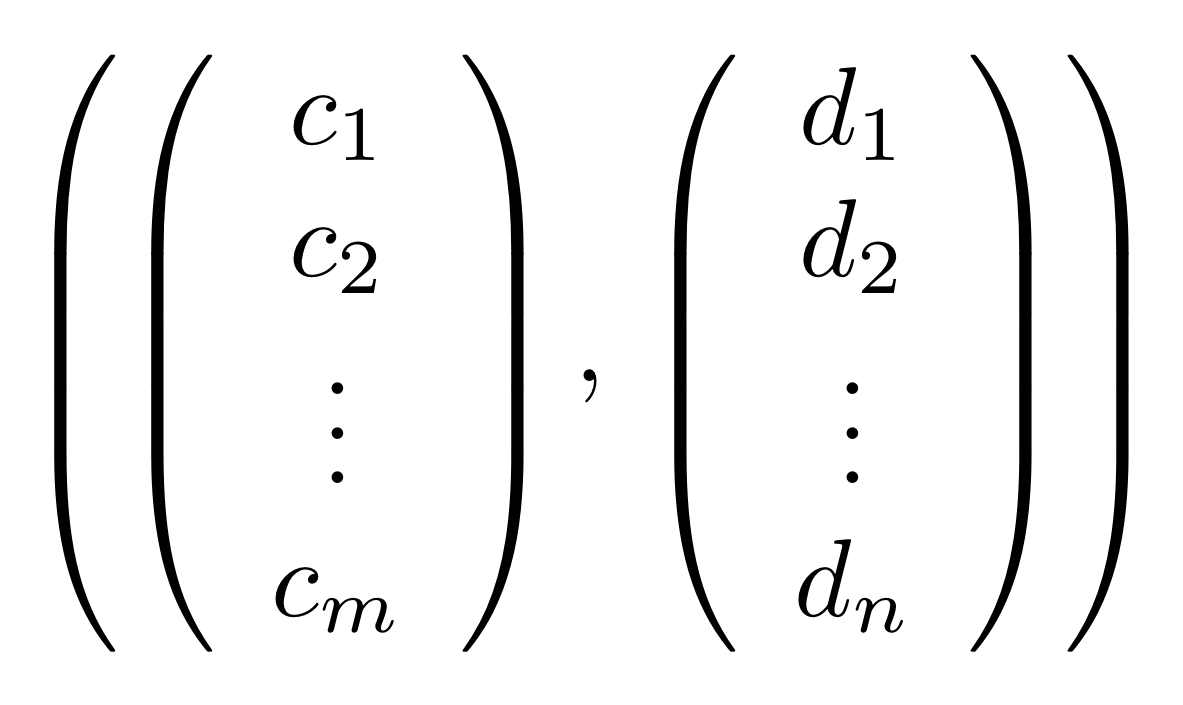
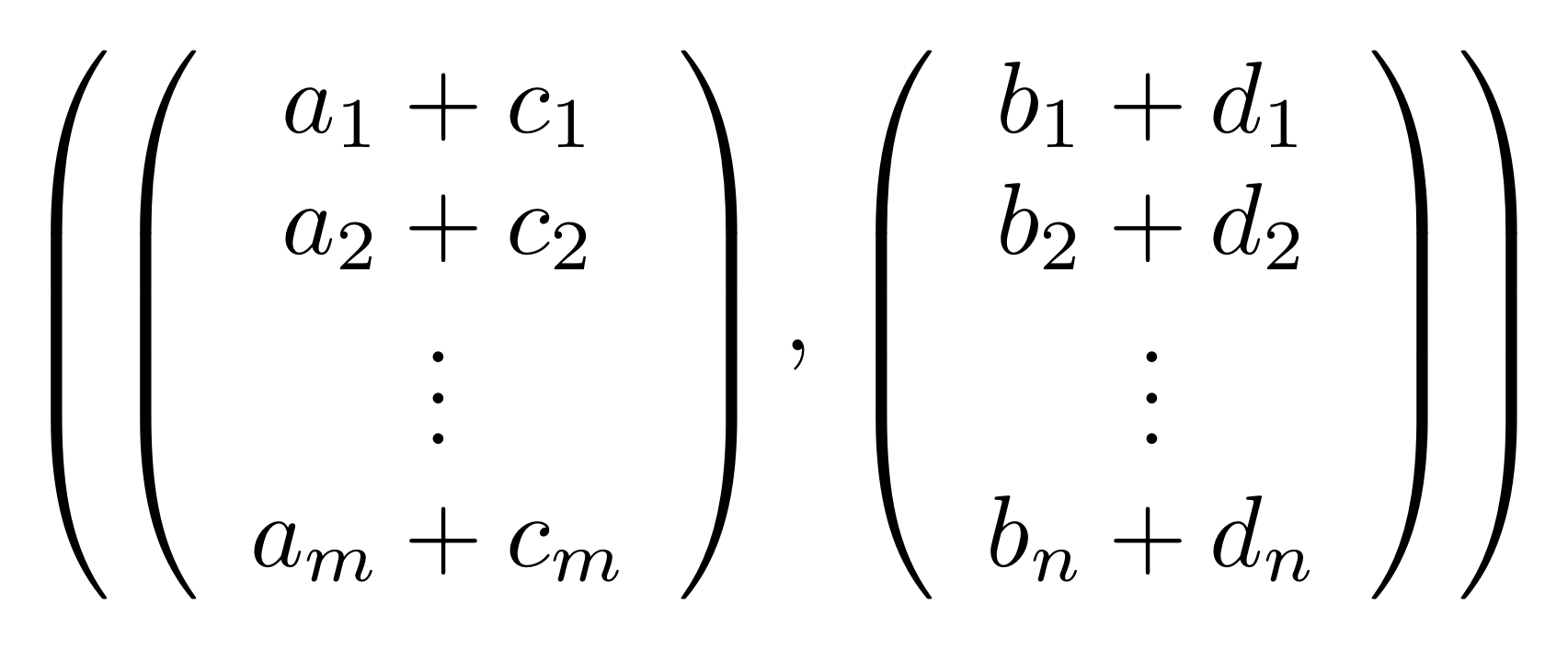
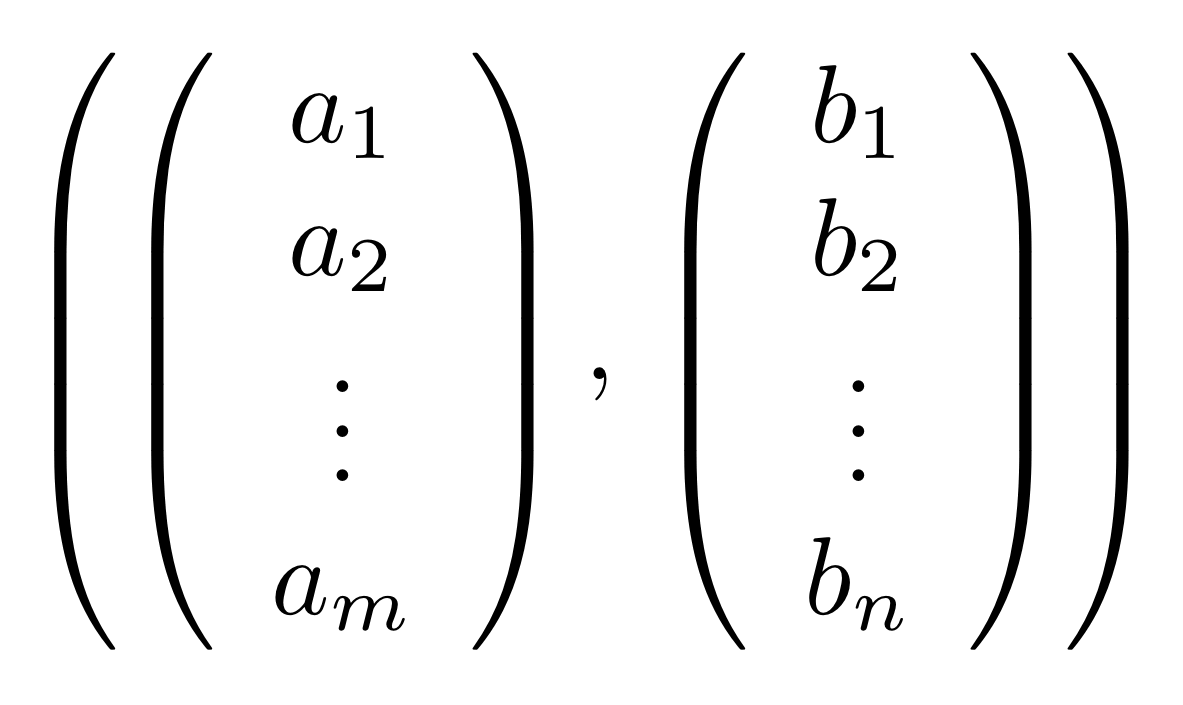

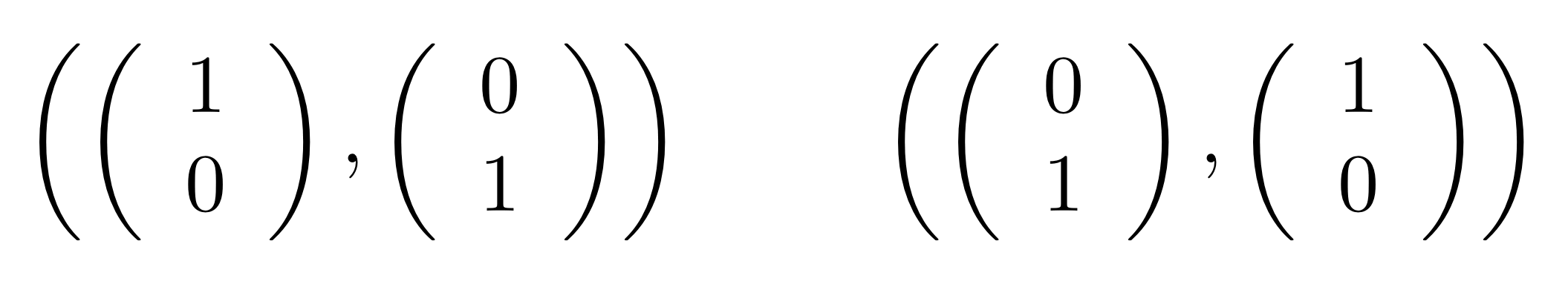
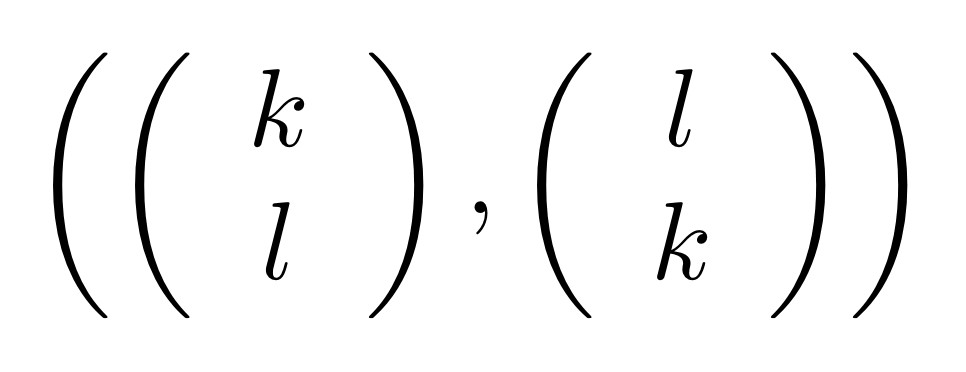








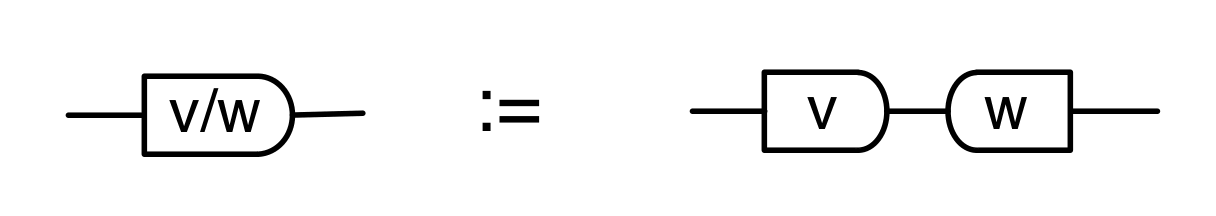



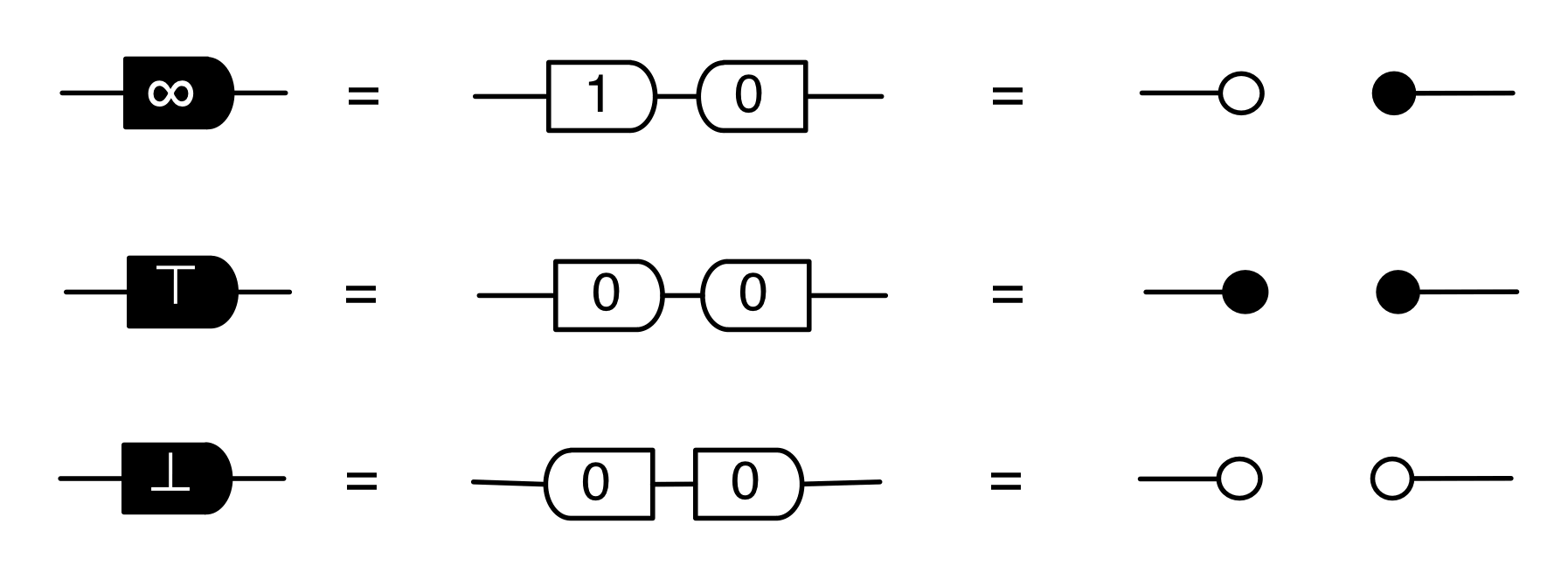




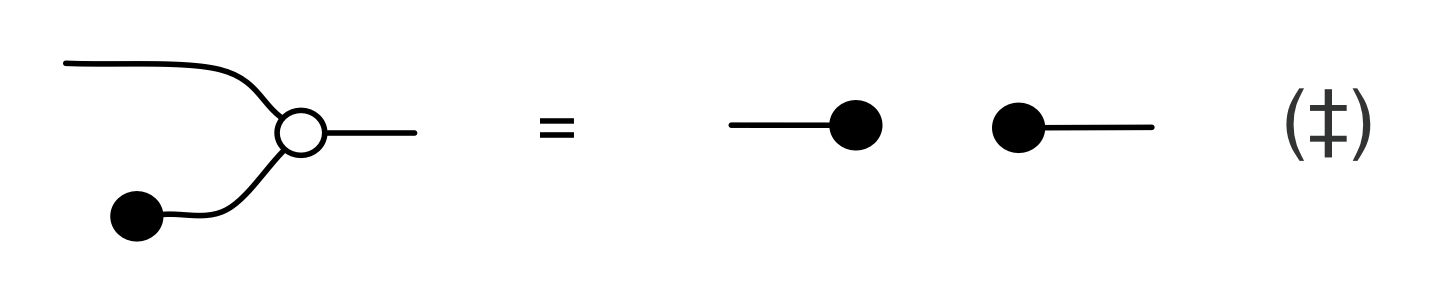

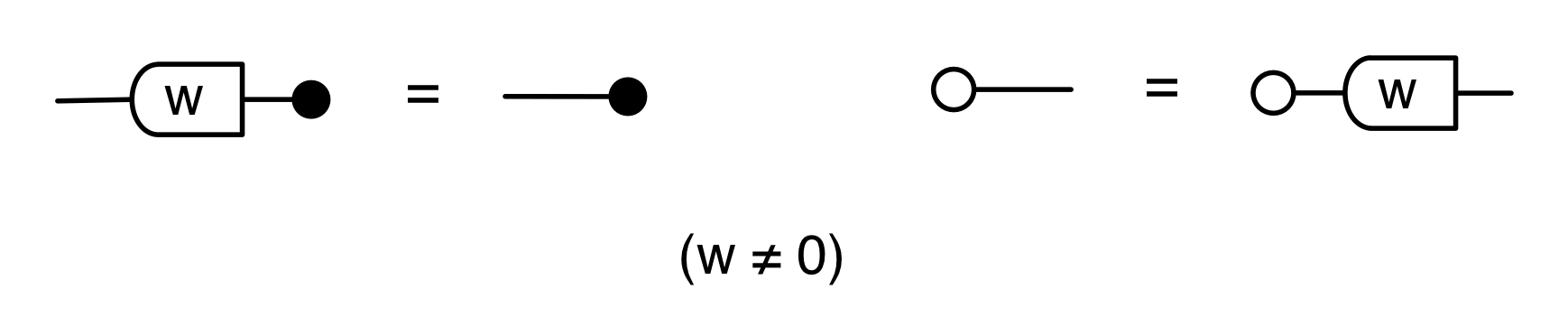





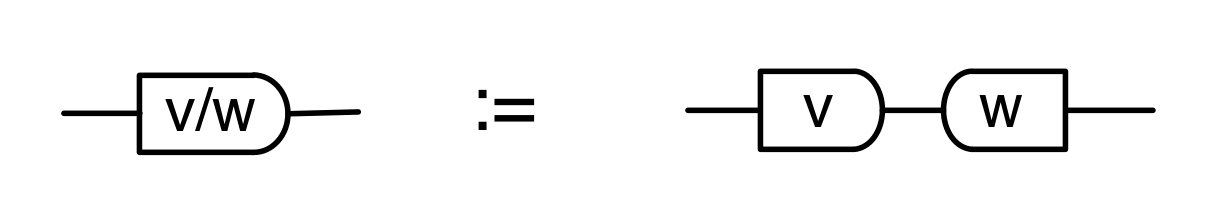





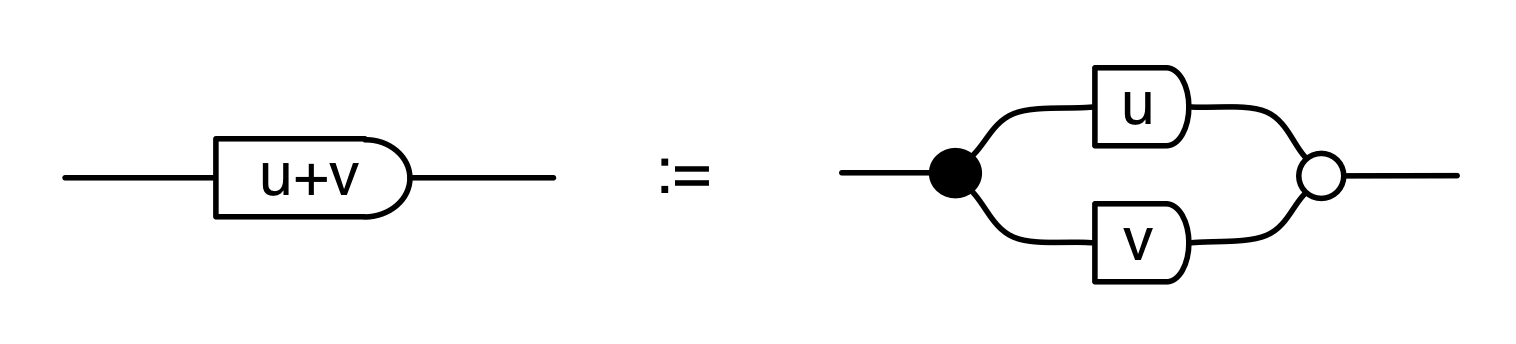

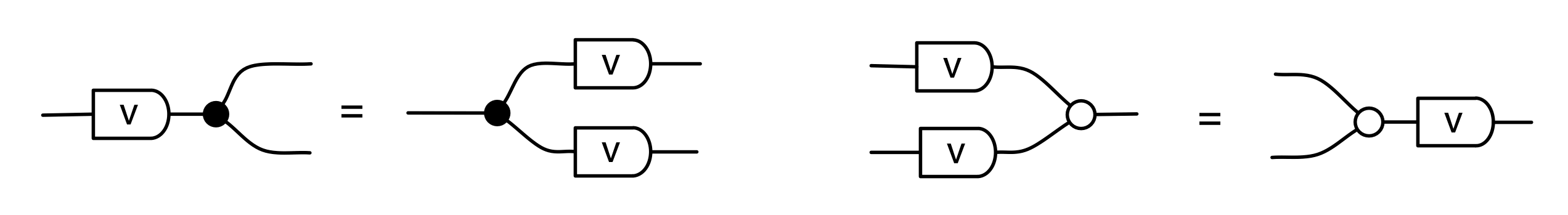





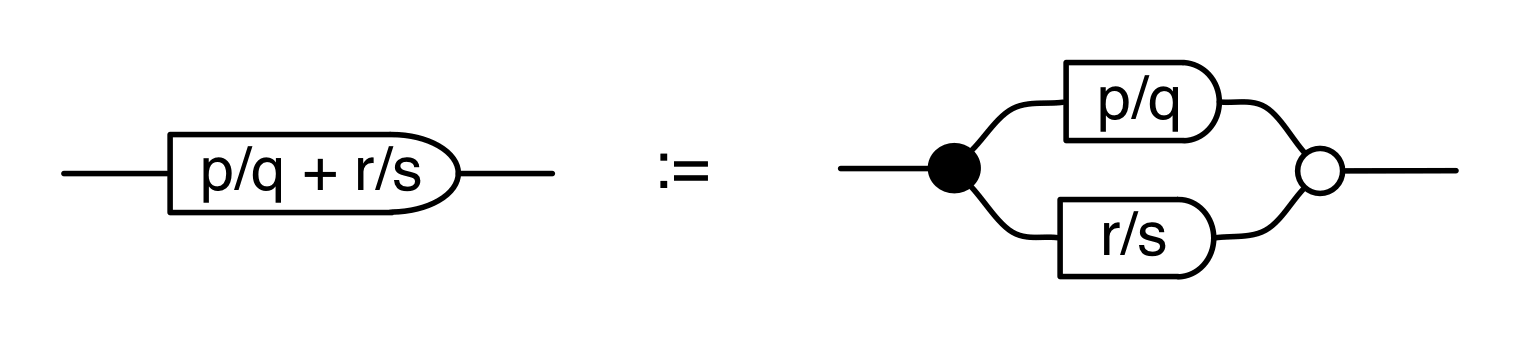


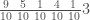 .
.






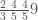 , the
, the 


















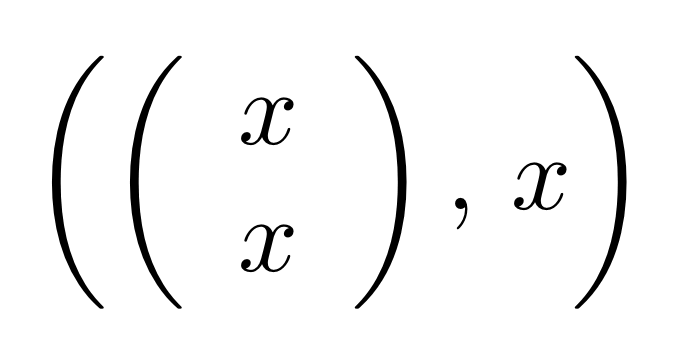












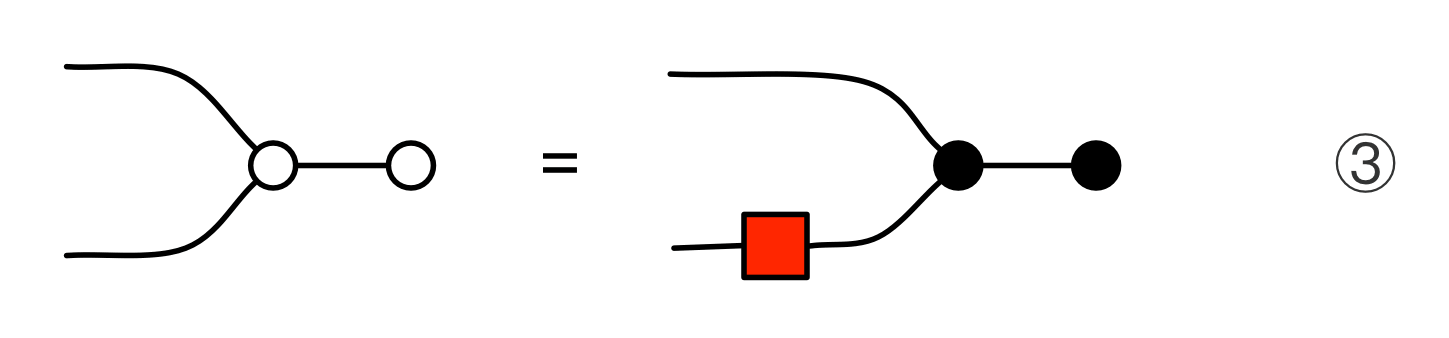
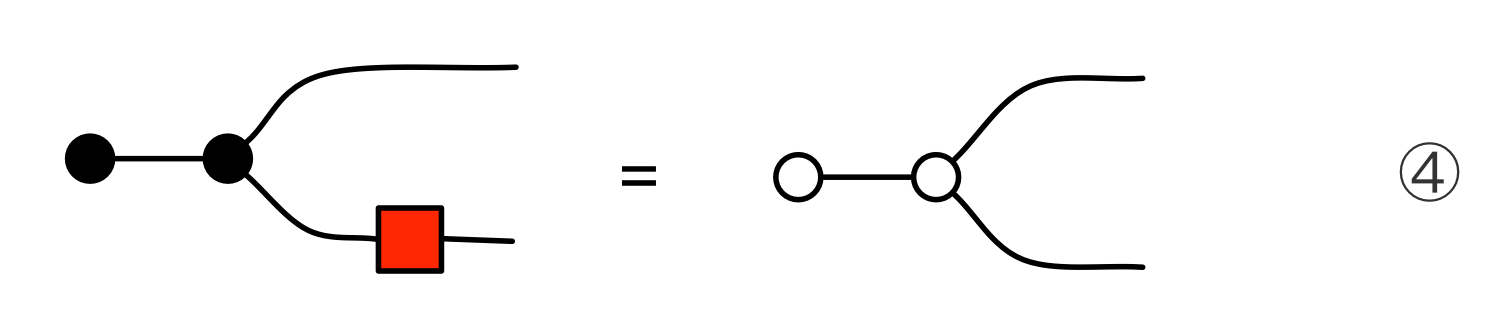

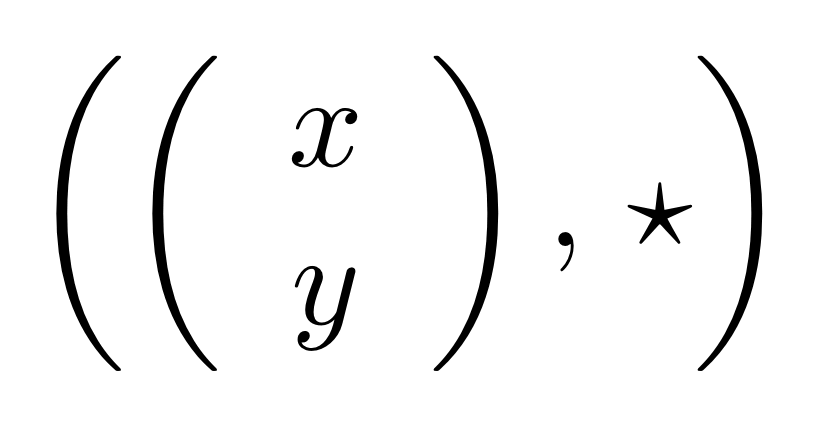





























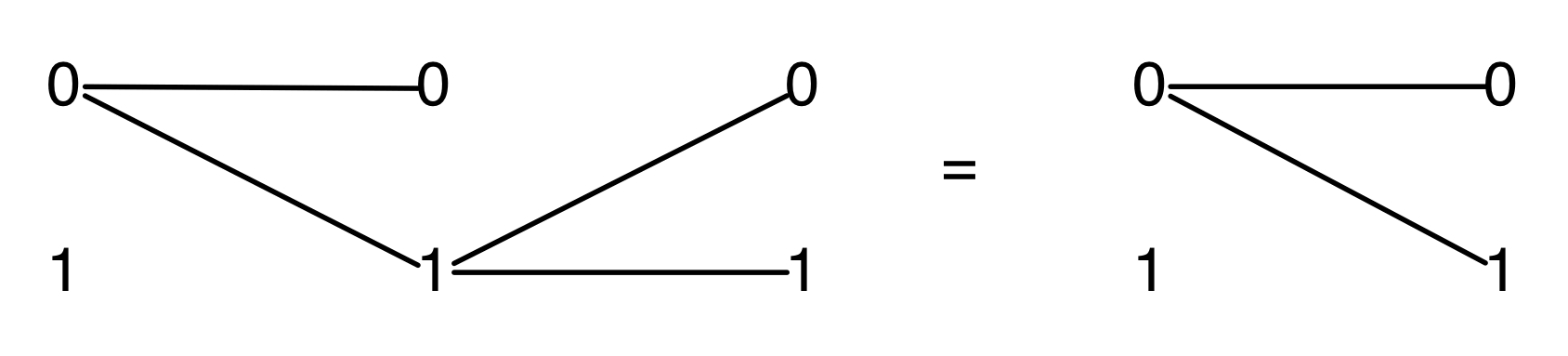
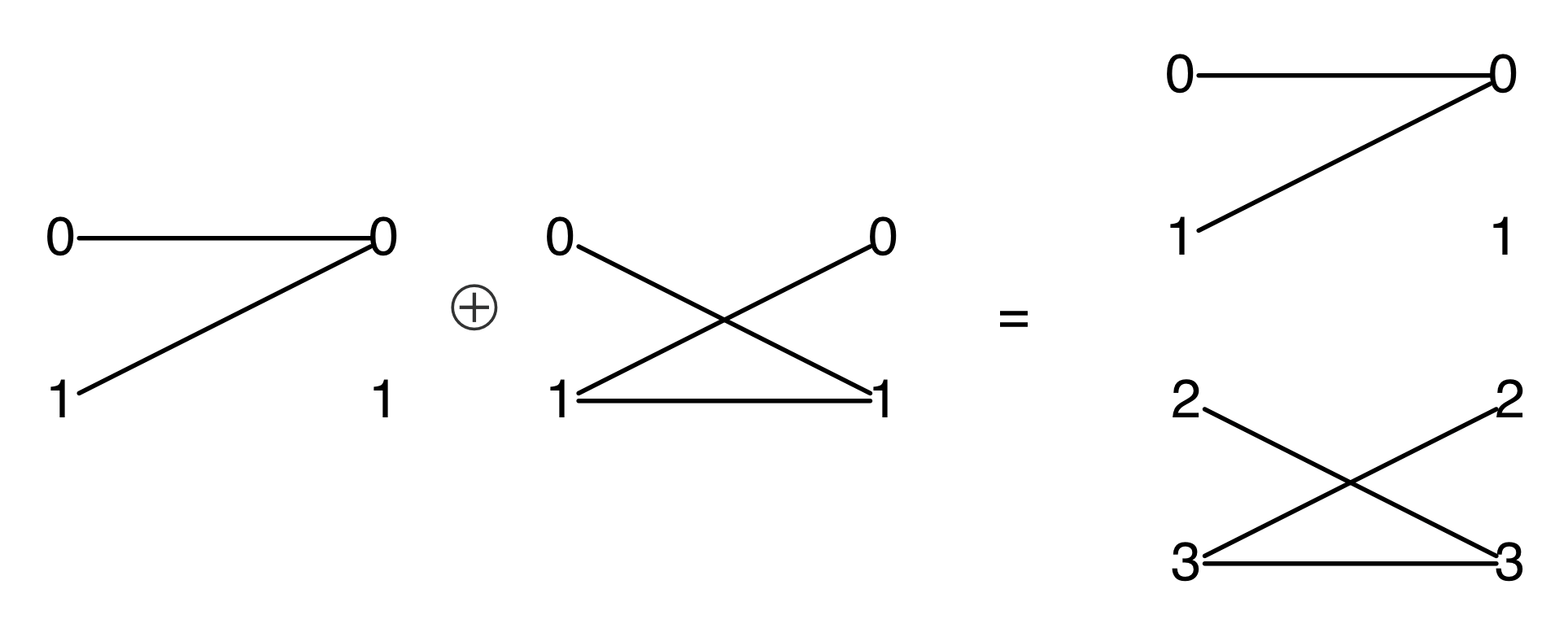






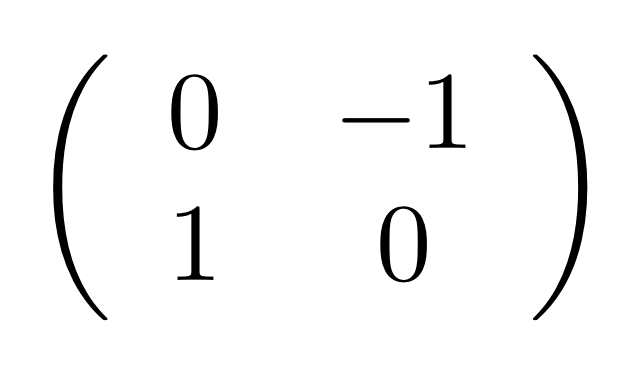















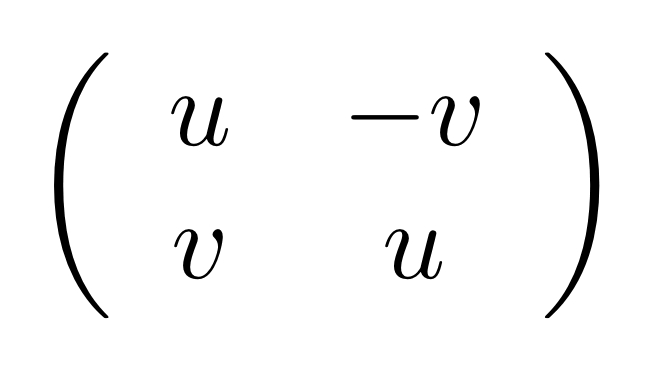


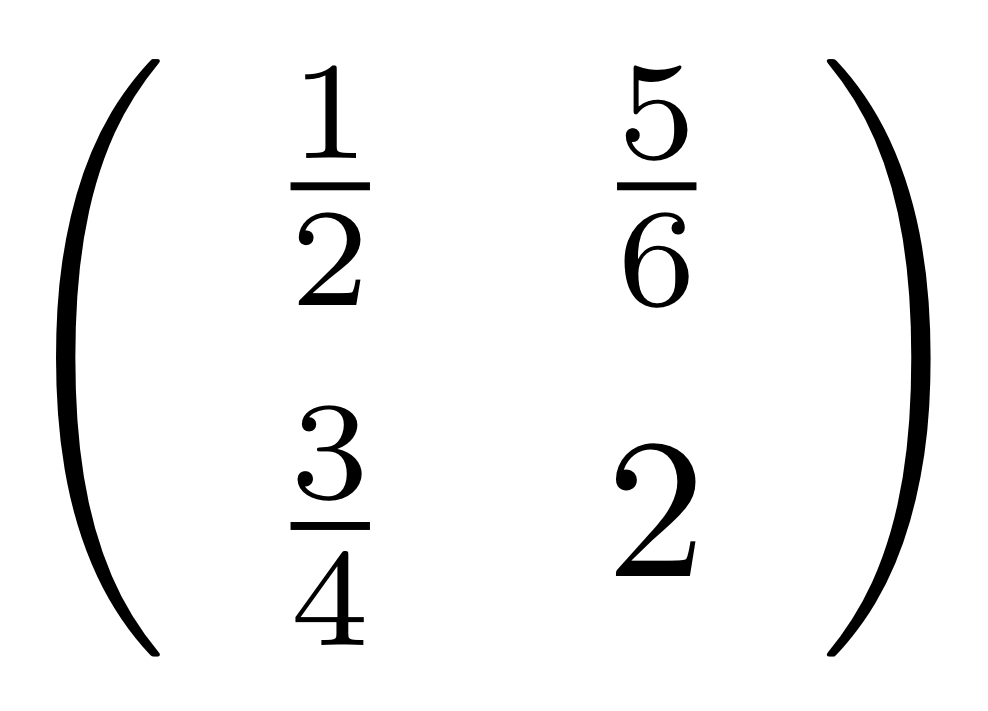{kind=link}
{kind=link}
{kind=link}
{kind=link}
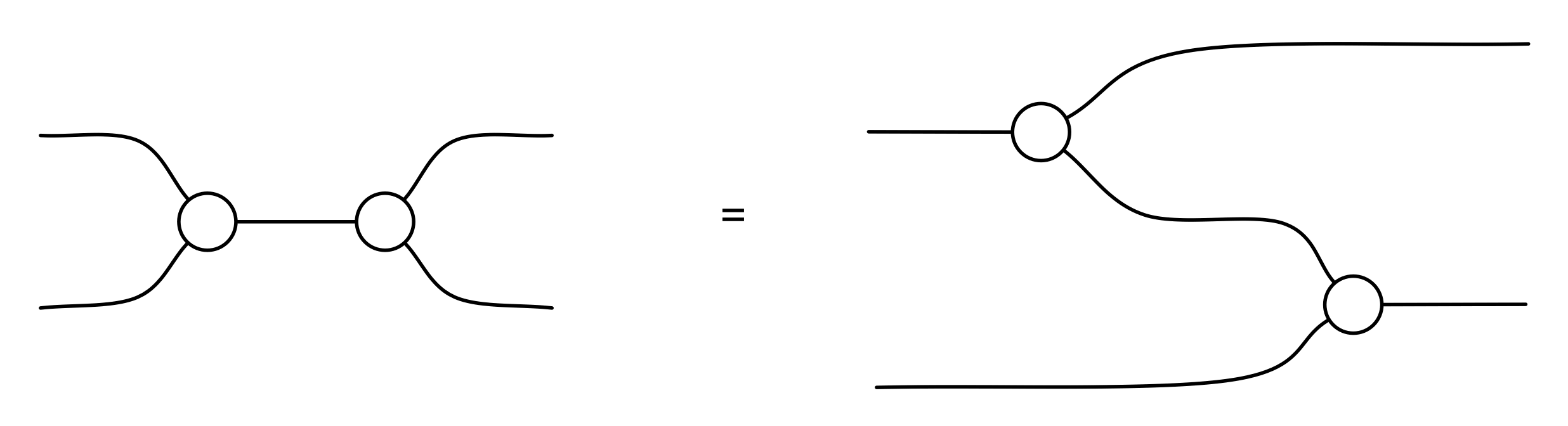{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
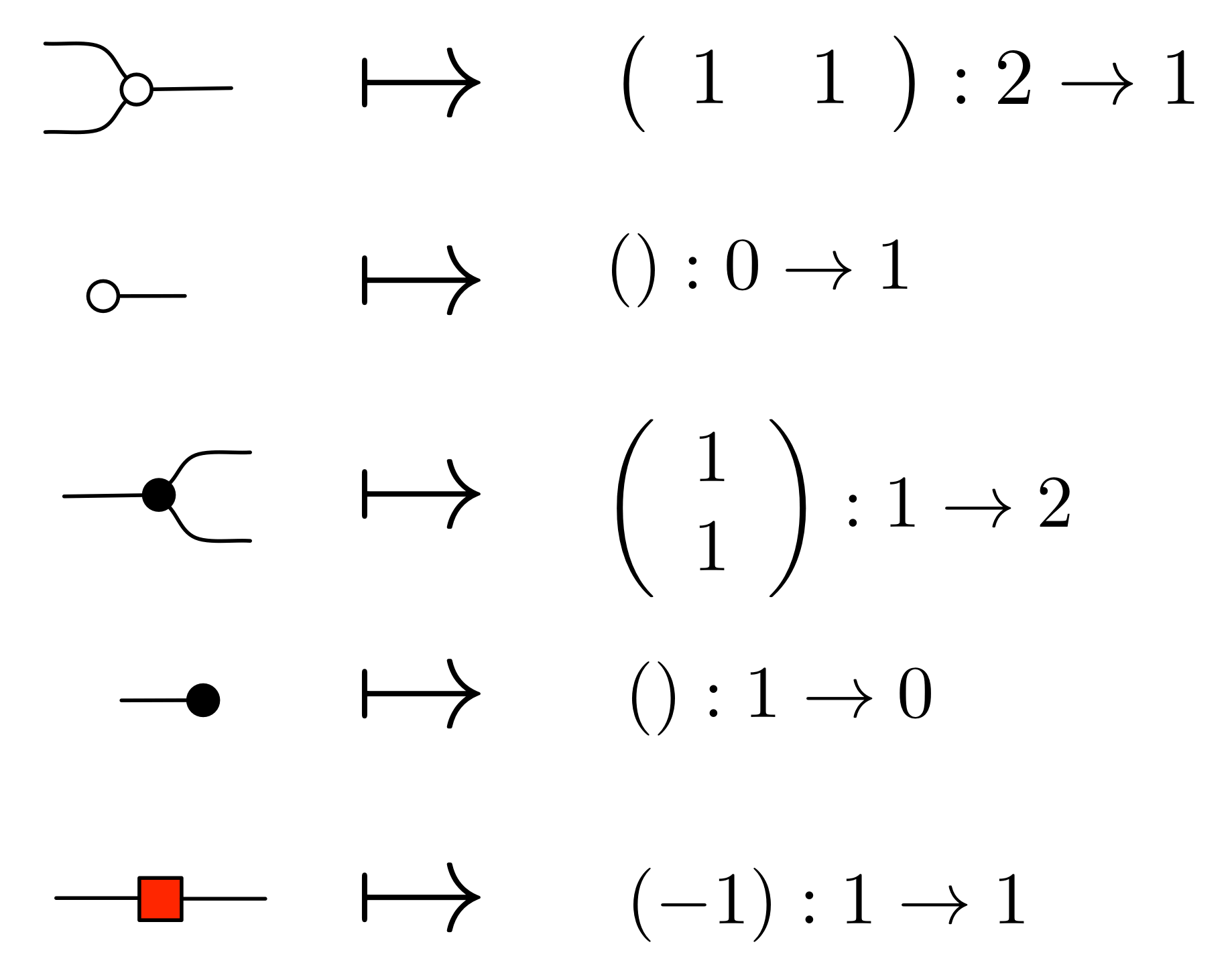{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
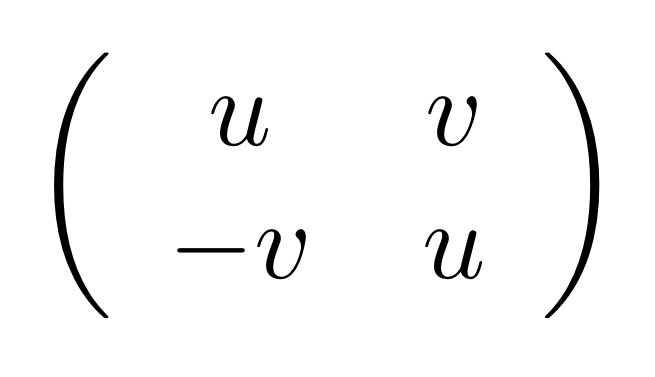{kind=link}