
In the last two episodes we focussed on fairly simple diagrams in IH: those with just one dangling wire on each end. In this episode we expand our horizons and consider arbitrary diagrams. It’s time to return to linear algebra. We will also revisit division by zero from a different, but equivalent, point of view.
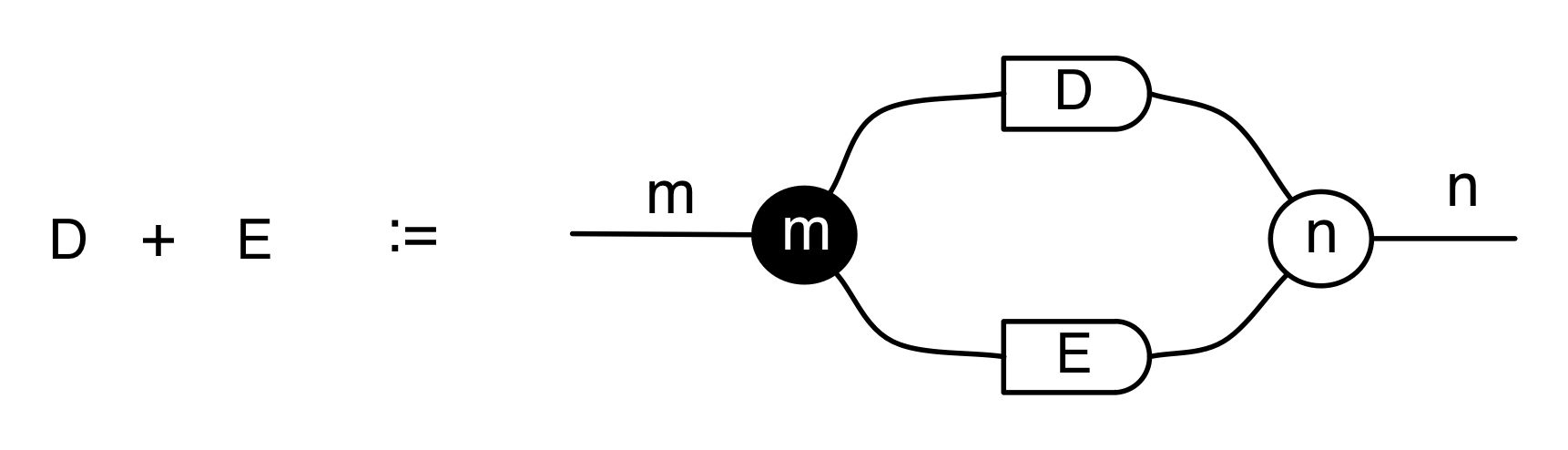
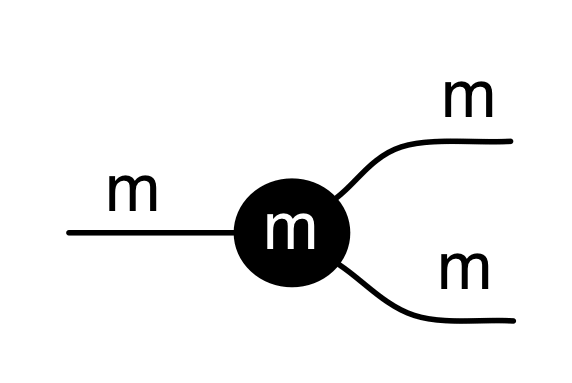
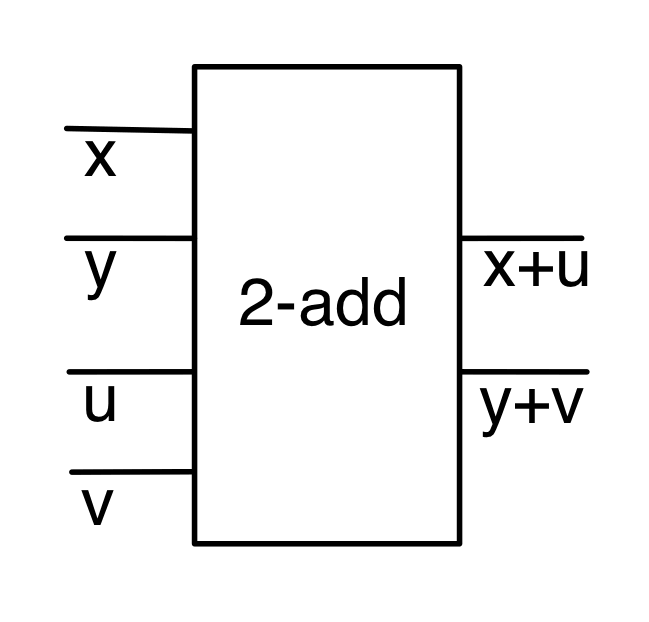
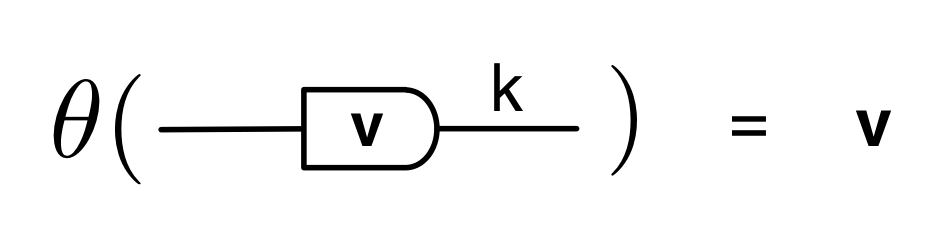
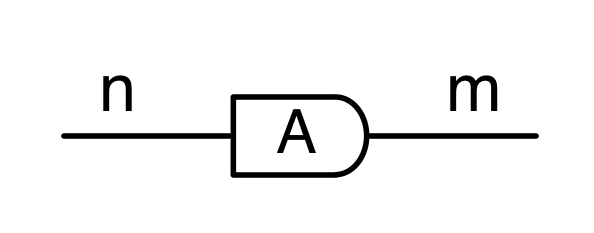
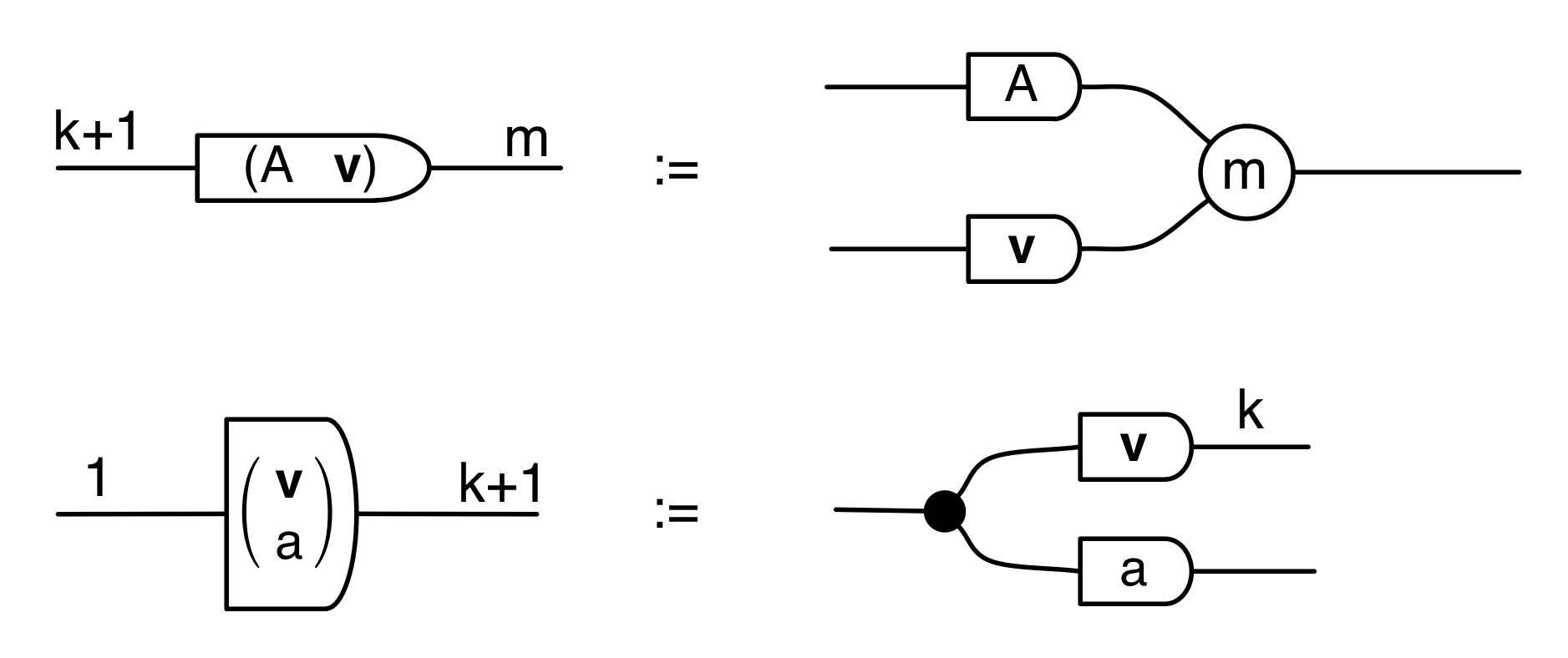
We’ve known since Episode 10 how to handle matrices diagrammatically, and since our expanded graphical language can handle fractions, we can put the two together and draw matrices of fractions. The algebra works as expected: if we restrict our attention to these matrices, composition is matrix multiplication, and the monoidal product of two matrices is their direct sum. Here’s a reminder of how to draw, say, the following matrix
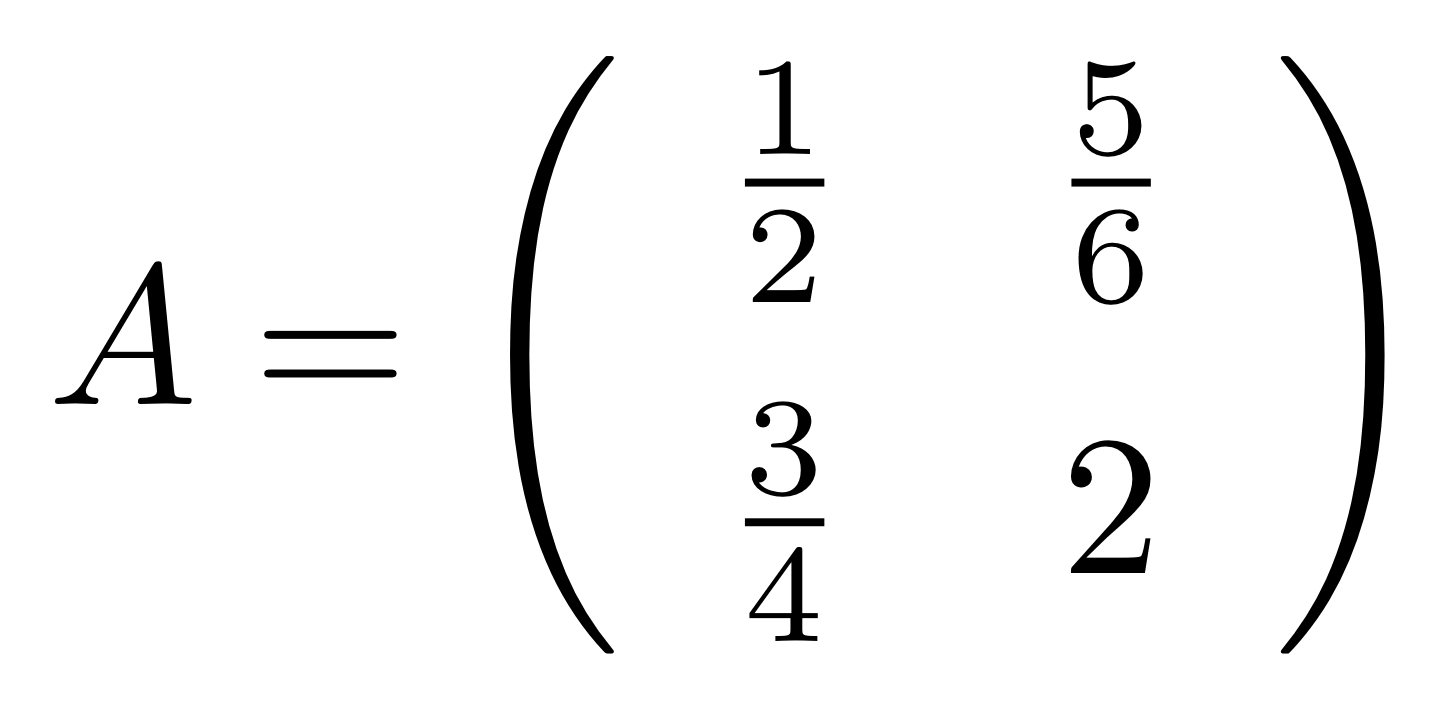
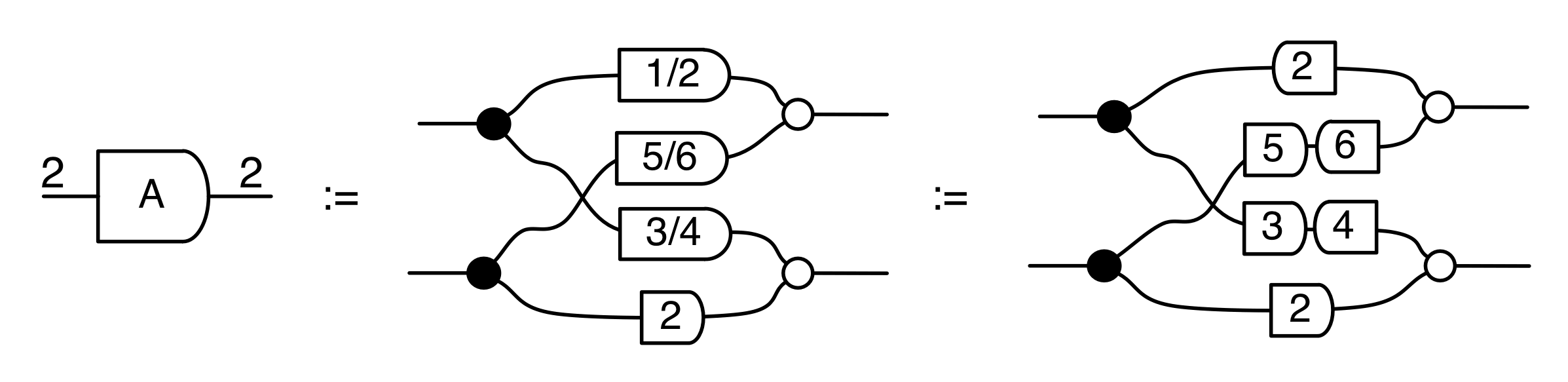
But we can do much stranger things. Since we have the mirror image operation † in our arsenal, we can consider matrices going backwards. We don’t have any traditional notation for this: how could you write a matrix that “goes backwards”? But here’s an example in the language of diagrams, if
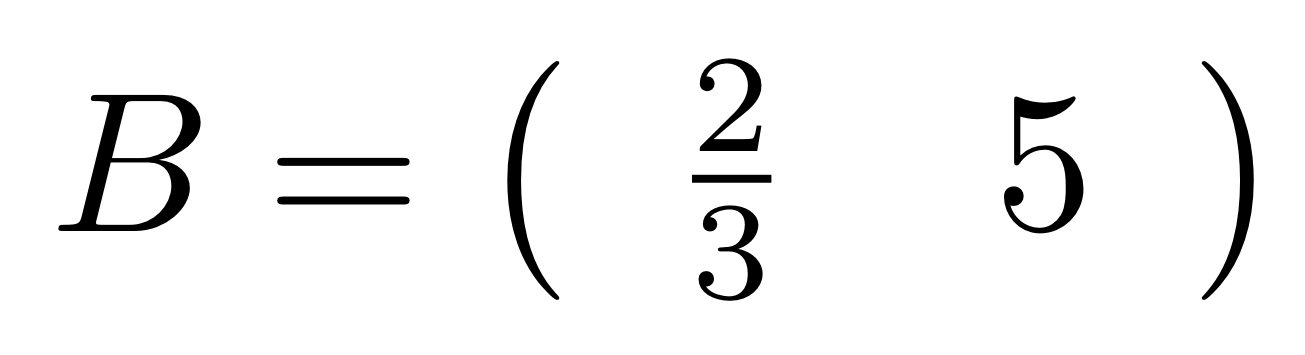
Then we have can draw the diagram for B going from right to left.
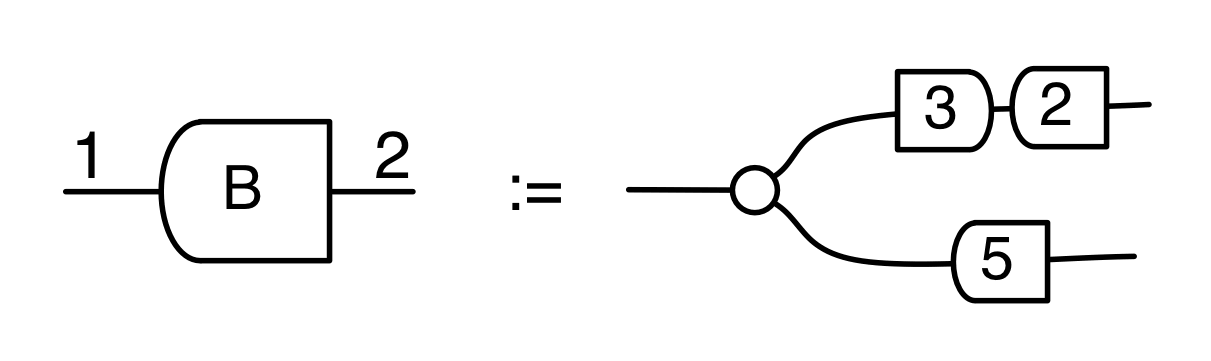
Matrices and backwards matrices are not the full story because diagrams can get more complicated. In general, diagrams from m to k will be quite strange beasts: imagine a zig-zag of matrices going back and forth. It’s as if we took our Lego and got confused about what are the studs and what are the holes. Everything goes.
Let’s clear up the mystery. We know that the sub theories B and H are isomorphic to, respectively, the props Mat of matrices of natural numbers and MatZ of integer matrices. Knowing this helped us to understand the diagrams in those theories, and what they were capable of expressing.
So, without further ado, it’s time to meet the linear algebraic prop LinRel that hides behind the equations of graphical linear algebra. Coincidently it’s my favourite category, so please forgive me if I sound a bit too much like a fanboy in the following. Before we start, we need some notation: in the following, the bold letter Q stands for the set of fractions, aka the rational numbers.
The arrows from m to n in LinRel are linear relations from Qm to Qn. Roughly speaking, LinRel is what happens when you combine matrices and relations. The result is truly delightful; it is much more than the sum of its parts. You will see what I mean.
Before I explain what linear relations are in more detail, let me first say that it’s a huge mystery that the concept of linear relation does not seem to be particularly standard or well-known: there is not even a wikipedia page at the time of writing this episode! Since there’s an informative wikipedia page about, say, Cletus from the Simpsons, this is a bit offensive. Maybe it’s because of a human preference for functional thinking, at the expense of relations? We discussed that a bit in Episode 20.
So what is a linear relation exactly?
First, a linear relation of type Qm ⇸ Qn is a relation, so a subset of the cartesian product Qm × Qn. De-jargonifying, this means that it’s a collection of pairs, with each consisting of an m-tuple and an n-tuple of fractions. For example, the linear relation for the addition generator—which we have already discussed informally in Episode 22—is the relation of type Q2 ⇸ Q that consists of all pairs

where r and s are fractions. We have thus finally demystified what the enigmatic universe of numbers Num is: for now Num = Q, our numbers are fractions.
We still need to account for the word linear in linear relations. Said succinctly, to be linear, a relation R: Qm ⇸ Qn must be a linear subspace of Qm × Qn, considered as a Q vector space. If you don’t know what those words means, let me explain.
First, R must contain the pair of zero columns.
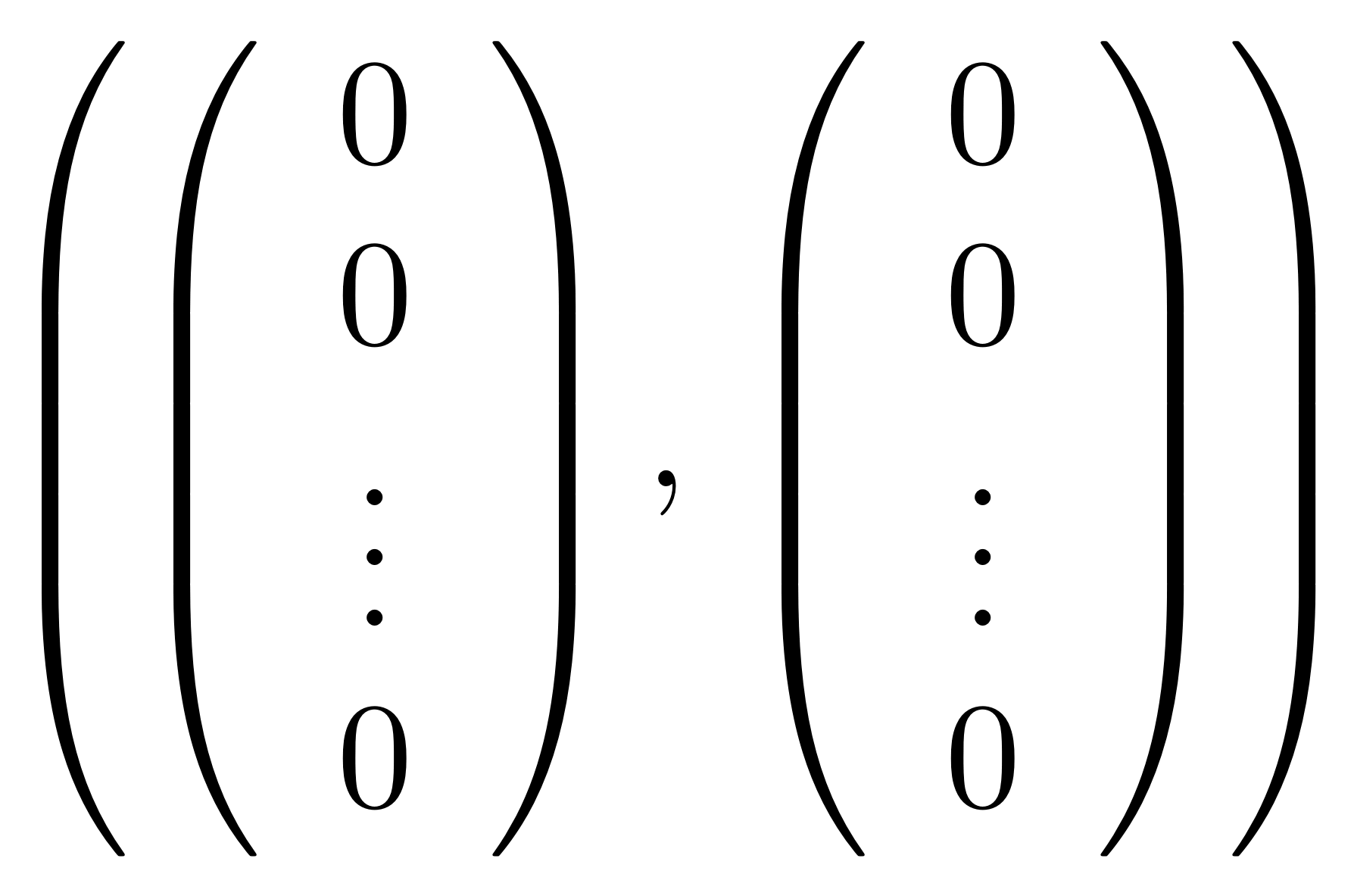
R must also satisfy two additional properties.The first is that it must be closed under pointwise addition. This scary sounding condition is actually very simple: if R contains pairs
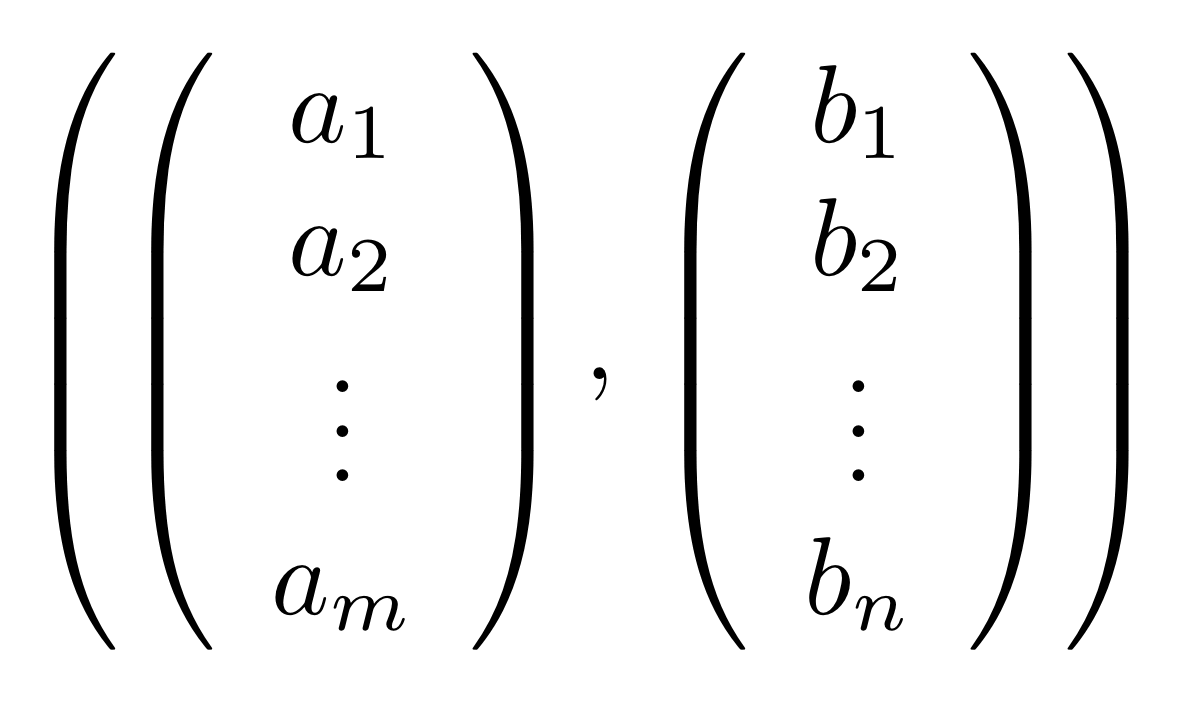
and
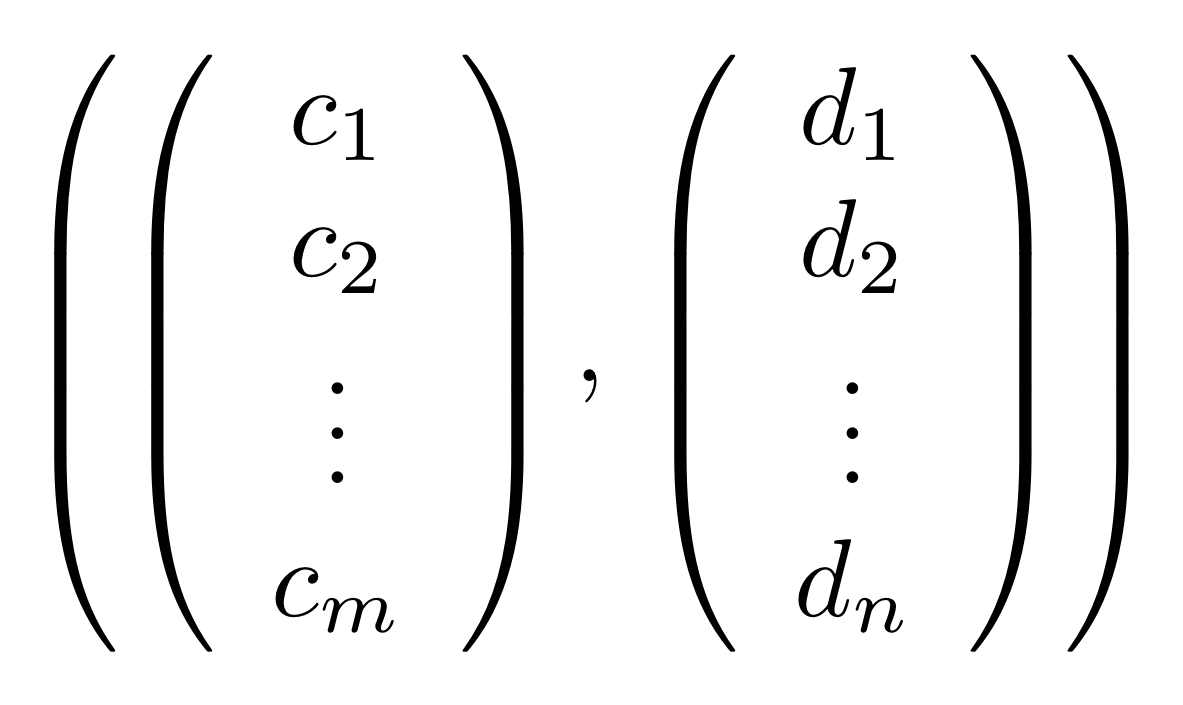
then it also must contain the pair obtained by summing the individual numbers:
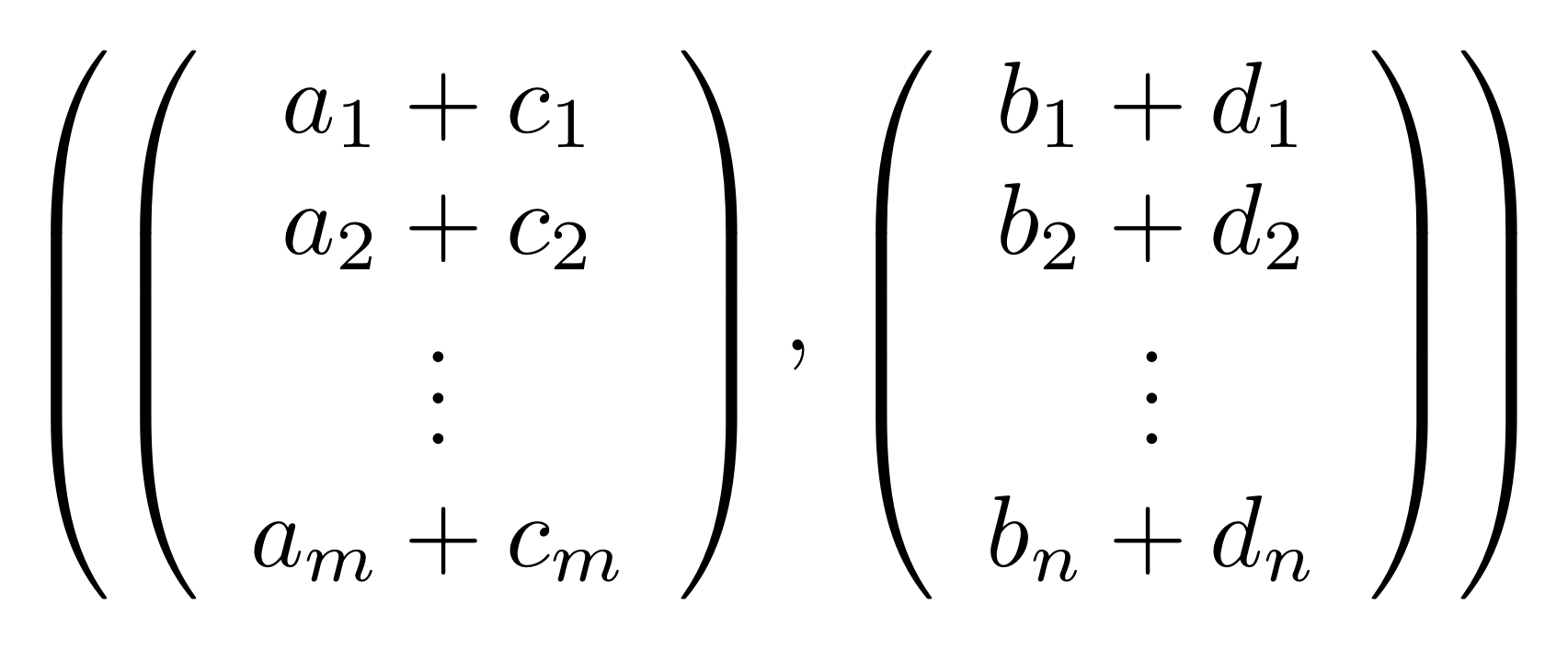 It takes a lot of space to write all those columns, so let’s introduce a common notational shorthand: we will write a for the a-column (or column vector), b for the b-column and so forth. When we write a+c we mean that a and c are columns of the same size and a+c consists of a1+c1, a2+c2 and so on until am+cm. So—using our new shorthand notation—for R to be closed under pointwise addition, whenever (a, b) and (c, d) are both in R then also
It takes a lot of space to write all those columns, so let’s introduce a common notational shorthand: we will write a for the a-column (or column vector), b for the b-column and so forth. When we write a+c we mean that a and c are columns of the same size and a+c consists of a1+c1, a2+c2 and so on until am+cm. So—using our new shorthand notation—for R to be closed under pointwise addition, whenever (a, b) and (c, d) are both in R then also
(a, c) + (b, d) := (a+c, b+d)
must be in R.
The second property of linear relations is that they must be closed under scalar multiplication. This means that whenever
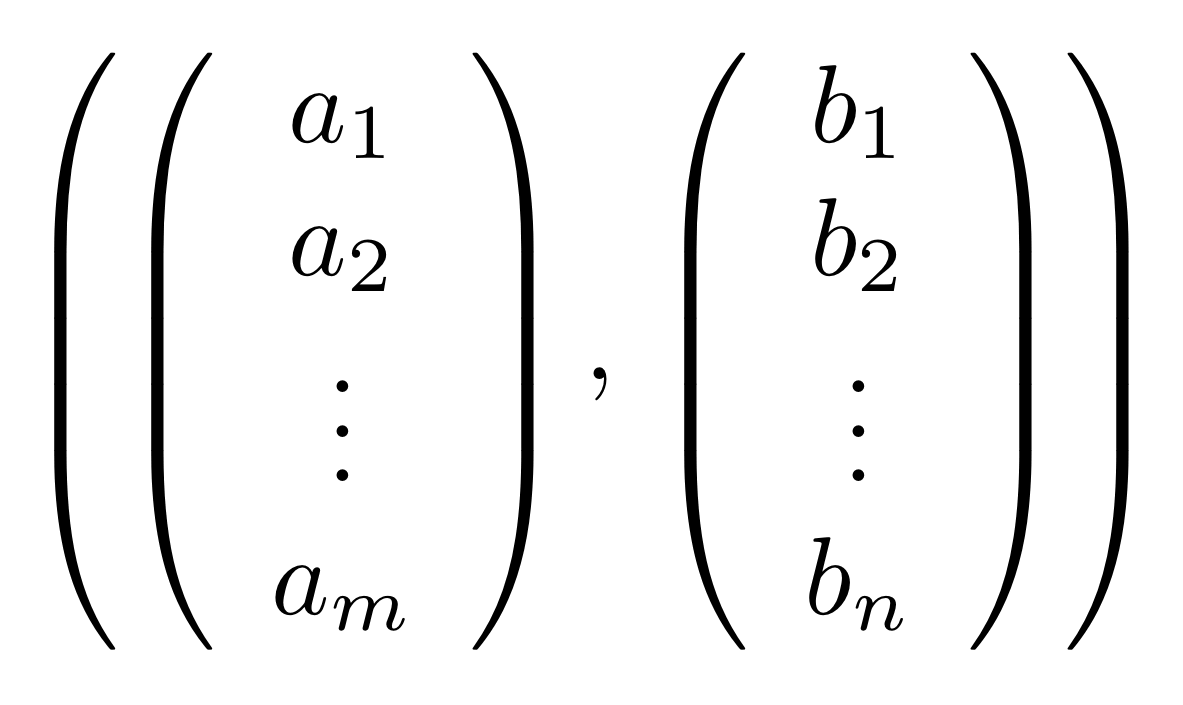
is in R then also

must be a member, where k is any fraction. We can also do say with the shorthand notation: given a vector a and fraction k, we will write ka for the vector with entries ka1, ka2, …, kam. So, being closed under scalar multiplication simply means that if a is in, then ka must also be in.
Composition in LinRel works just like it does in Rel, so composing R: Qm ⇸ Qn and S: Qn ⇸ Qp gives R;S : Qm ⇸ Qp with elements (x, z) precisely those for which we can find a y such that (x, y) is in R and (y, z) is in S.
I claim that LinRel is a prop. To be sure, we need to do some things that may not be immediately obvious:
- verify that the identity relation is a linear relation,
- check that composing two linear relations results in a linear relation, and
- say what the symmetries are and make sure that they work as expected.
The first one is easy, try it!
For point 2, we need to show that if R: Qm ⇸ Qn and S: Qn ⇸ Qp are linear relations then so is R;S.
Let’s prove closure under pointwise addition: suppose that (x1, z1) and (x2, z2) are in R;S. We need to show that (x1+x2, z1+z2) is also in R;S. Using the definition of relational composition, there exist y1, y2 such that (x1, y1) and (x2, y2) are both in R and (y1, z1) and (y2, z2) both in S. Since R and S are linear relations, they are both closed under pointwise addition, so we can conclude that (x1+x2, y1+y2) is in R and (y1+y2, z1+z2) is in S. It thus follows that (x1+x2, z1+z2) is indeed in R;S. I’ll leave you to check that it’s closed under scalar multiplication, the argument is very similar.
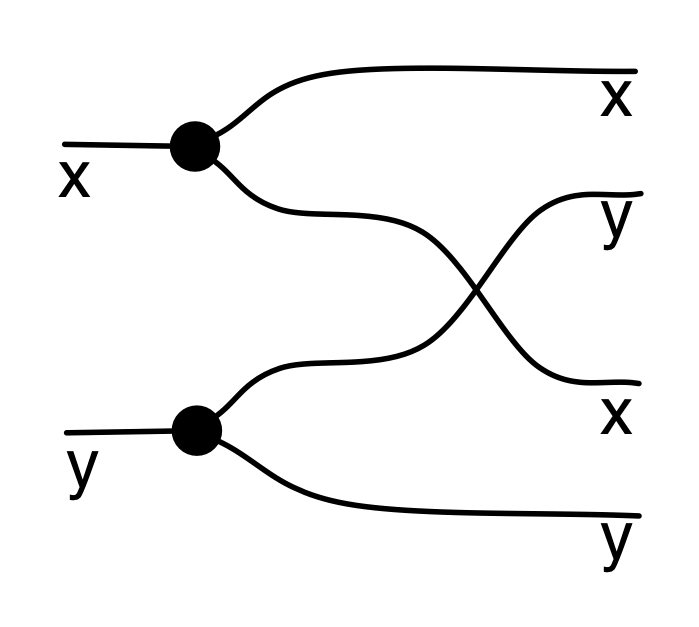
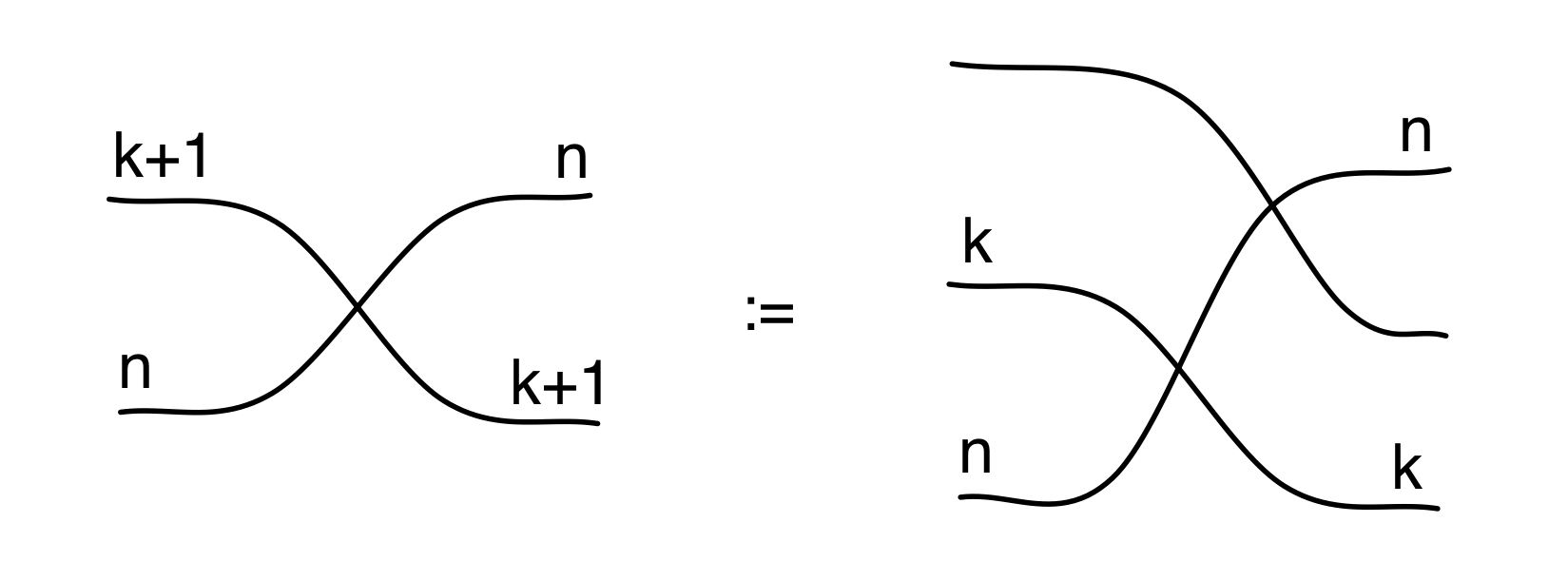
For point 3, for now I’ll just tell you what the relation for the twist 2 → 2 is and hope that it gives you the general idea. The twist in LinRel is the smallest linear relation that contains the elements
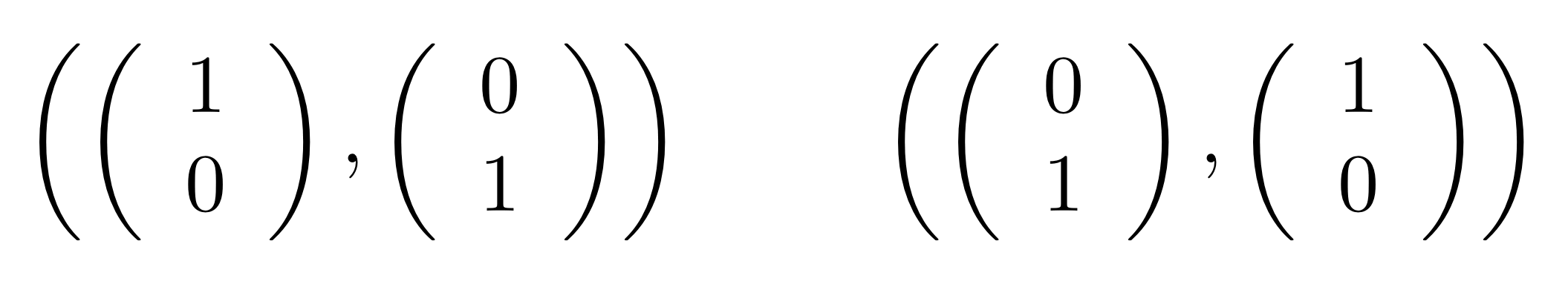
Since we need to close under addition and scalar multiplication, elements in this relation will look like
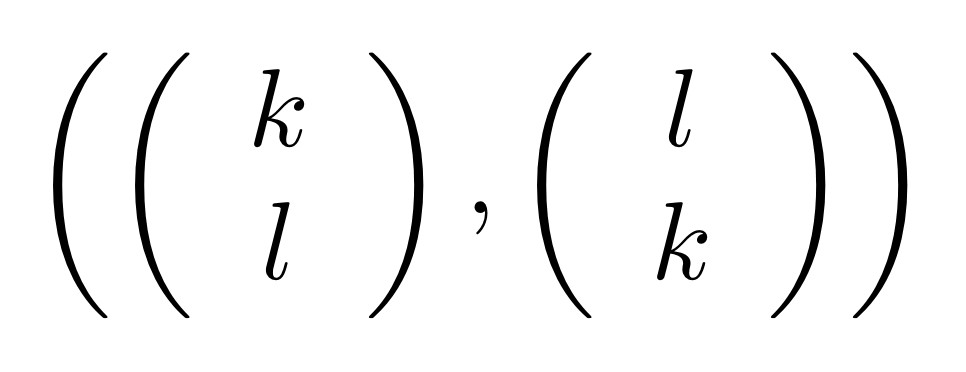
where k and l are fractions.
We have already discussed the relational semantics of the generators in Episodes 22, 23 and 24 and verified that the equations make sense, relationally speaking. It is not difficult to check that each of the relations is linear. Long story short, this assignment of relations to generators defines a homomorphism of props
IH → LinRel.
As we will eventually prove, this is an isomorphism; it is both full and faithful.
The proof of IH ≅ LinRel is quite a bit more involved than the proof B ≅ Mat and H ≅ MatZ. We will eventually go through it in detail—apart from following our principle of not handwaving, the proof is quite informative. But for now, LinRel and its diagrammatic presentation IH are perfect playgrounds for linear algebra and that’s what we will concentrate on over the next few episodes.
In the last episode we discussed how (1, 1) diagrams allowed us to divide by zero. By looking at the corresponding situation in LinRel, we can shed some more light on this curiosity. So let’s take a look at linear relations Q ⇸ Q: since IH ≅ LinRel these are in 1-1 correspondence with (1, 1) diagrams. We can plot linear relations of this type using conventional graphical notation, thinking of the domain as the horizontal x axis and the codomain as the vertical y axis.
Since every linear relation must contain the pair that consists of zero columns, every plot will contain the point (0,0). In fact, the singleton {(0,0)} is itself a linear relation: clearly it satisfies the two required properties. Here’s its plot.

The diagram for this linear relation is
which we dubbed ⊥ in the last episode. Next up, the entire set Q×Q is a linear relation. Here we colour the entire plane red. Sorry for the eye burn.

The corresponding diagram is

which we were calling ⊤ last time. These two linear relations give some justification for the names ⊥ (bottom) and ⊤ (top), since the former is—set theoretically speaking—the smallest linear relation of this type, and the latter is the largest.
The other linear relations are all lines through the origin. So, for example, the plot for the identity diagram
 is the line with slope 1.
is the line with slope 1.

All the fractions arise like this. For example, the line for the fraction –1/2, diagrammatically
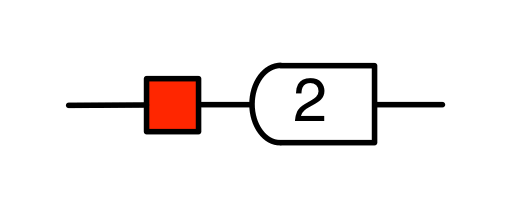
is the line with slope –1/2
You get the idea for the other fractions.
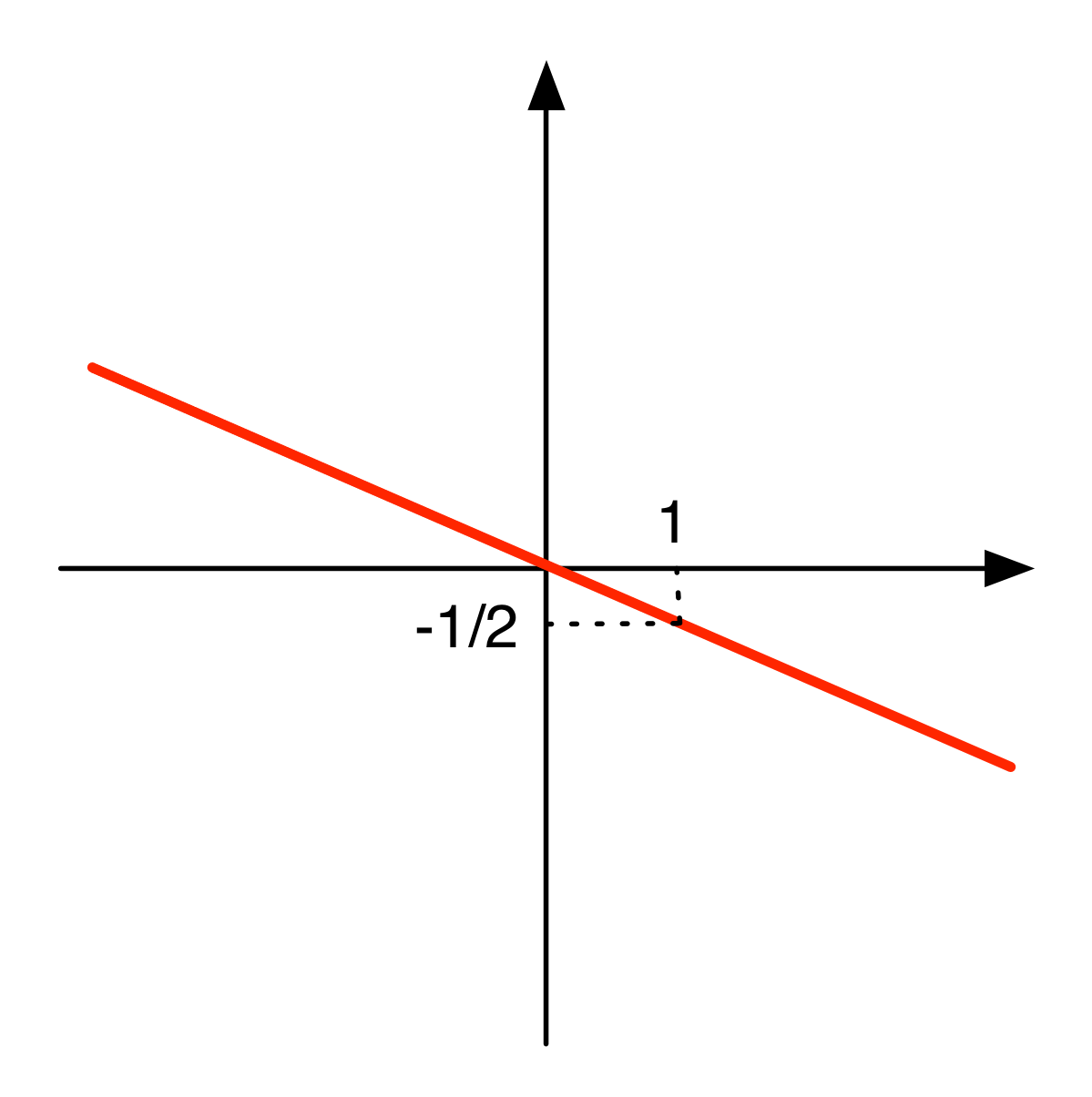
There are two lines that represent interesting corner cases. The first is the line for 0
 which is the line with zero slope, that is, the x-axis.
which is the line with zero slope, that is, the x-axis.
Finally, there’s the line with “infinite” slope, the y-axis.
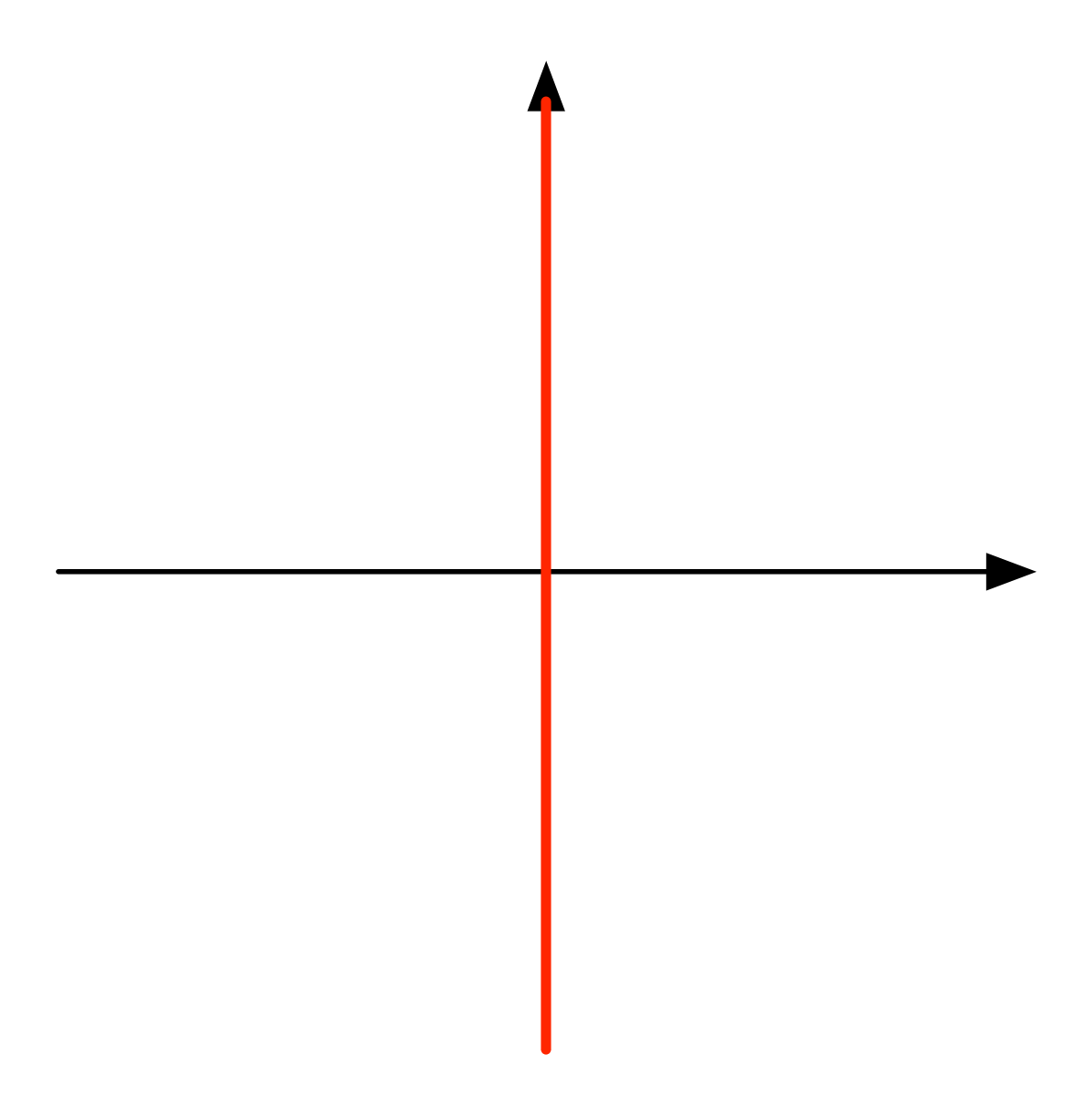
which is the plot for

that we called ∞ in the last episode.
If we think relationally, then the operations x+y, x×y and 1/x are all easy to define, and are total on the set of linear relations Q ⇸ Q. Multiplication is simply relational composition, and 1/x is the opposite relation x†. Finally, addition can be defined set theoretically as
x + y = { (a, c) | there exist (a, b1) in x and (a, b2) in y such that b1+b2 = c }.
The above definition simply mimics the sum operation, as we have been doing with diagrams. So we could reconstruct the addition and multiplication tables from the last episode by working directly with linear relations.
Identifying numbers with lines through the origin is an old idea. It is one way to understand projective arithmetic. What is not so well-known is that we can define the arithmetic operations directly on the underlying linear relations, and moreover, throwing ⊤ and ⊥ into the mix makes the operations defined everywhere, with no need for dividebyzerophobia. If you have seen this done somewhere else, please let me know!
Here’s one very cool fact about LinRel, and it concerns the mirror image symmetry †. Remember that if R is a relation then R† is the opposite relation: (b, a) is in R† exactly when (a, b) is in R. In the last episode we saw that for any (1,1) diagram d we have
d;d†;d = d.
It turns out that this works for arbitrary linear relations. Thus R† is always the weak inverse of R. This is something that will be very useful for us in the future. Let’s prove it.
Suppose that D is some linear relation. Since D;D†;D and D are both sets (of pairs), to show that they are equal it’s enough to show that each is a subset of the other. It is easy to show that every element of D must be an element of D;D†;D, since, taking (a,b) in D, the chain of elements (a,b), (b,a), and (a,b) proves that (a,b) is in D;D†;D.
We just need to show that the opposite inclusion also holds. So suppose that (a, d) is in D;D†;D. By definition, there are b, c such that (a, b) is in D, (b, c) is in D† and (c, d) is in D. And since (b, c) is in D†, (c, b) is in D.
Now, using the fact that D is a linear relation that contains (a, b), (c, b) and (c, d), we have that
(a, b)-(c, b)+(c, d) = (a–c+c, b–b+d) = (a, d)
is in D.
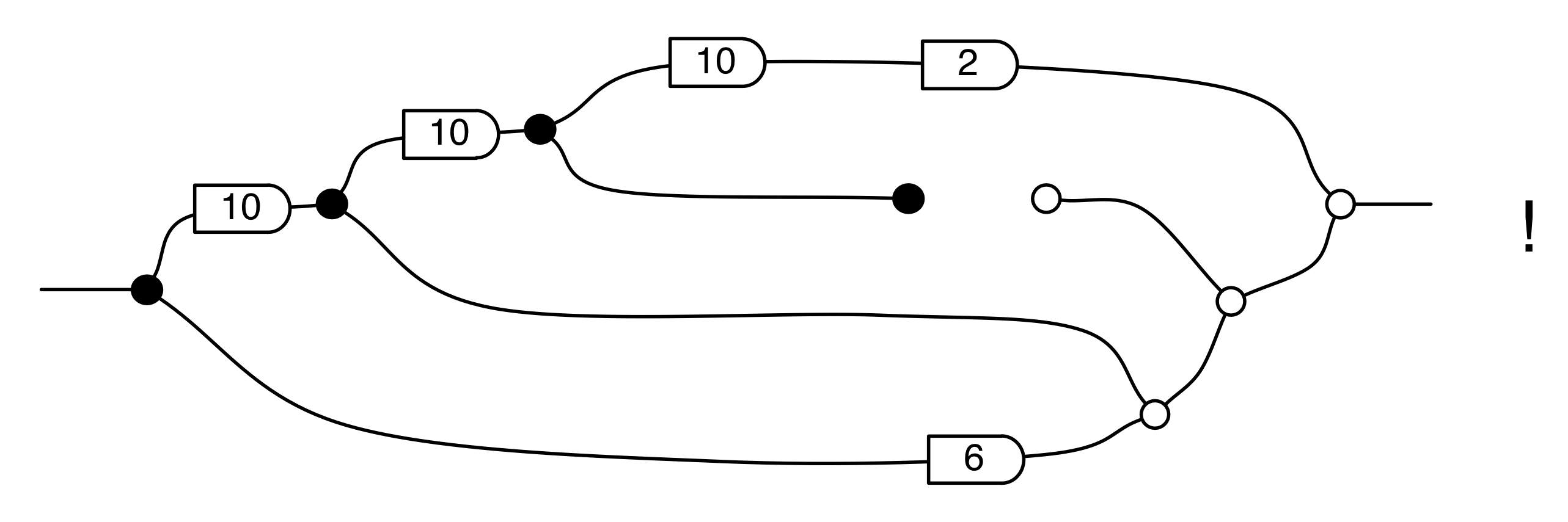
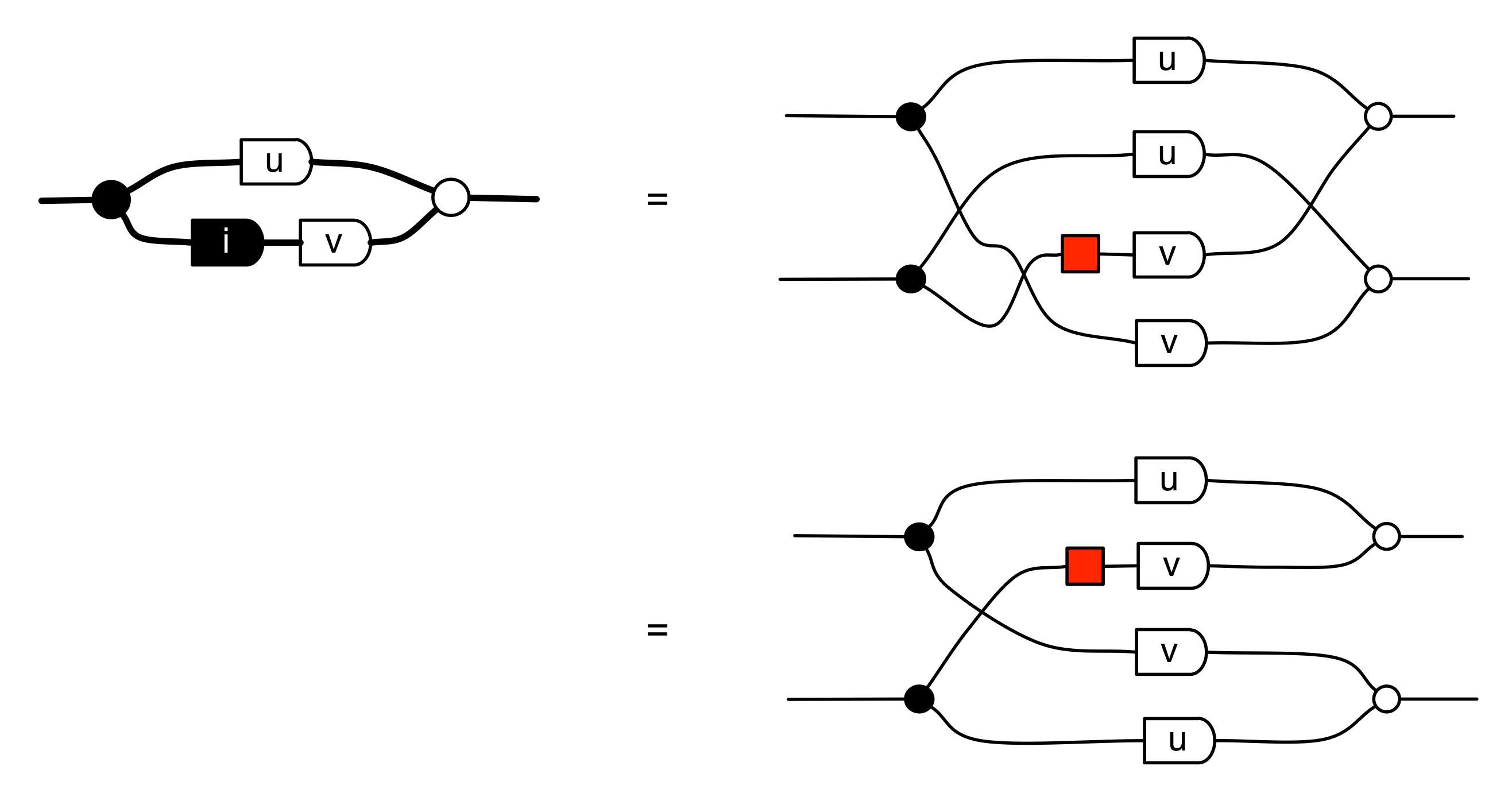
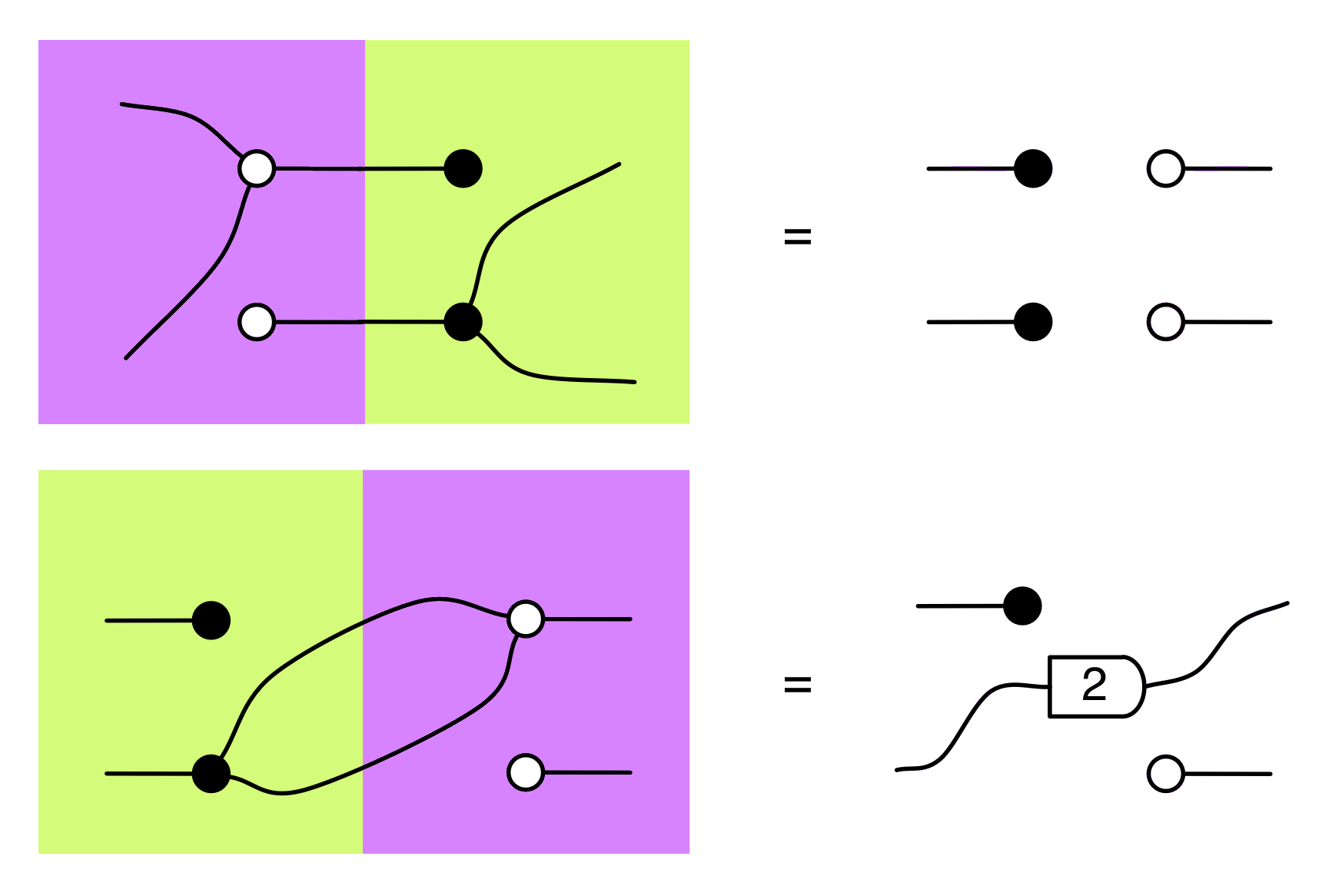
The fact that D;D†;D is not larger than D is one thing that’s special about linear relations: it is not true for ordinary relations! For example, think about what happens to this relation 2 ⇸ 2:

Today is Boxing Day, so this is a Christmas special episode of the blog. The next one will probably arrive in January, so let me take this opportunity to wish everyone a fantastic
Continue reading with Episode 28 – Subspaces, diagrammatically.



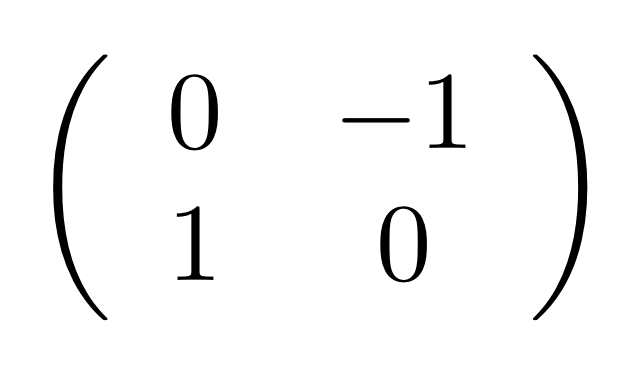




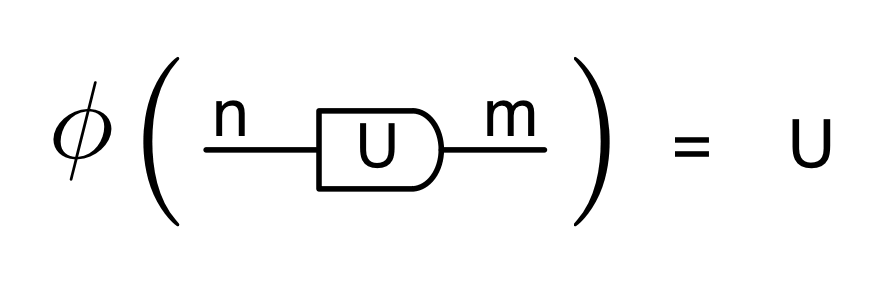











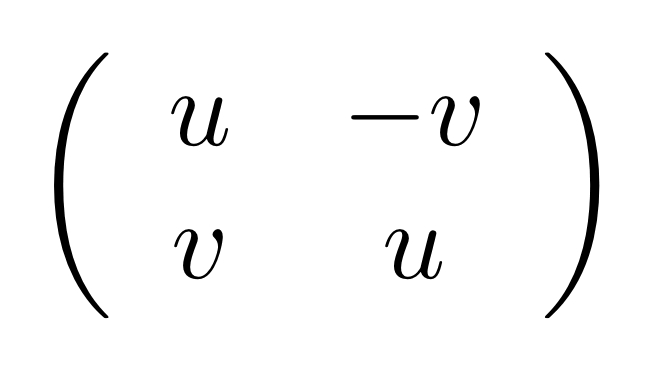





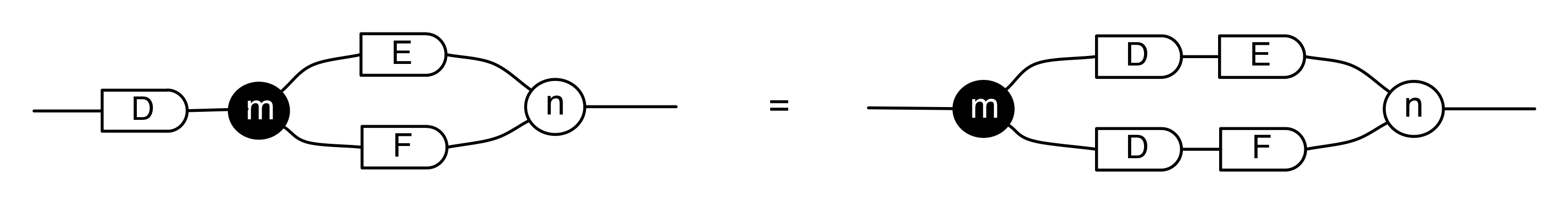


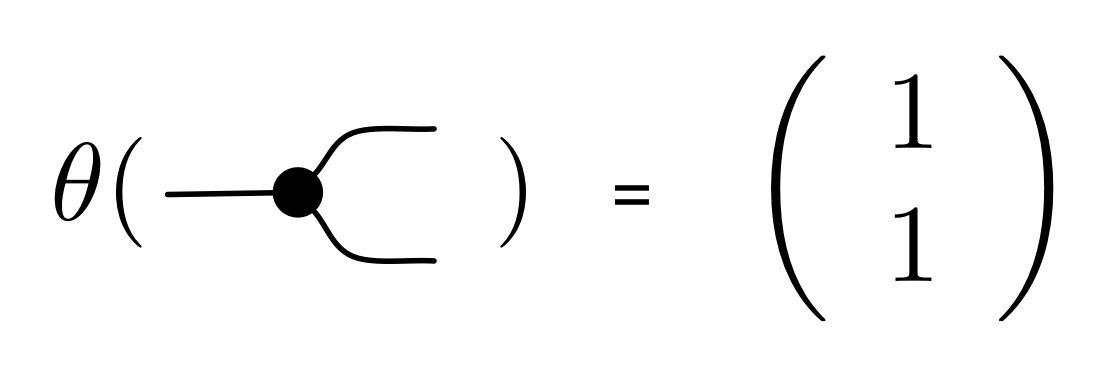
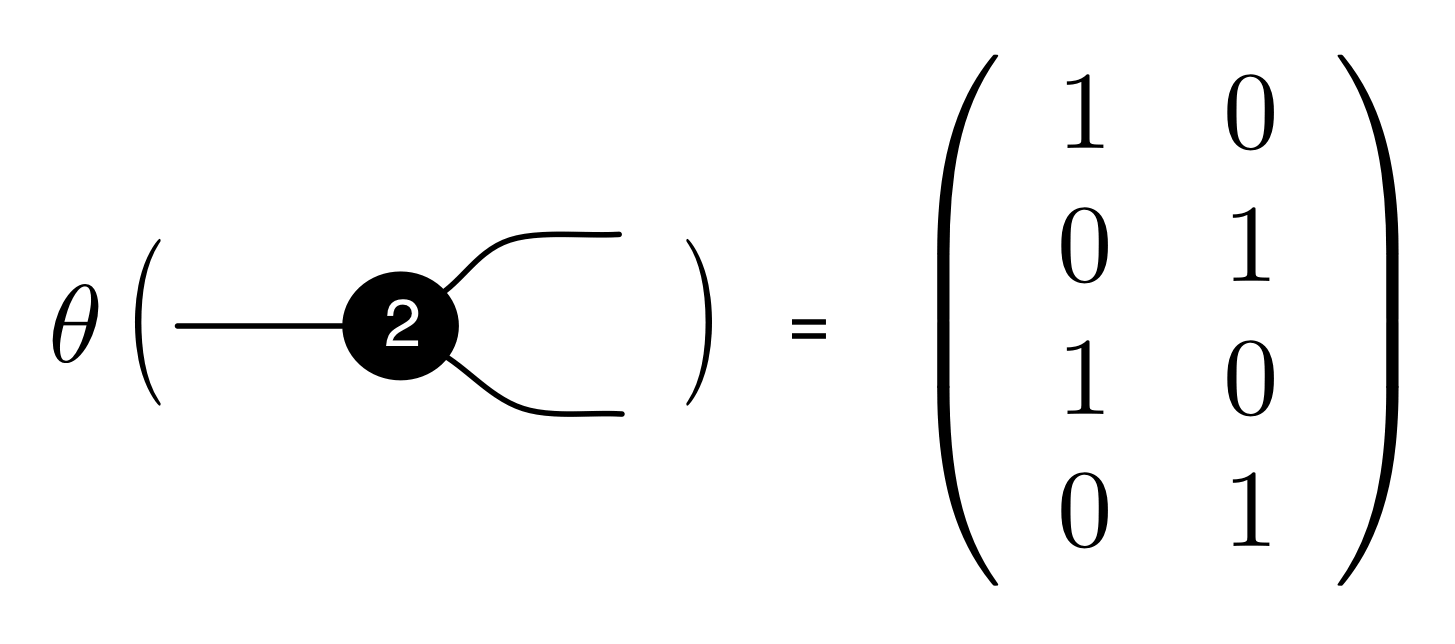

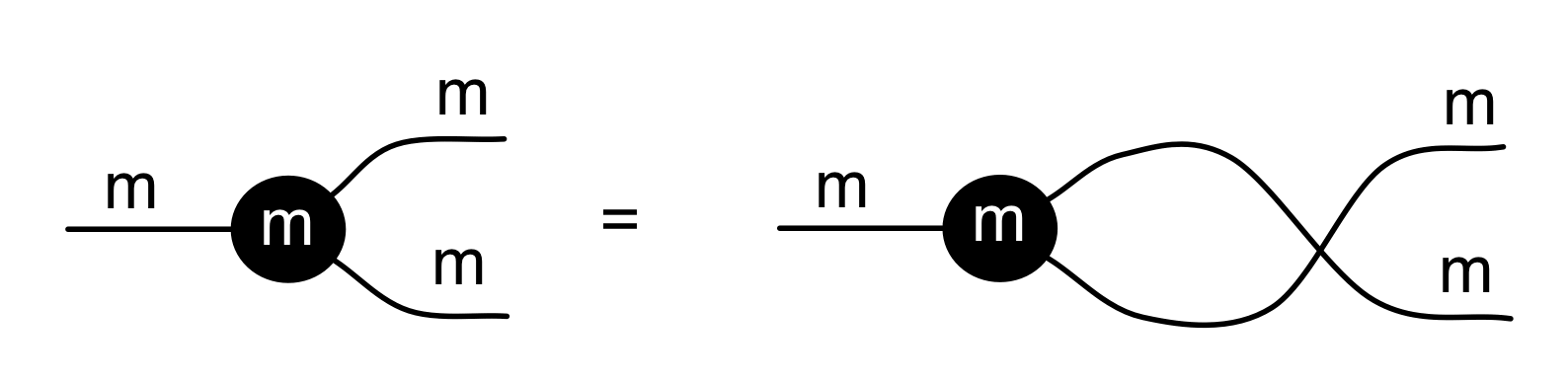
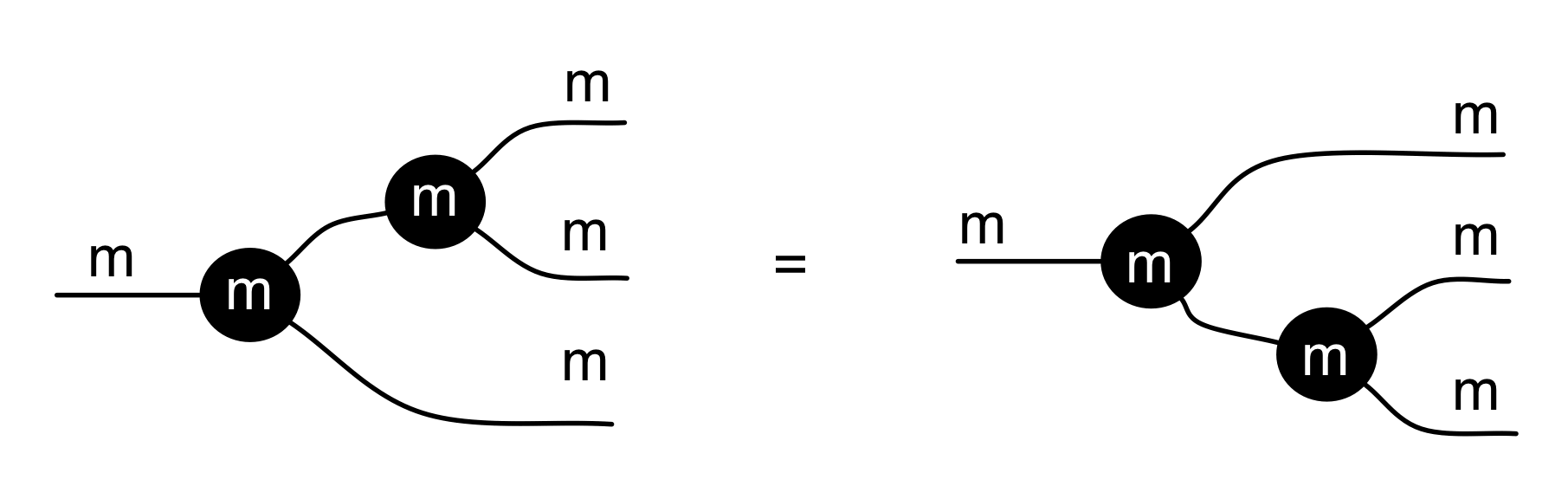
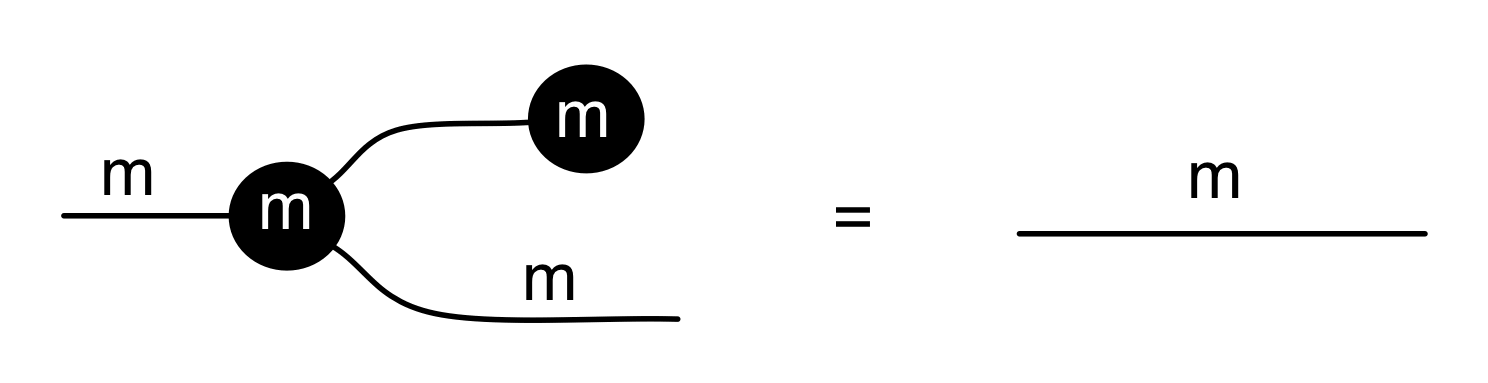
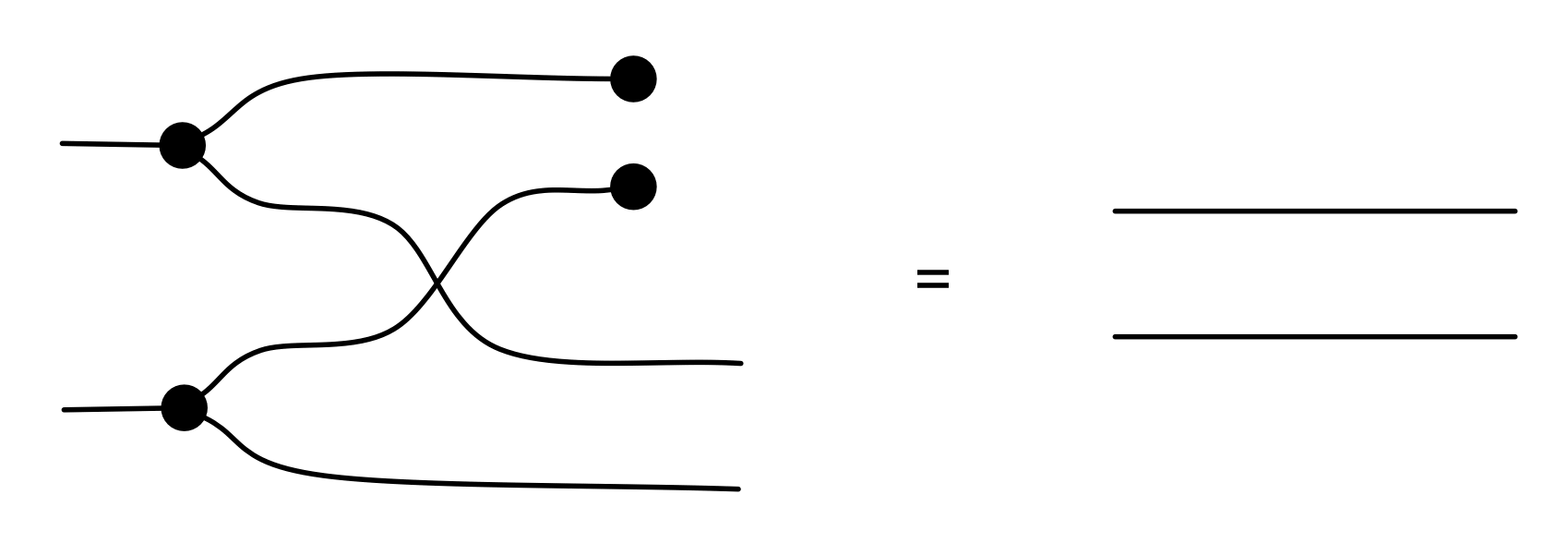
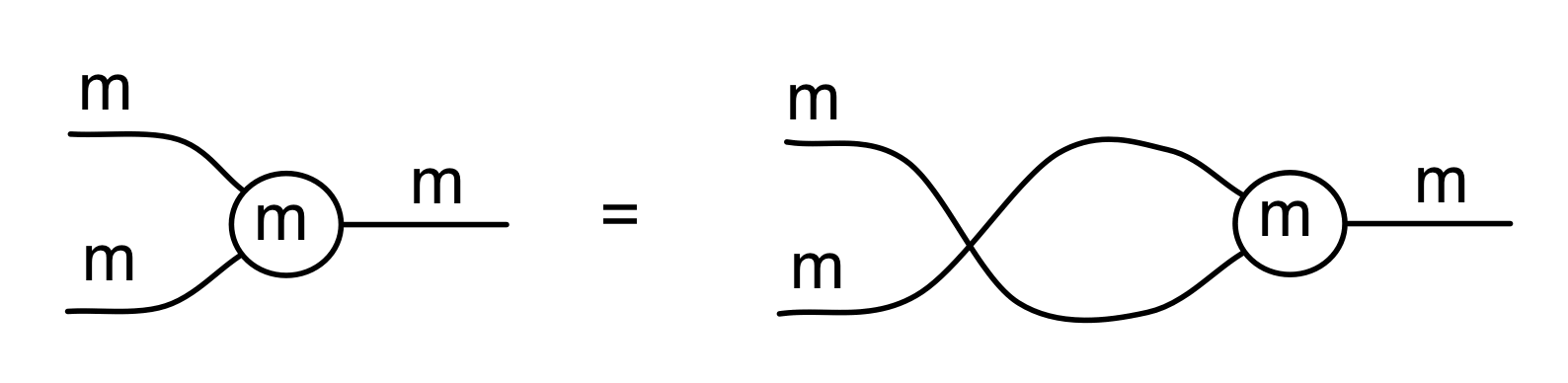
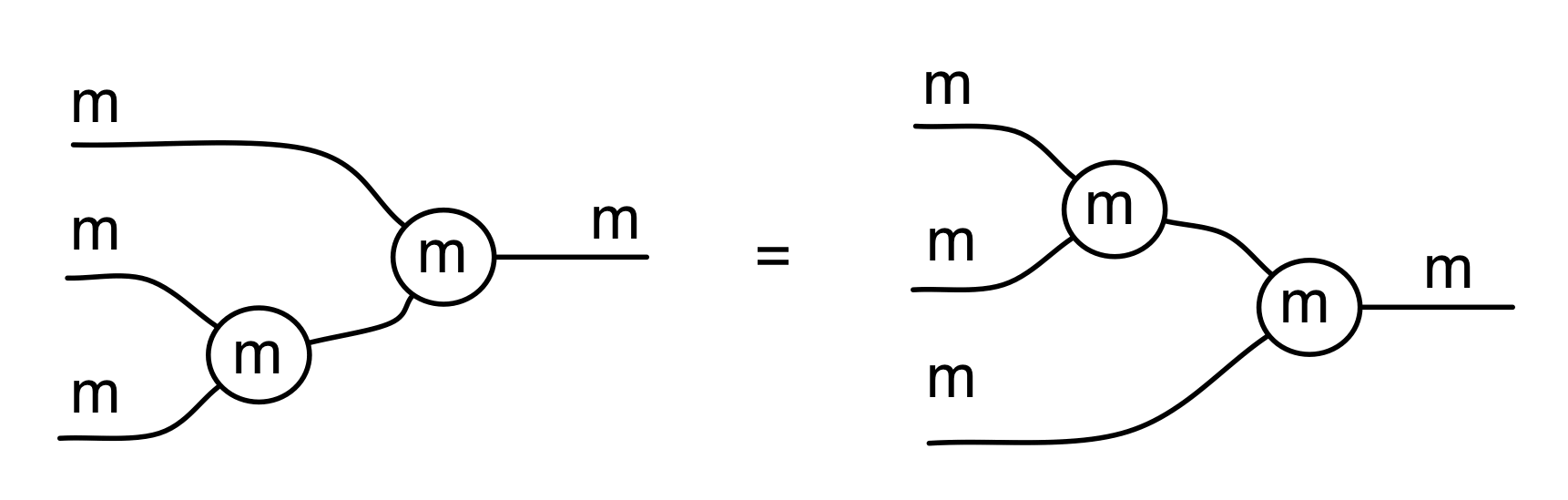
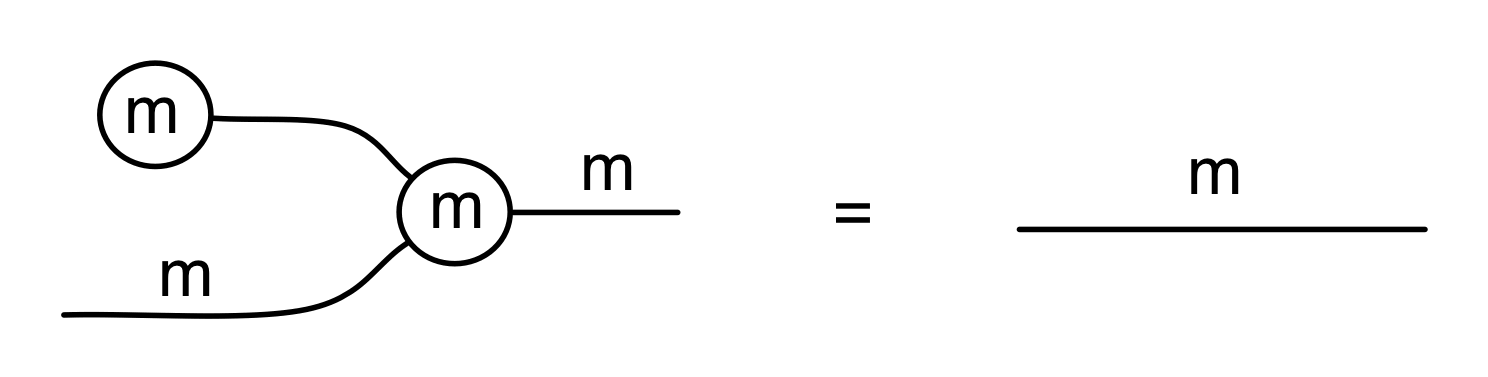

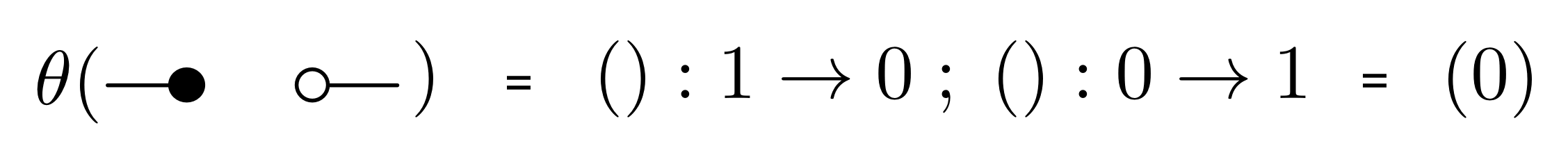

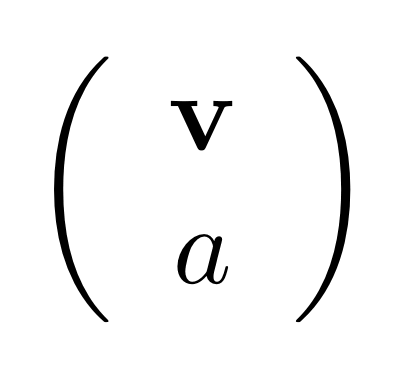
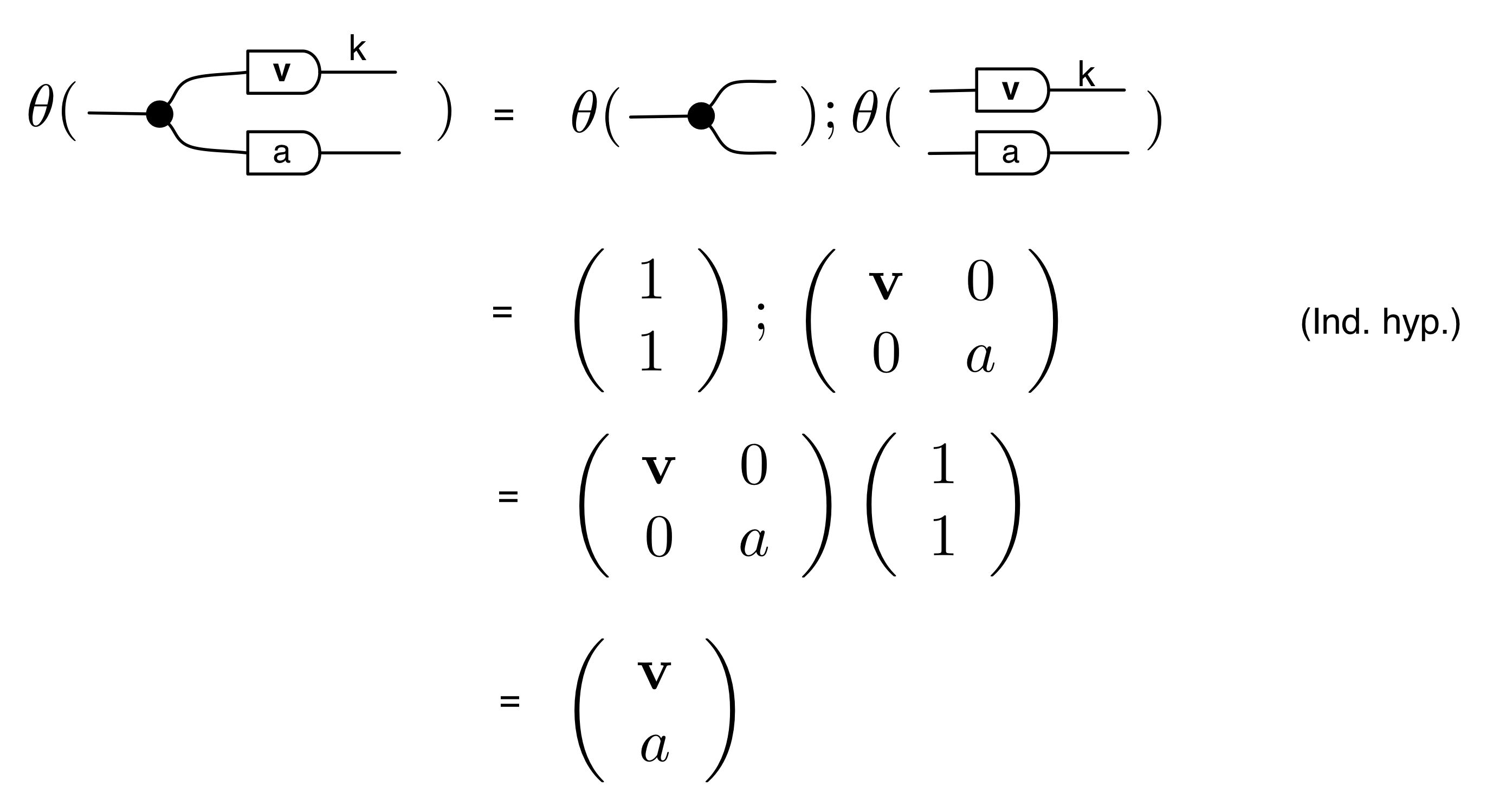
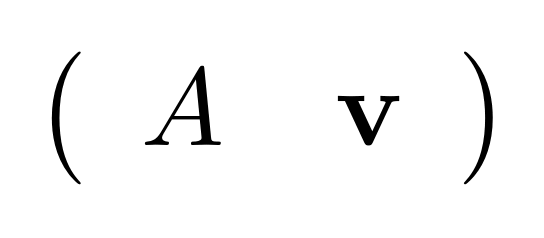
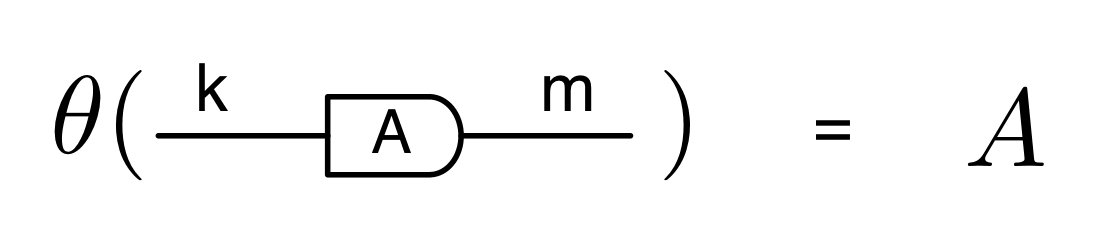
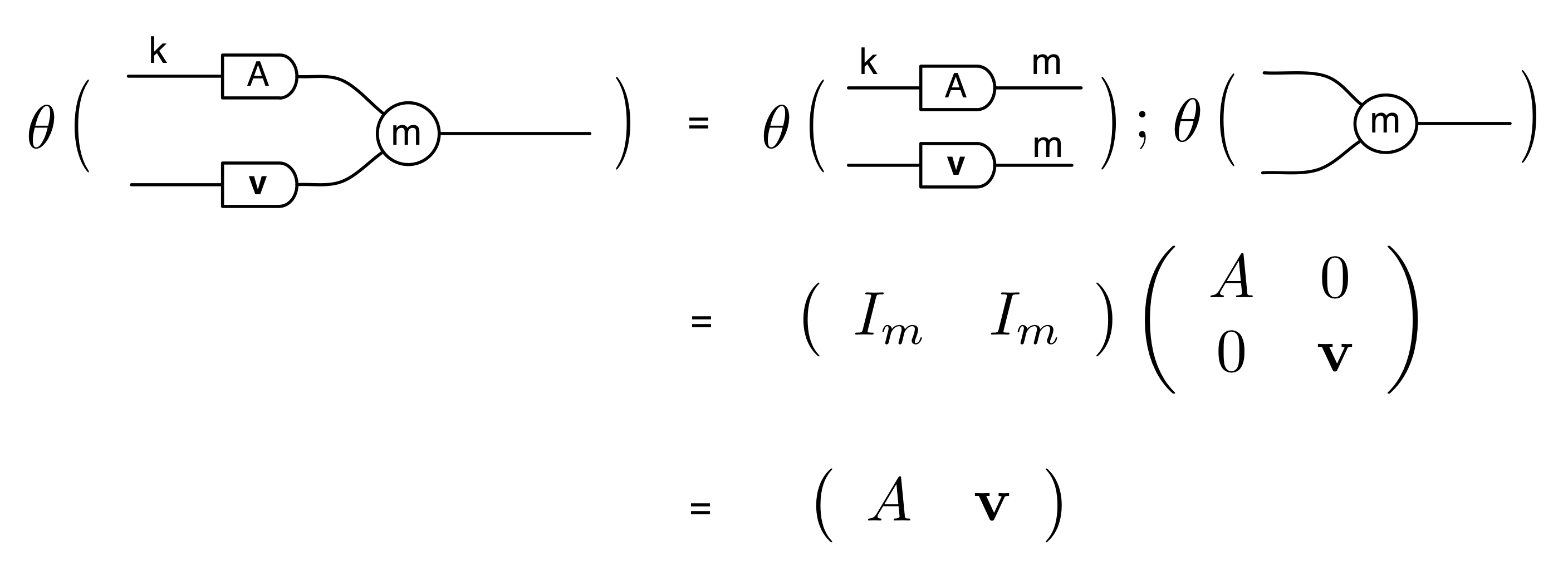
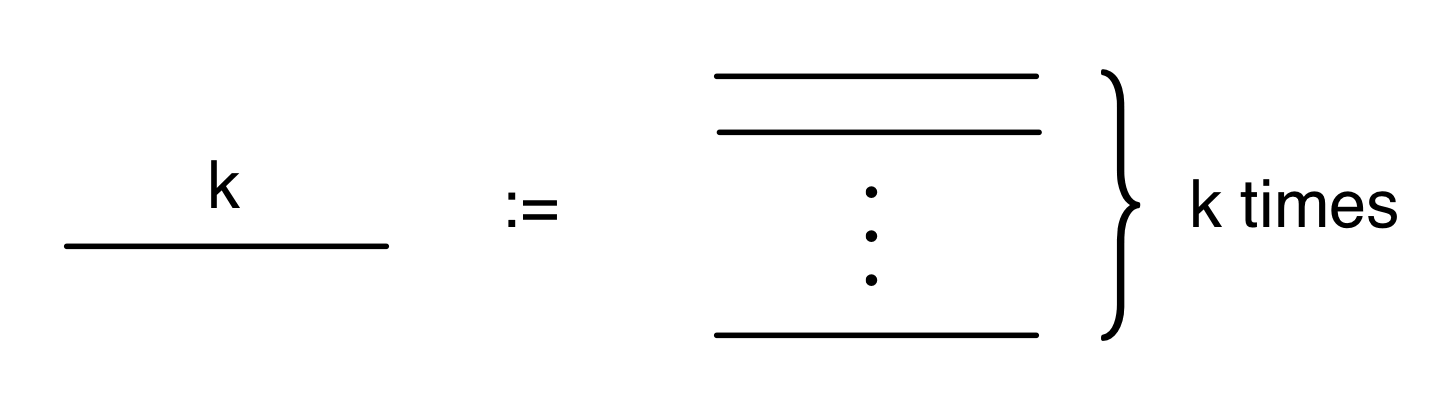






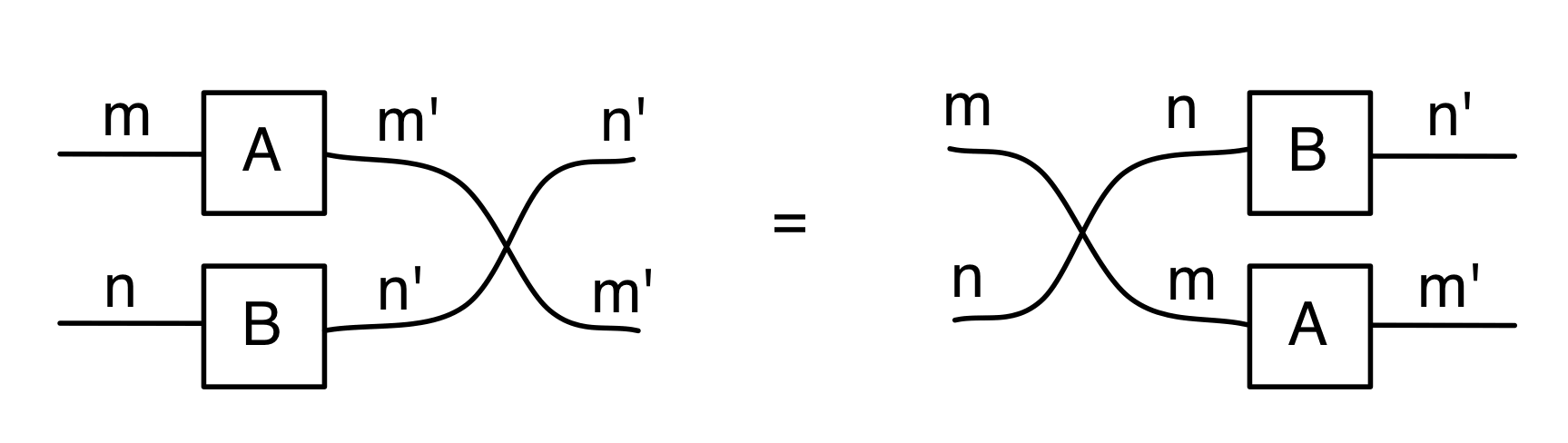

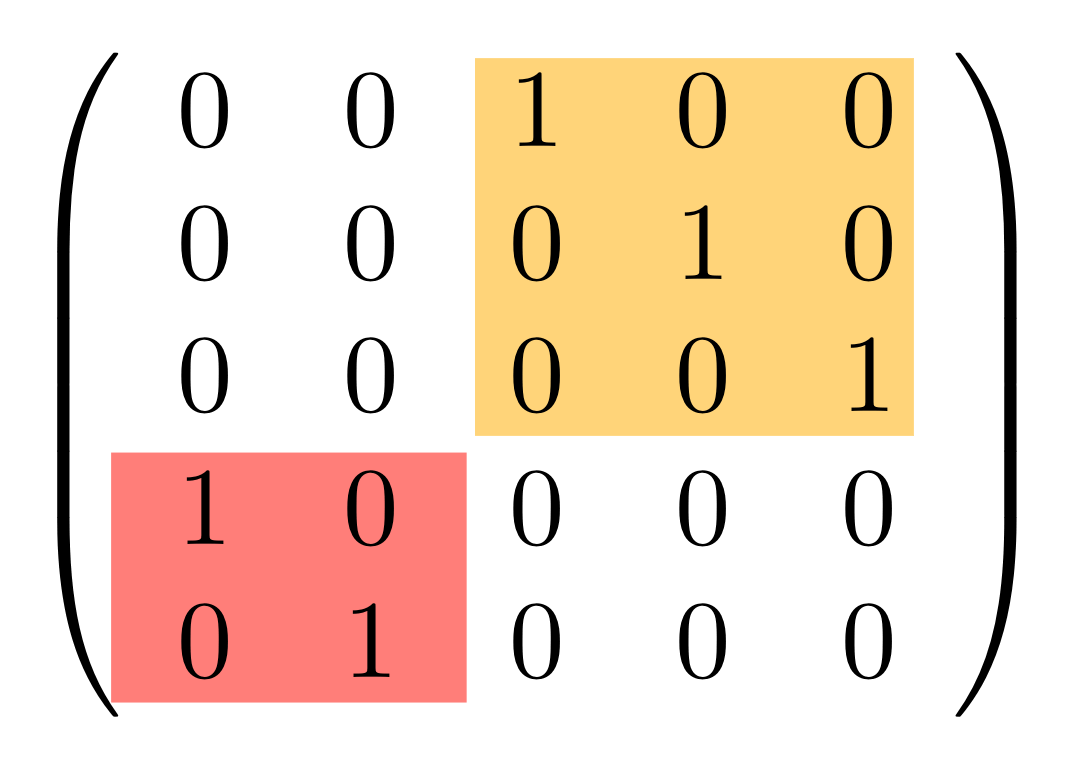




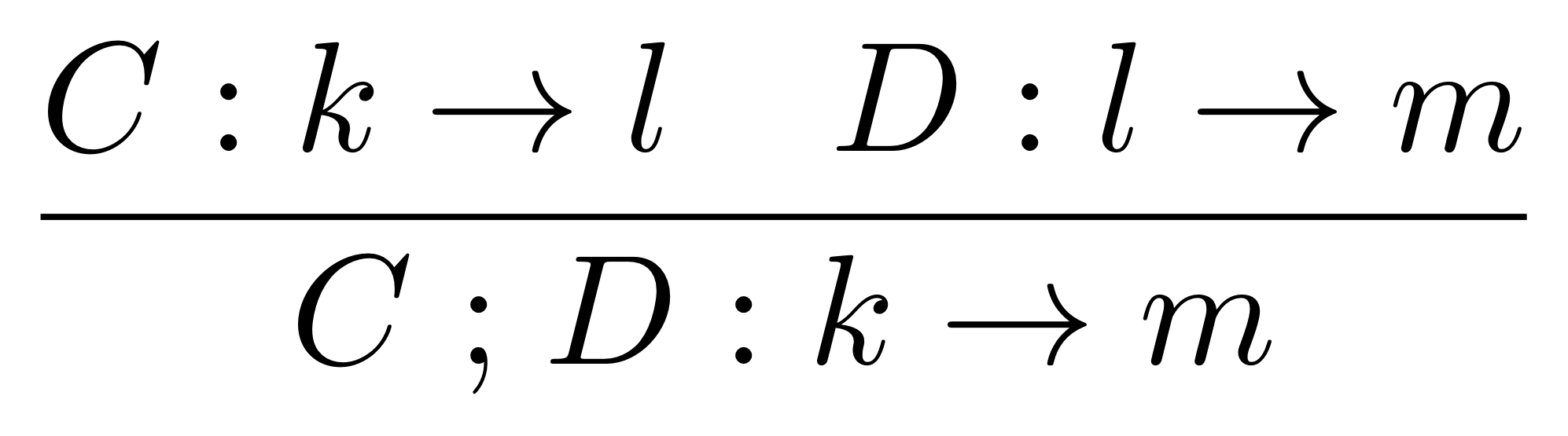
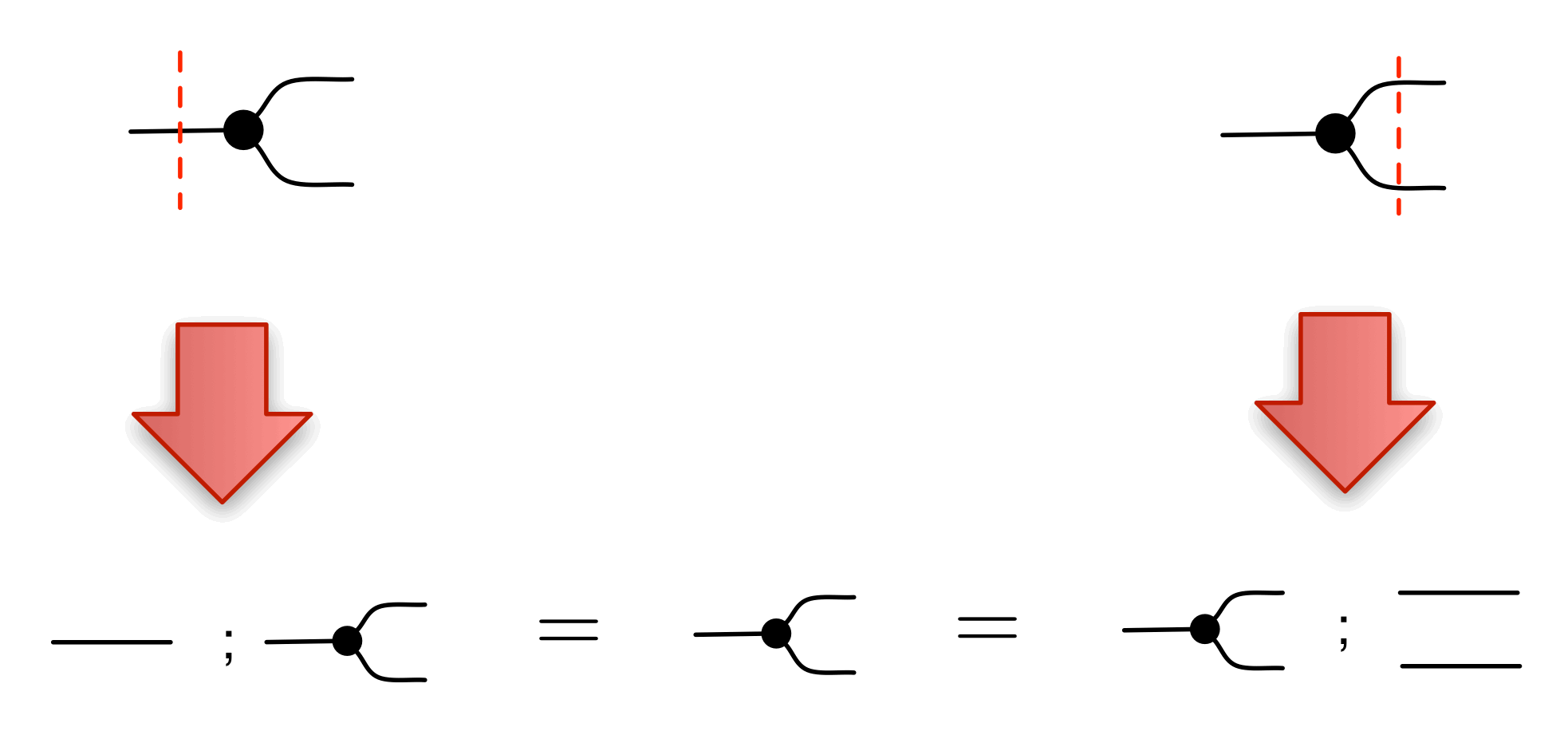



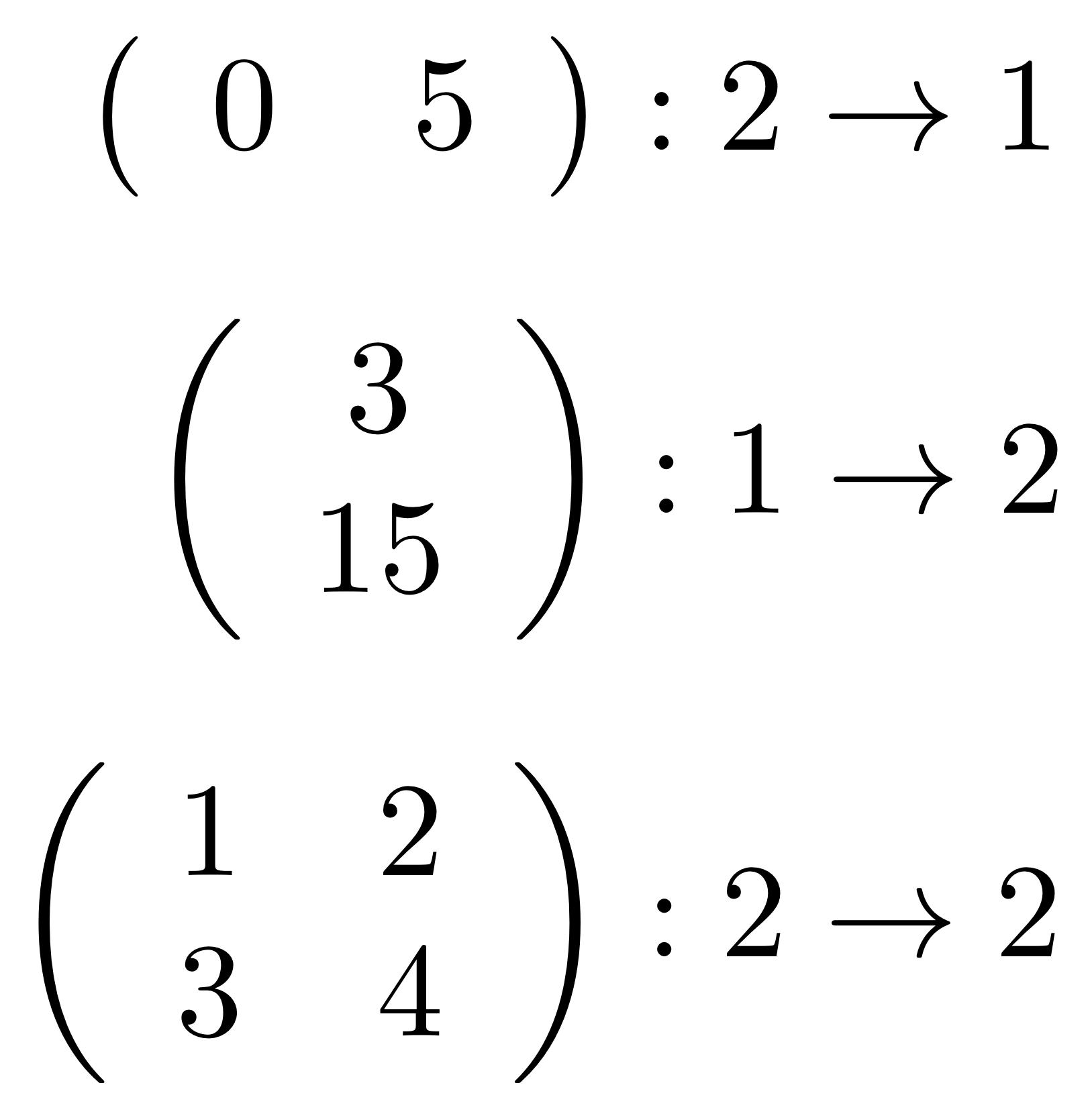
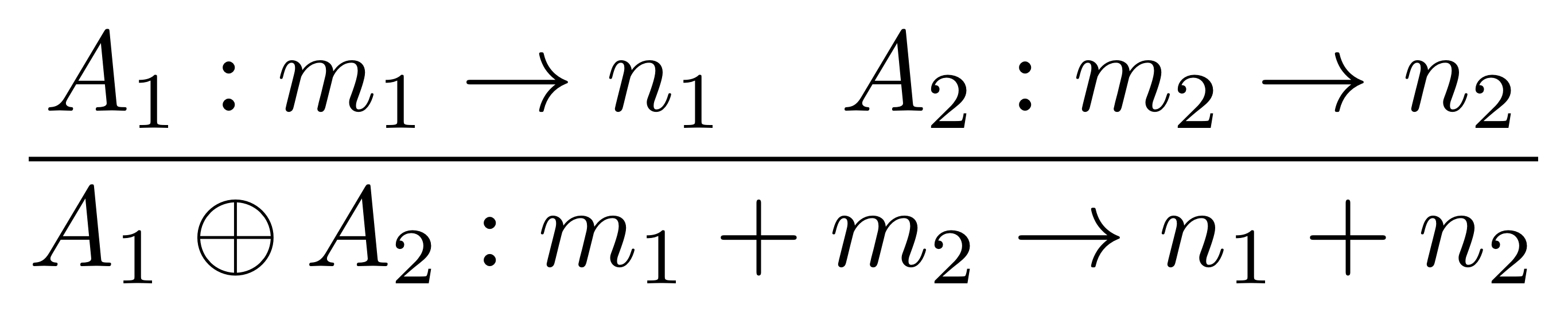

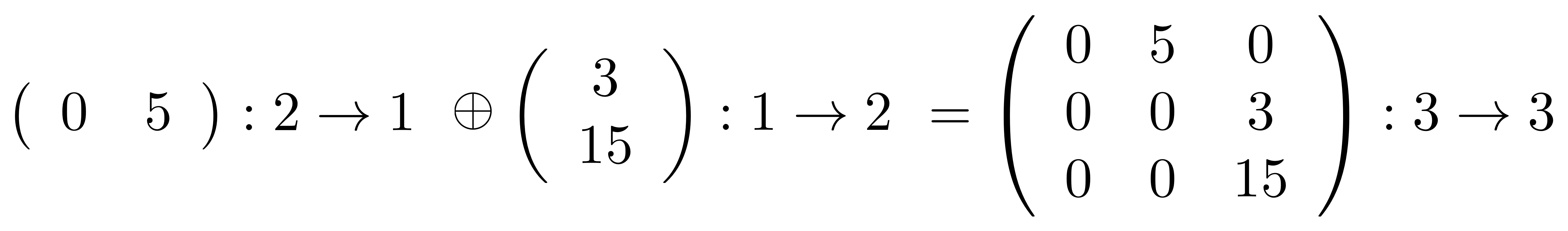
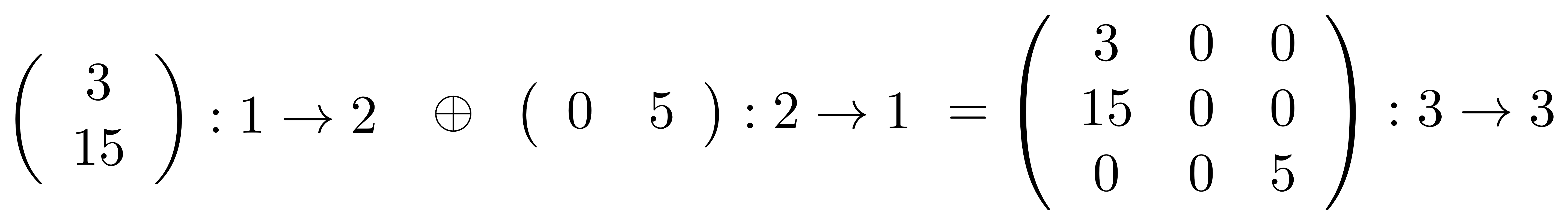
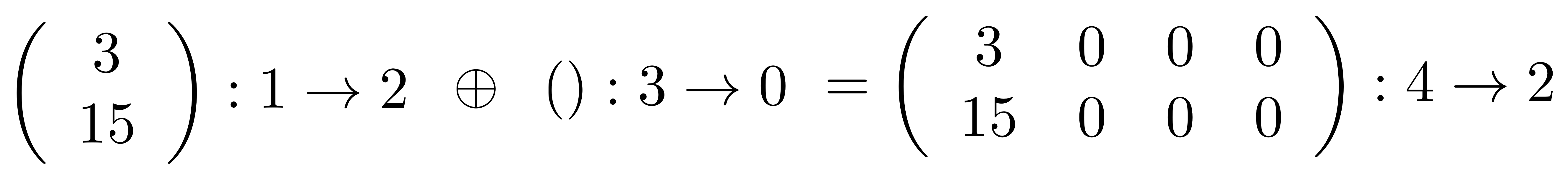
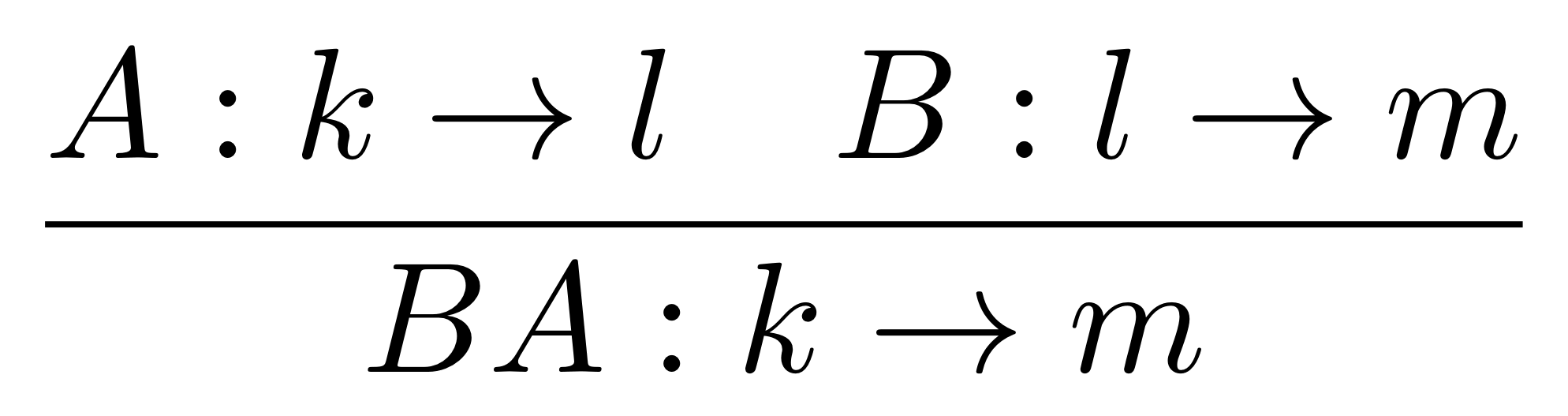
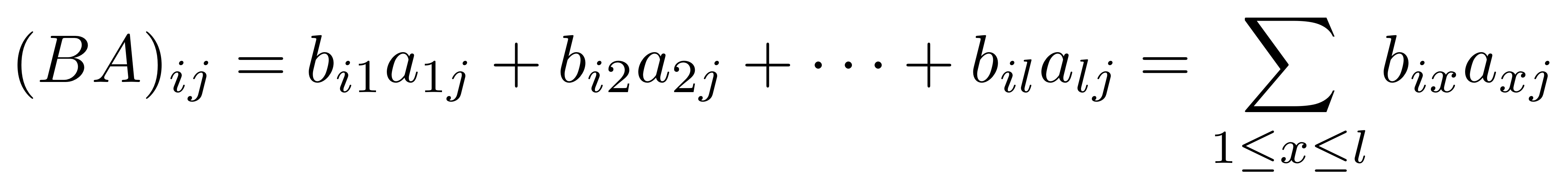
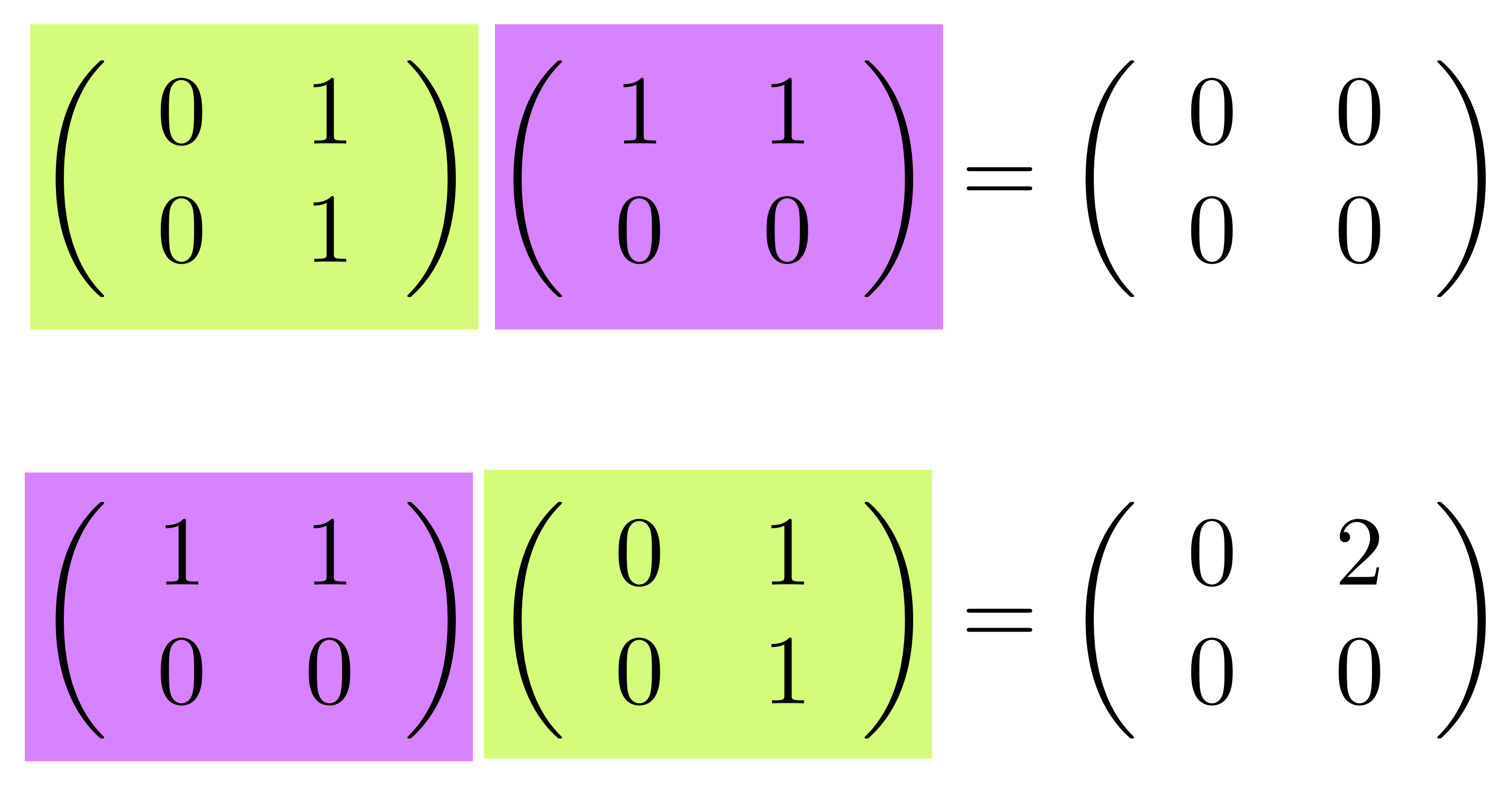
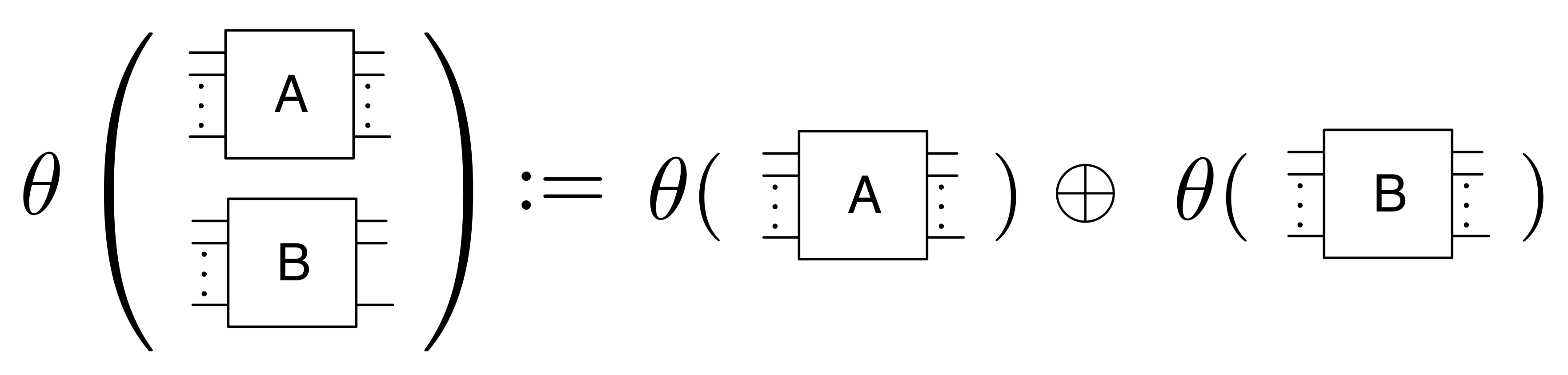

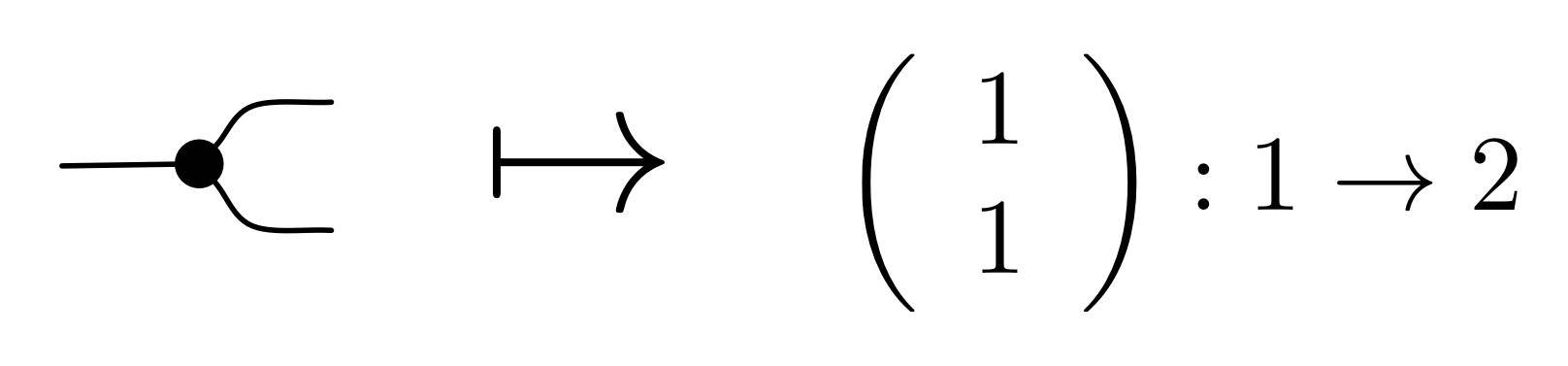
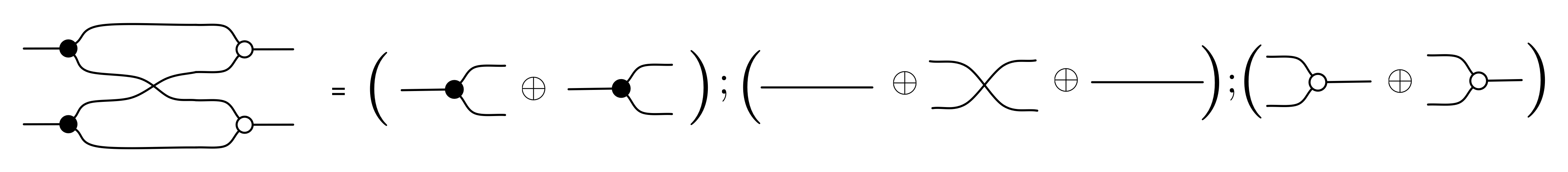
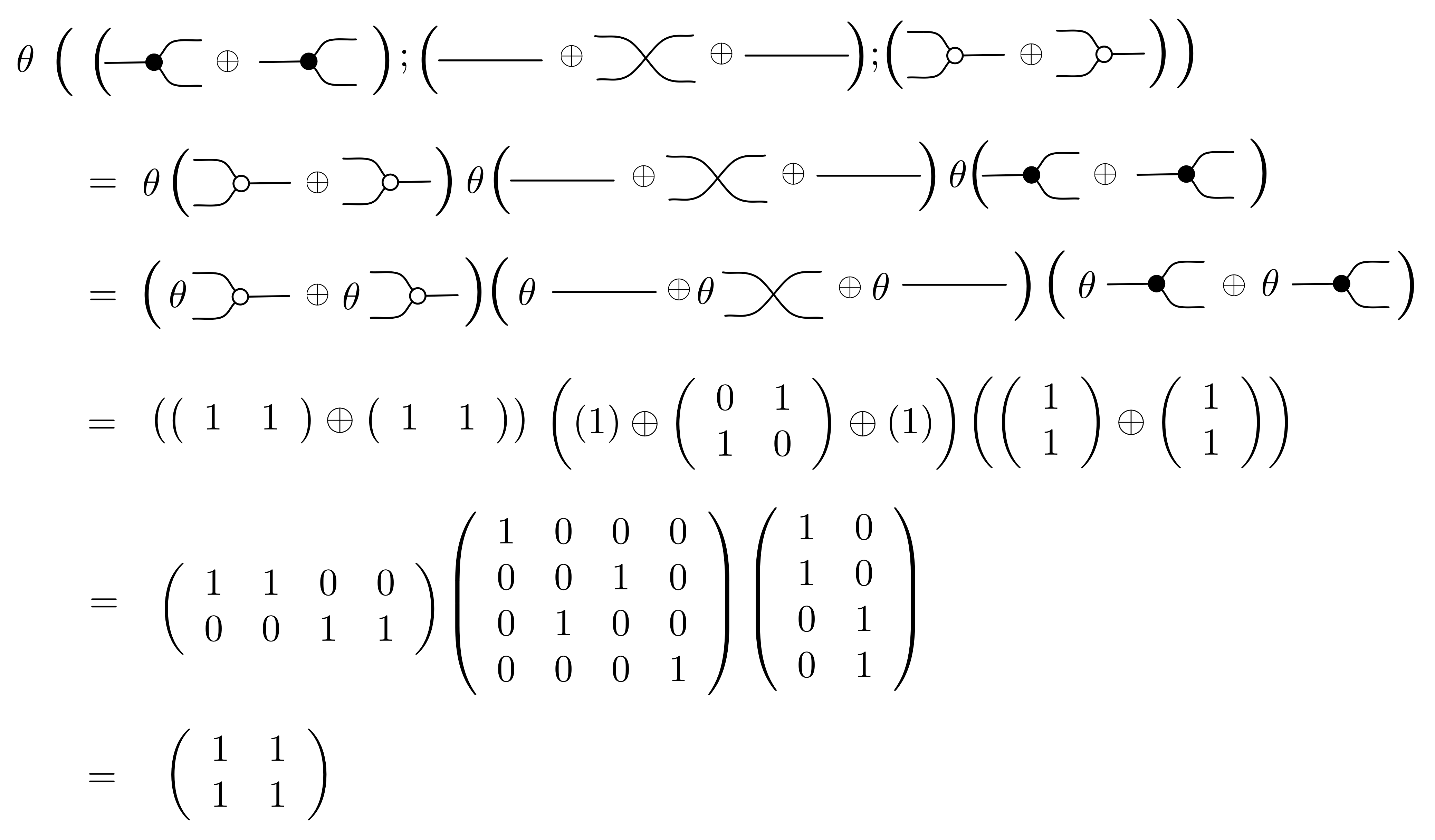
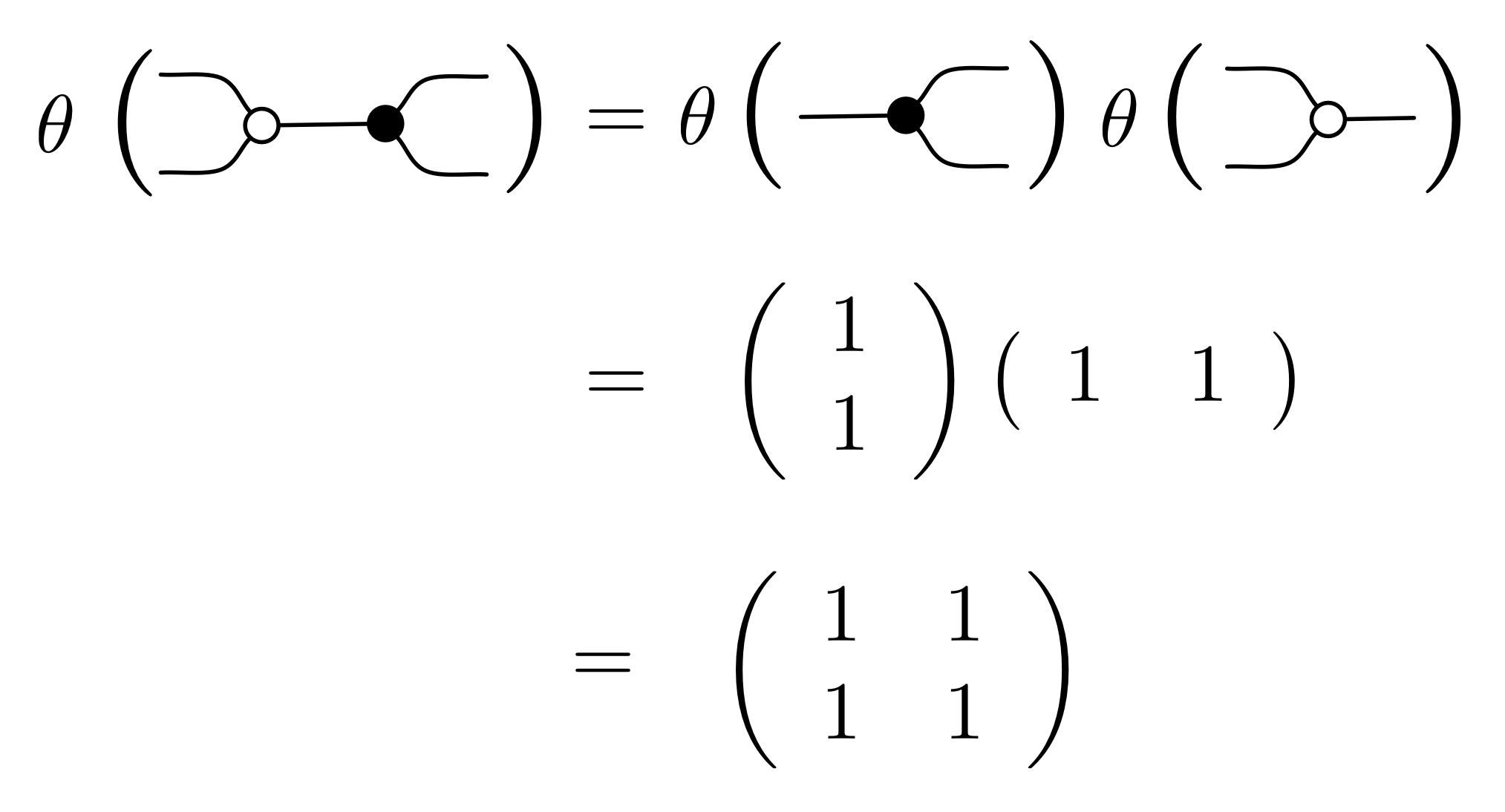












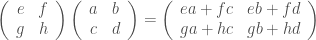 ①
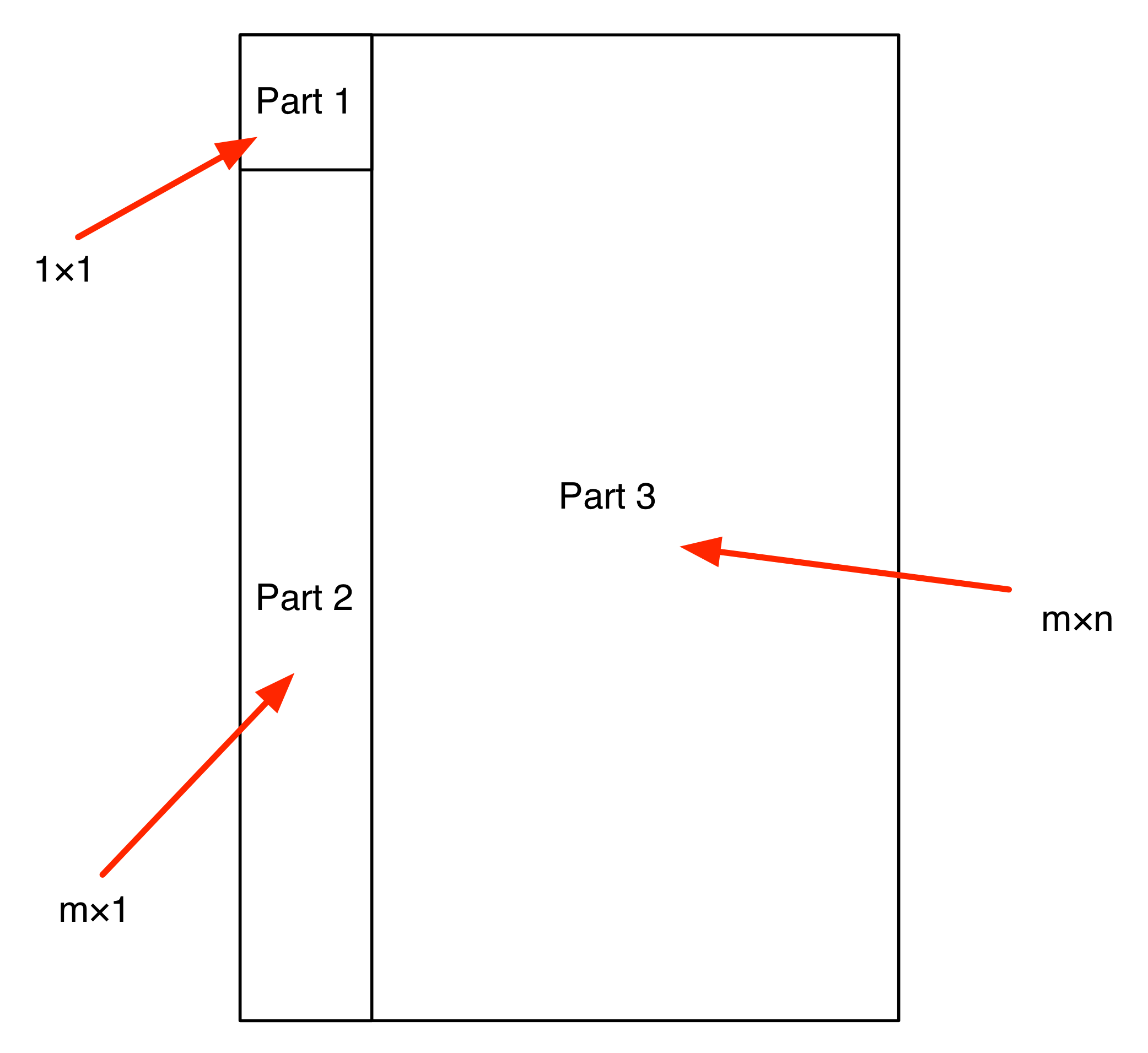
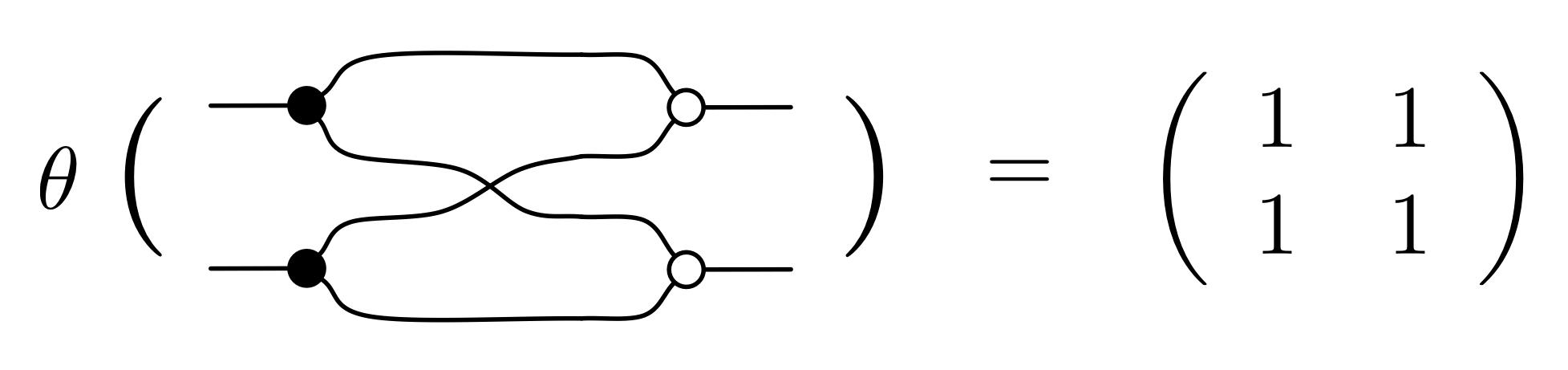
① . In general, the number of columns of the corresponding matrix is the number of dangling wires on the left, and the number of rows is the number of dangling wires on the right. Moreover, the entry at row
. In general, the number of columns of the corresponding matrix is the number of dangling wires on the left, and the number of rows is the number of dangling wires on the right. Moreover, the entry at row 

{kind=link}
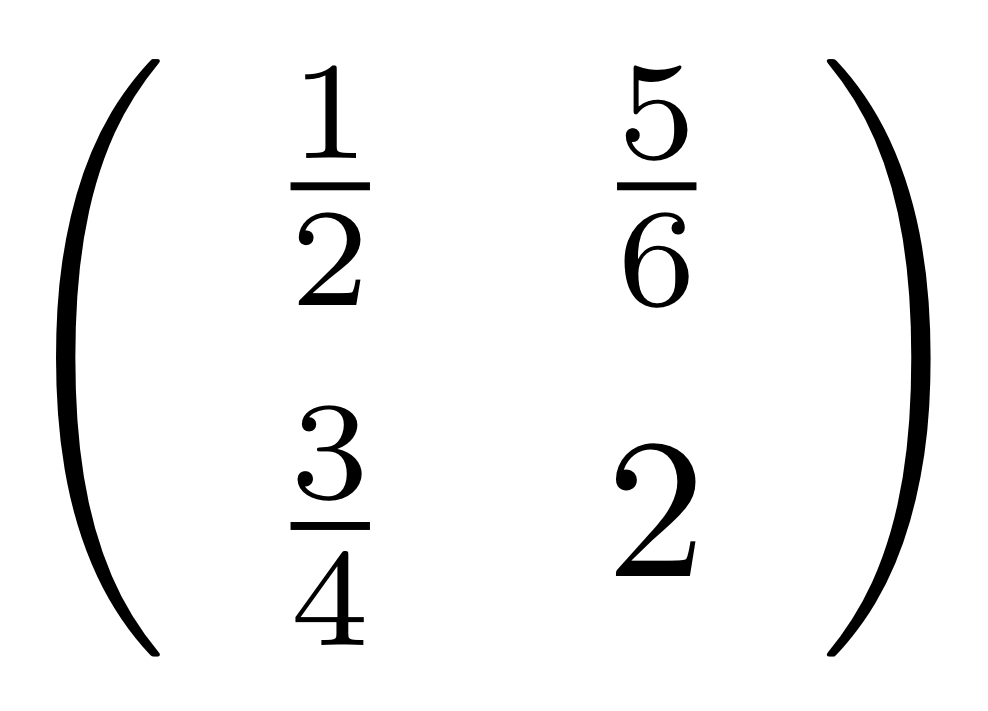{kind=link}
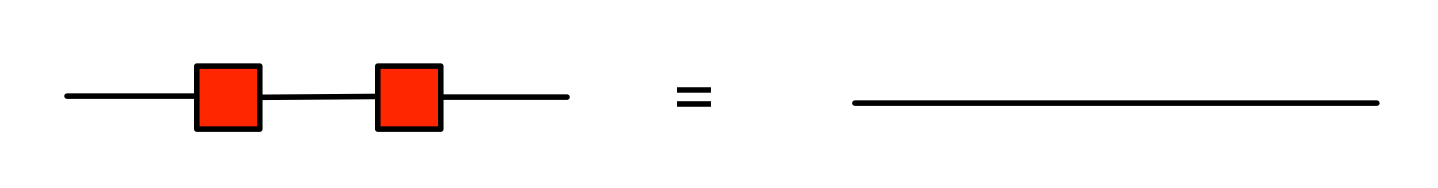{kind=link}
{kind=link}
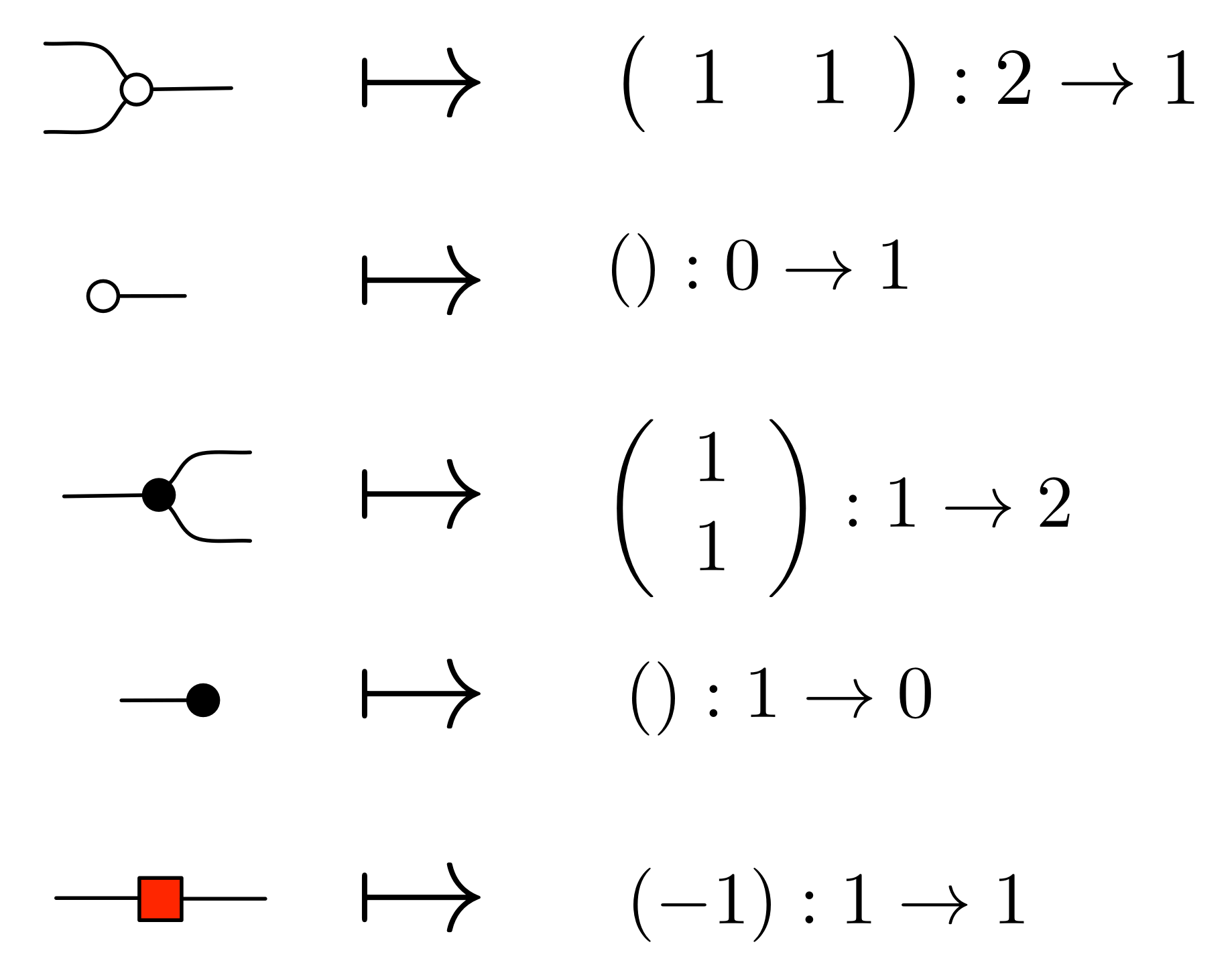{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
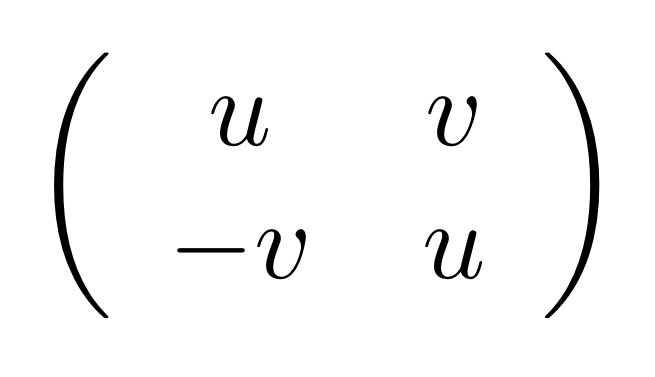{kind=link}
{kind=link}
{kind=link}
{kind=link}