
I was in Nijmegen all of last week, attending the CALCO and MFPS conferences.
On the plus side, they were both excellent and featured many really nice talks. Being bombarded by so much new research always gives you a whole load of ideas. And apart from the scheduled talks, the coffee breaks and the evening events give you a chance to discuss with a large number of extremely interesting people. All of this takes its toll: after an intensive conference week you really get the urge to lie down and sleep for 20 hours so that your brain can get the chance to organise all the new information!
So, on the minus side, the sheer number of talks and social events meant that I have had no time to work on this blog. Overall, it’s going to be a really busy summer for me, so the frequency of articles will drop a bit. Maybe it’s for the best, I’ve been told by a number of people that it’s been difficult to keep up.
I presented my paper with Apiwat Chantawibul on using string diagrams as a language for graph theory at MFPS. I had some really nice questions and I found out from Nicolas Guenot that very similar diagrams are used in something called deep inference in logic. I have to investigate this, it looks extremely interesting! Surely it cannot be a coincidence that their diagrams are so similar. Eventually I’ll have write about that research thread on this blog.
The history of mathematics is delineated by a number of events where, in order to make progress, new kinds of numbers were introduced. These impostor-numbers were usually first used as a technical trick to “make the calculations go through”. Then, after a while, they began to be taken a bit more seriously, before being finally dismissed as “totally obvious” and taught to primary school kids. Zero is a prime example, and it was surely very controversial, although we have lost a great deal of the debates because they happened so long ago. Negative numbers are another example. First discovered in China around 200 BC, they were routinely degraded as confusing, unnatural and generally nefarious until the 19th (!) century. Fractions, aka the rational numbers are yet another instance of this phenomenon, and we will discuss them here in a few episodes. More recently the story has been repeated for other kinds of numbers, the complex numbers being probably the most famous. But we have to wait until the final years of high school before meeting them, and we still refer to some of them as imaginary.
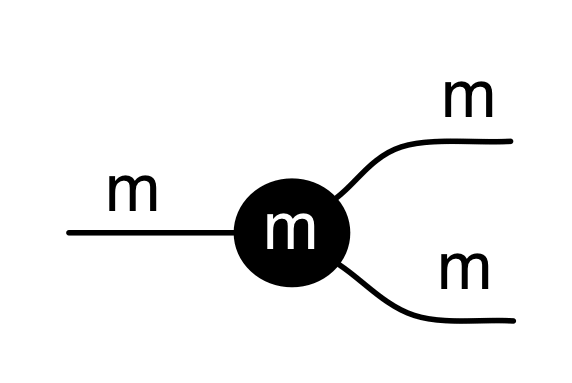
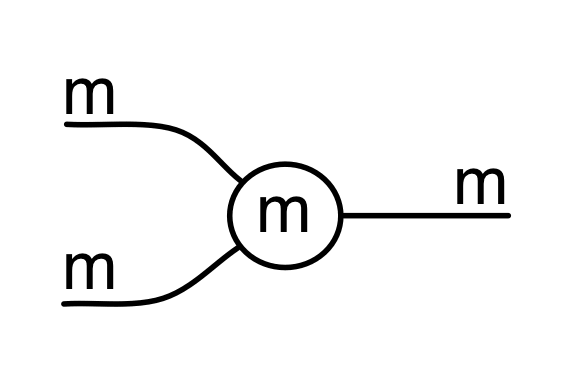
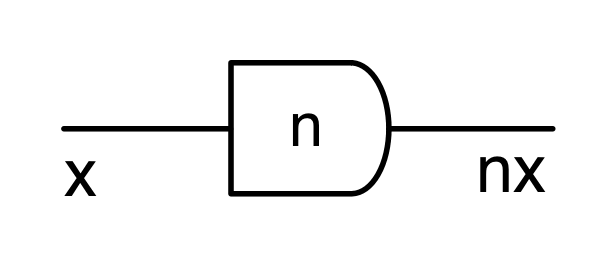
To make progress in graphical linear algebra we need to add negative numbers to the diagrammatic language. Back in Episode 7 I told you that graphical linear algebra has five principal actors. We have met four of them so far: copy and add, together with their sidekicks discard and zero. We meet the fifth one today. The new actor—being a trickster— likes to impersonate the natural numbers, so let’s first remind ourselves of what the natural numbers are, diagrammatically speaking.
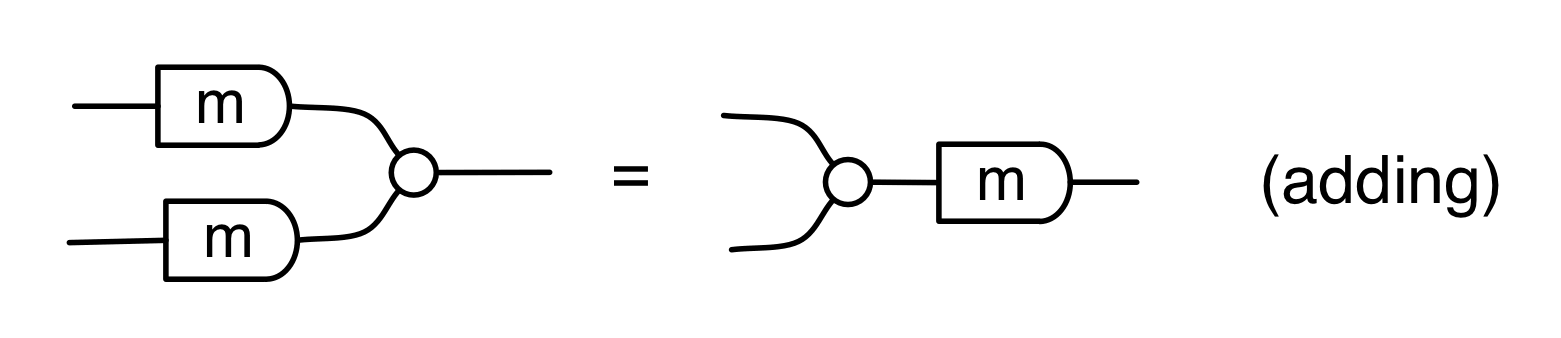
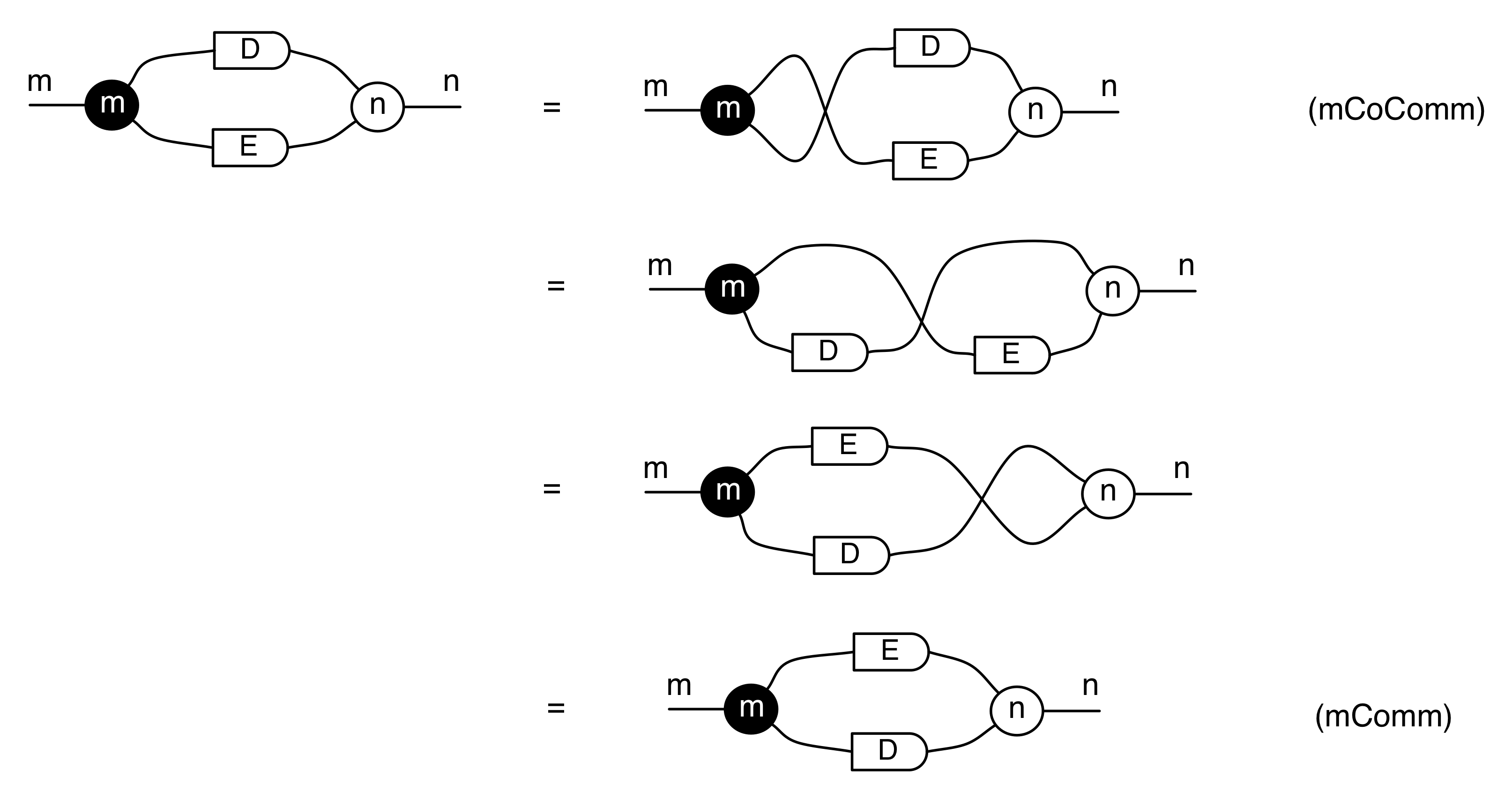
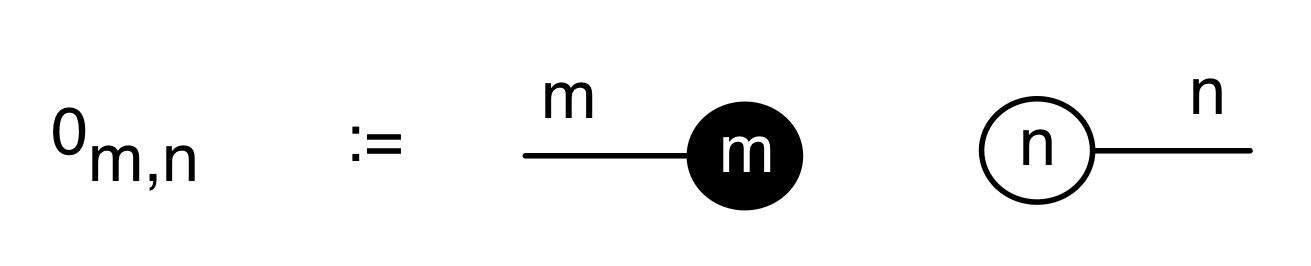
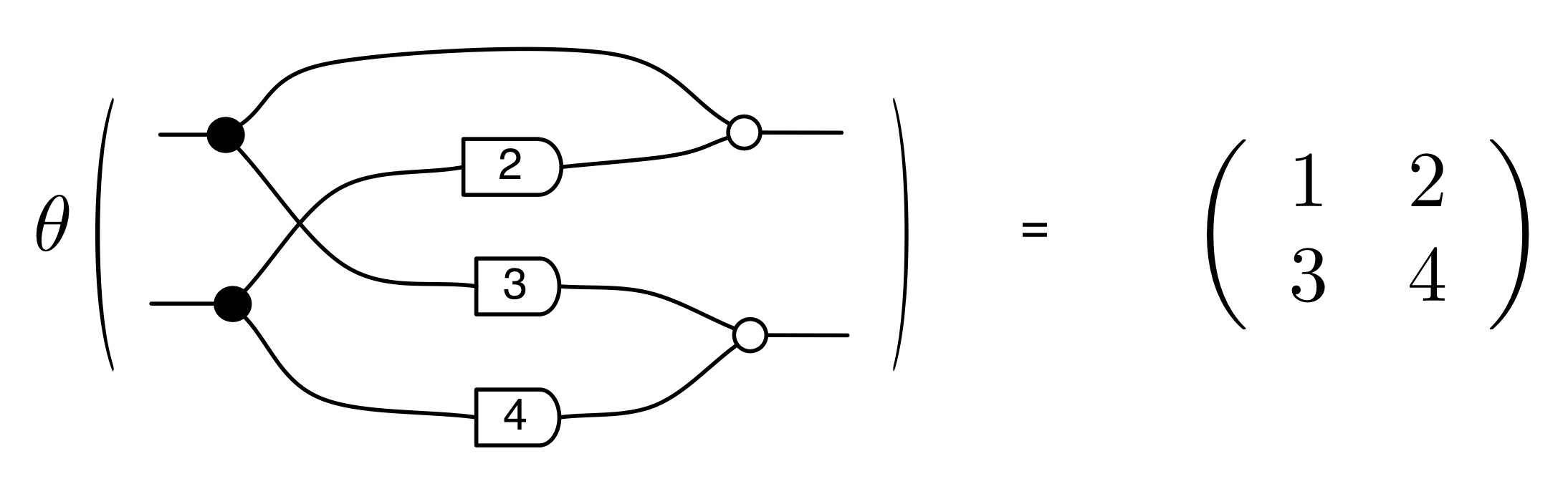
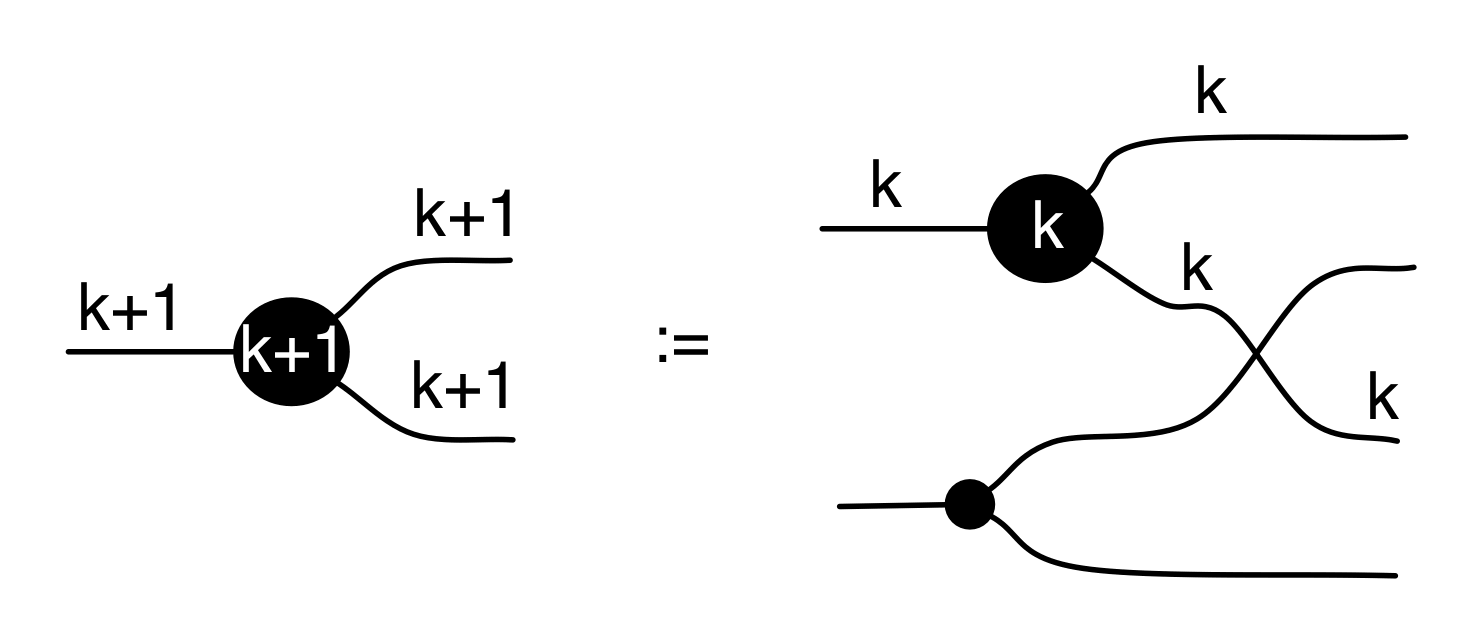
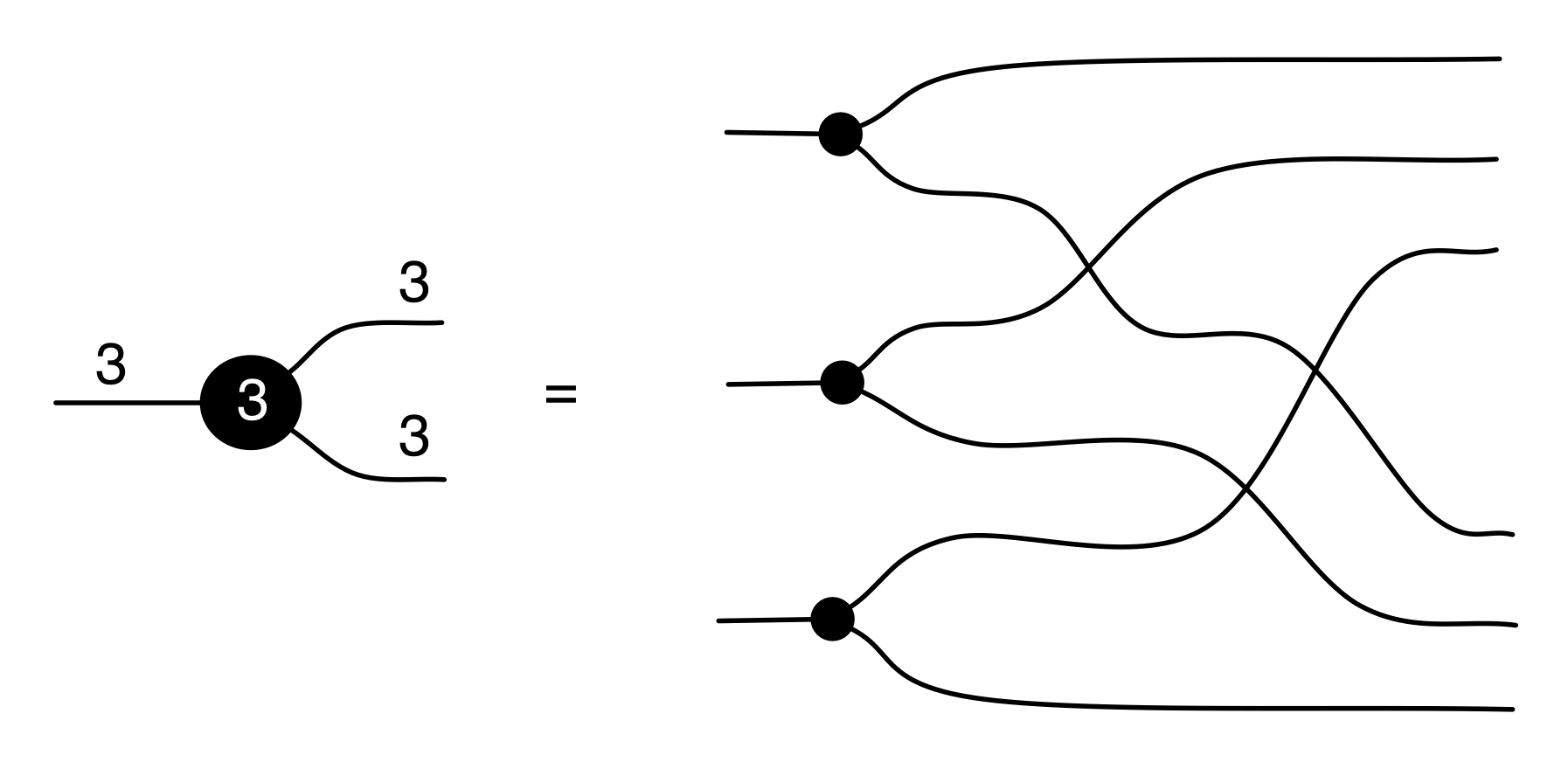
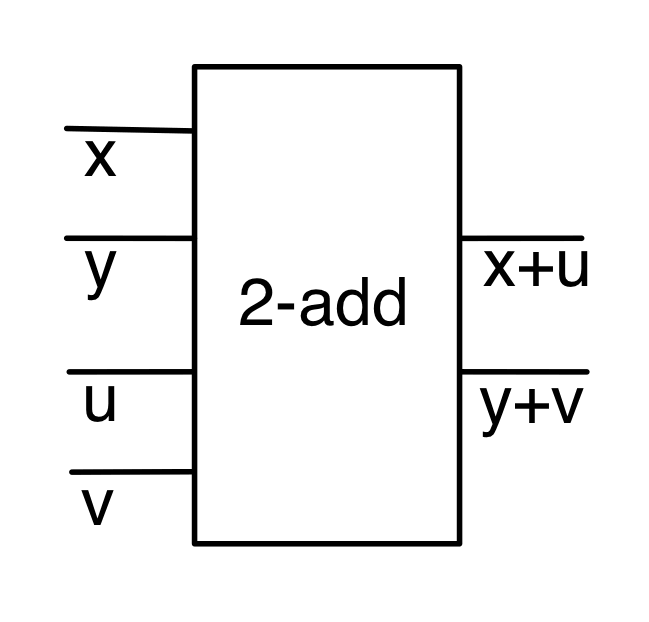
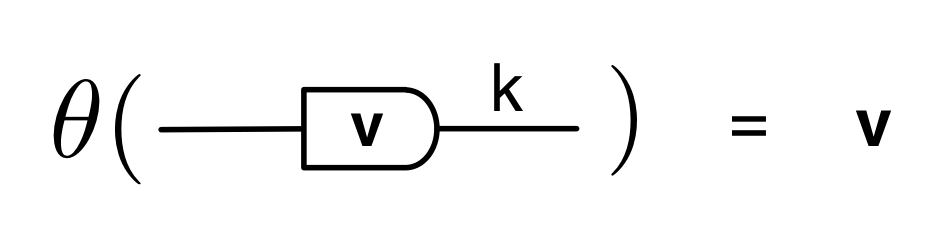
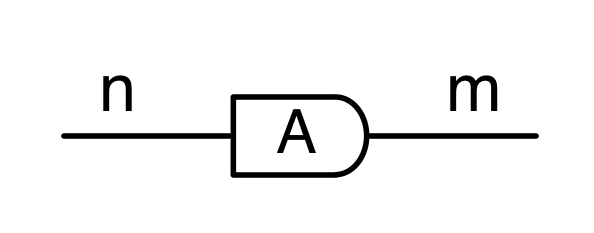
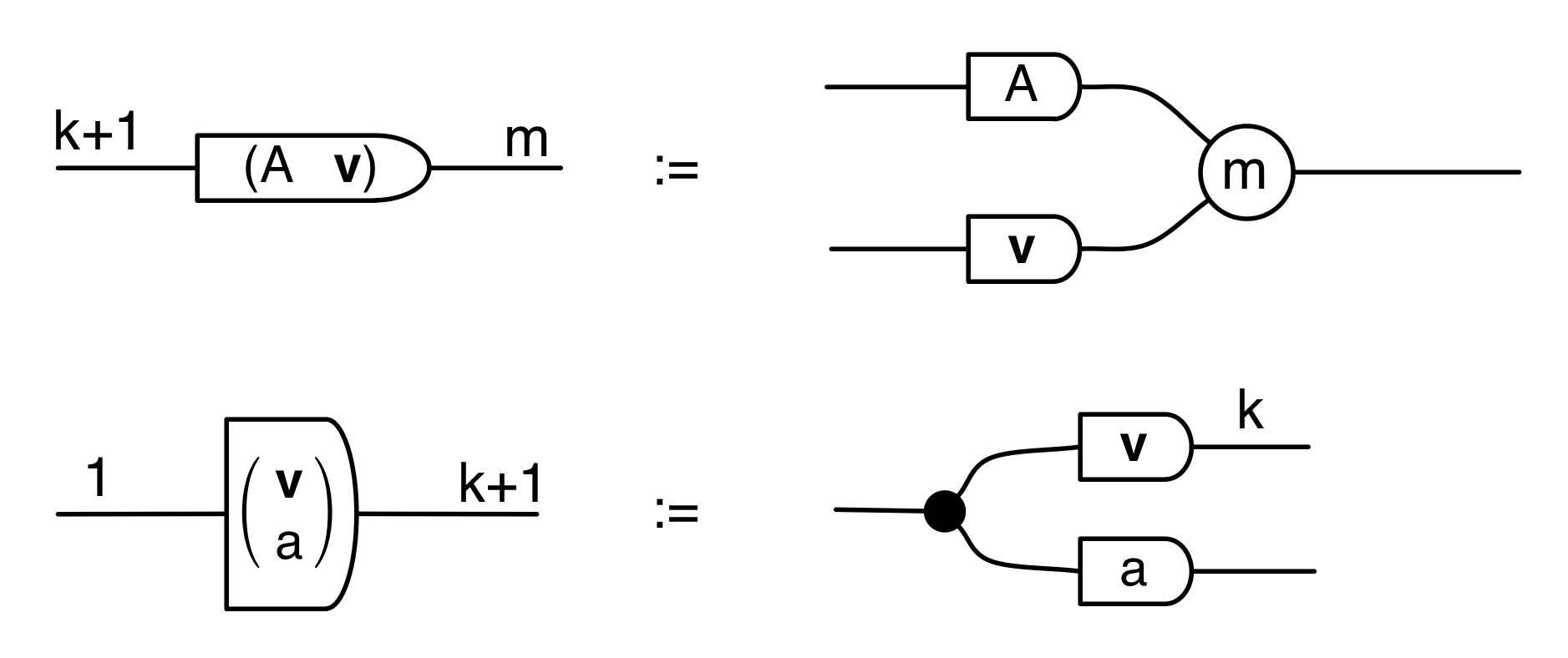
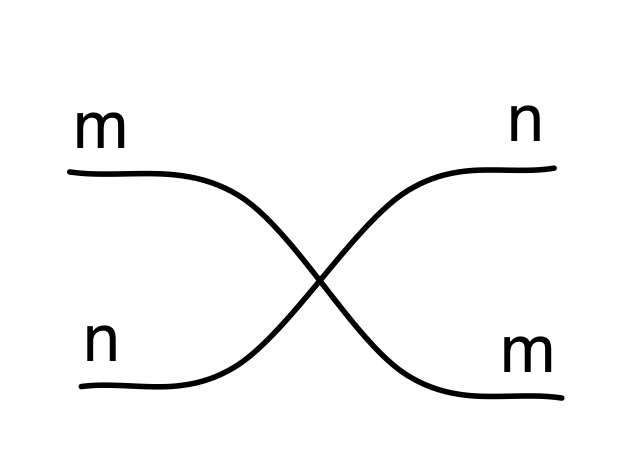
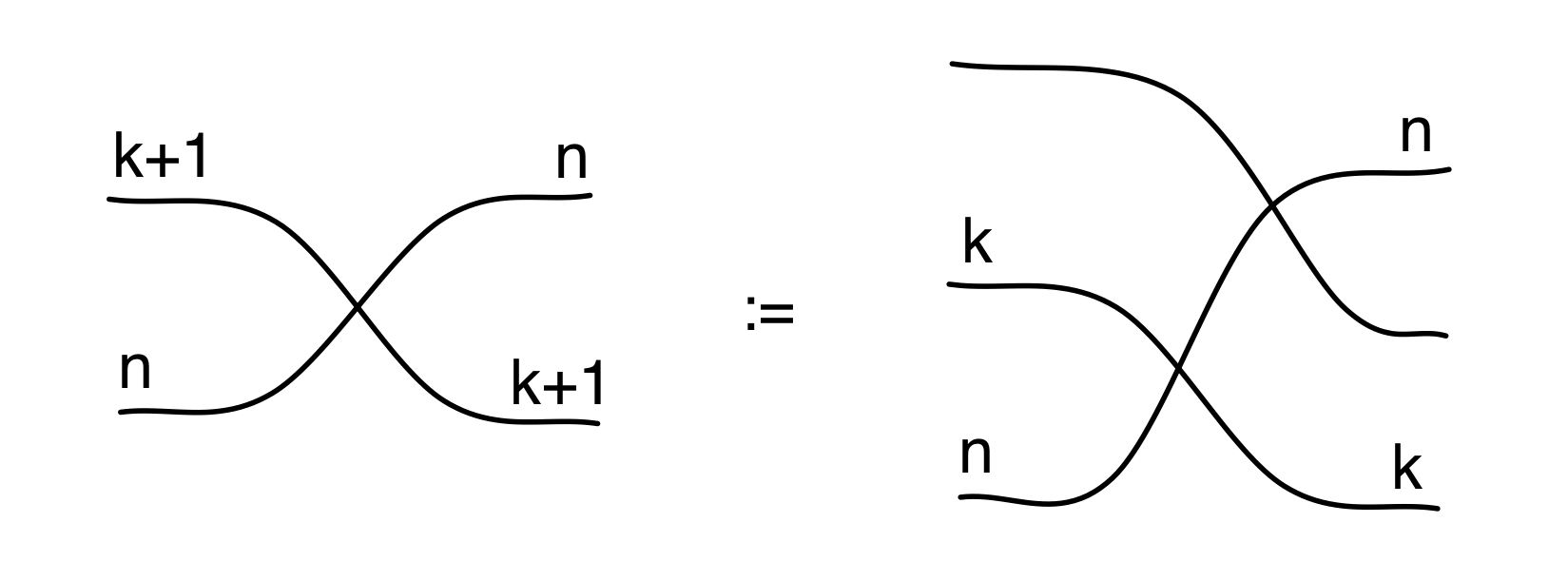
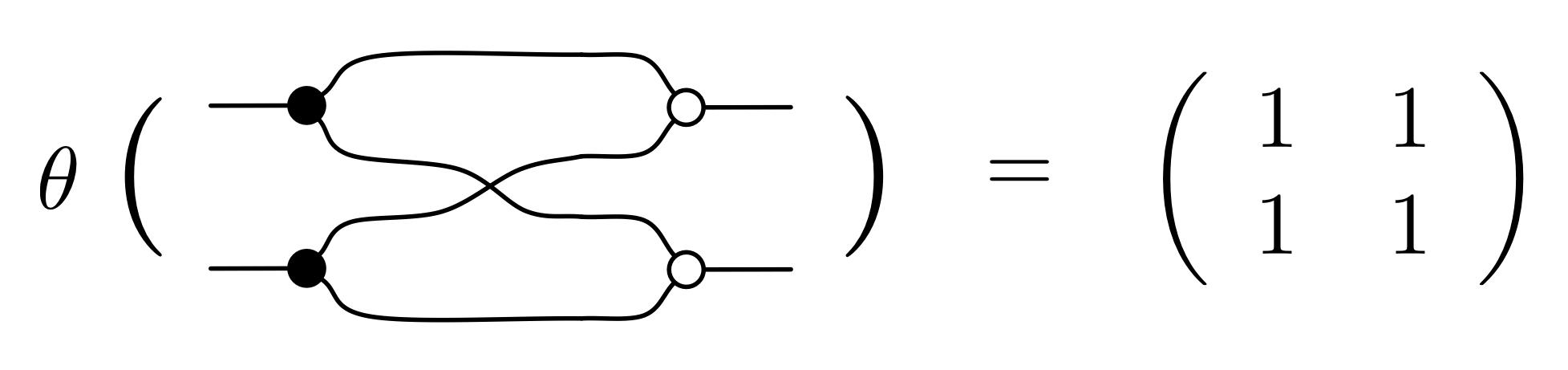
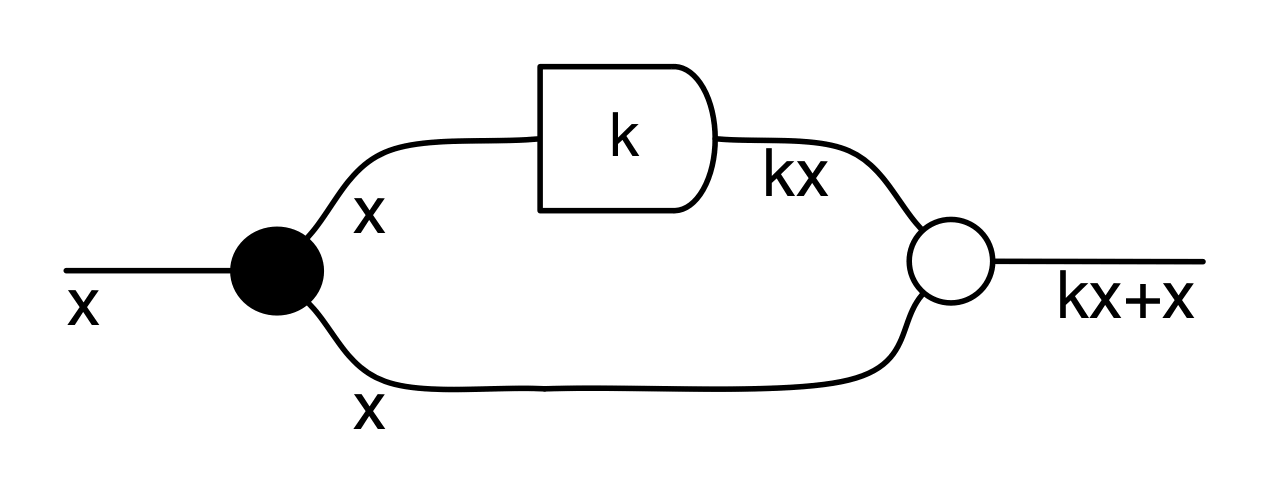
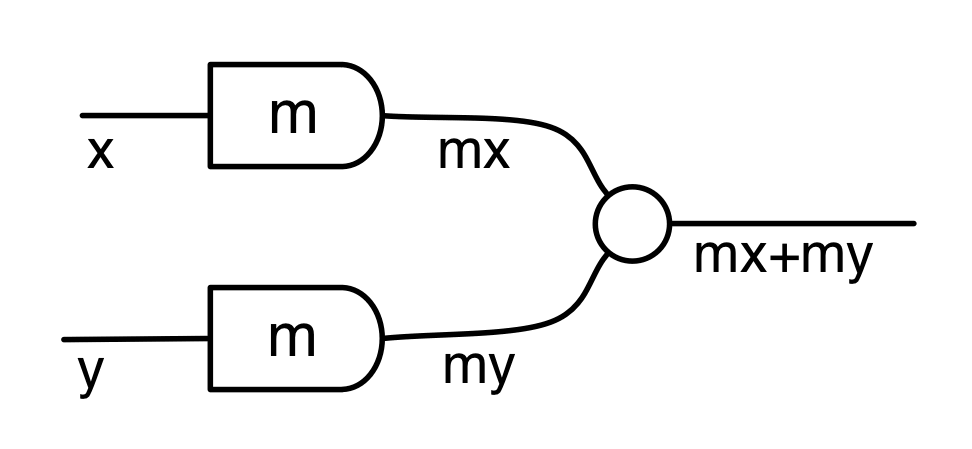
We have discovered that the natural numbers can be identified with those diagrams in the system B that have precisely one dangling wire on the left and one on the right. This was done in two steps: first we introduced the syntactic sugar for natural numbers in Episode 9, and then in Episode 16 we argued that every diagram of this kind (one dangling wire on each end) is equal to one that arises from a sugar. This fact is a consequence of the more general faithfulness theorem for the homomorphism of PROPs θ from B to the PROP Mat of natural number matrices.
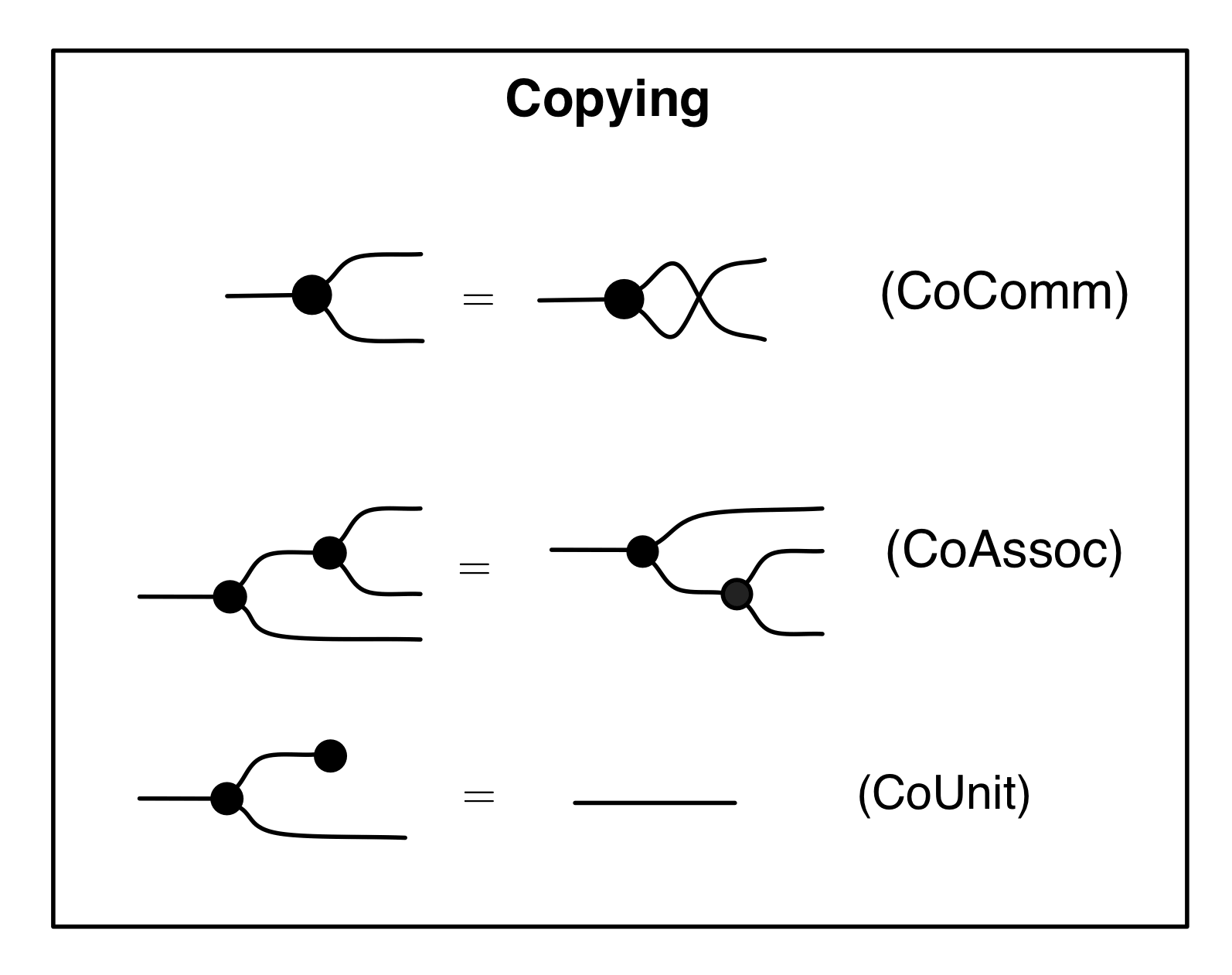
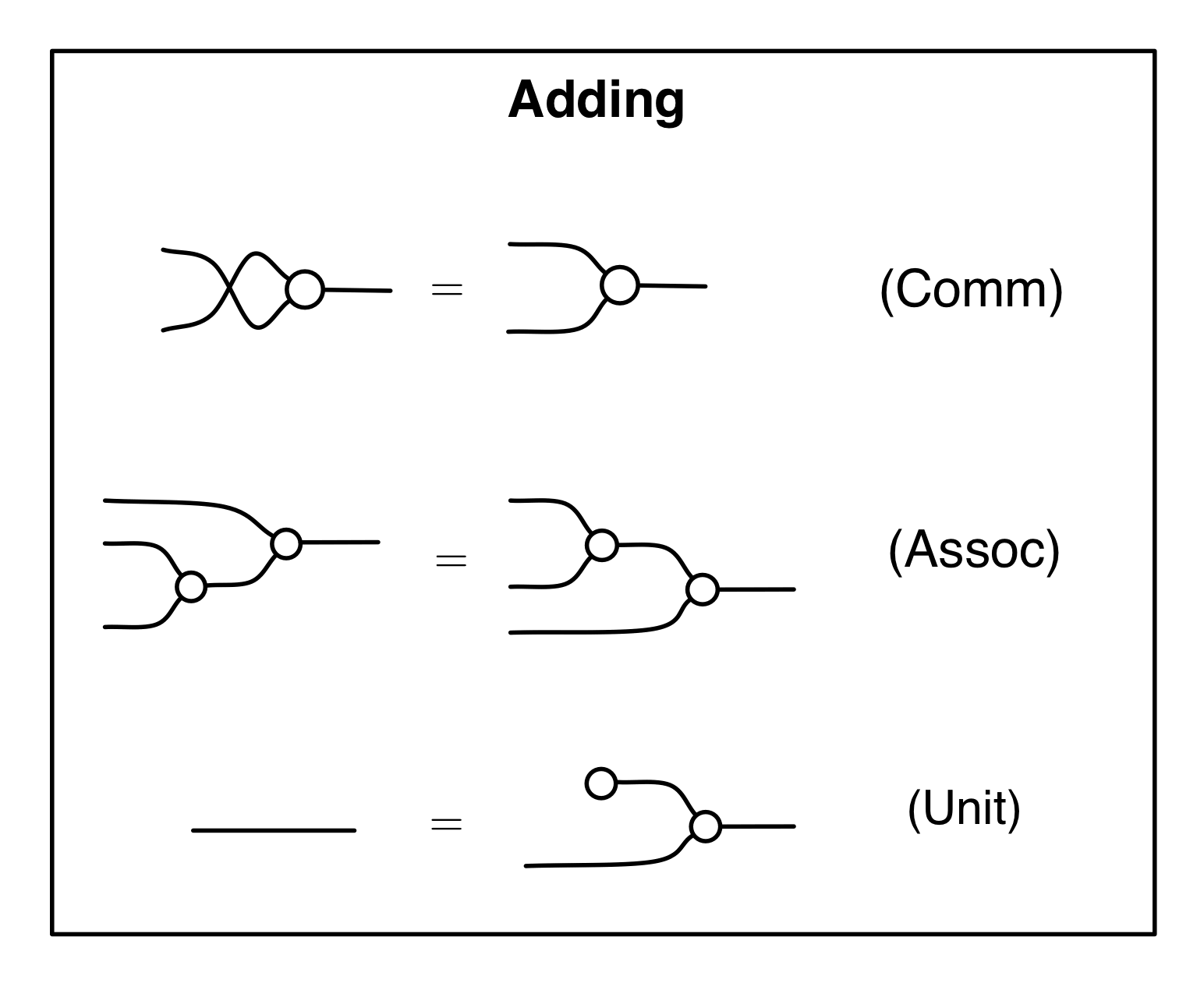
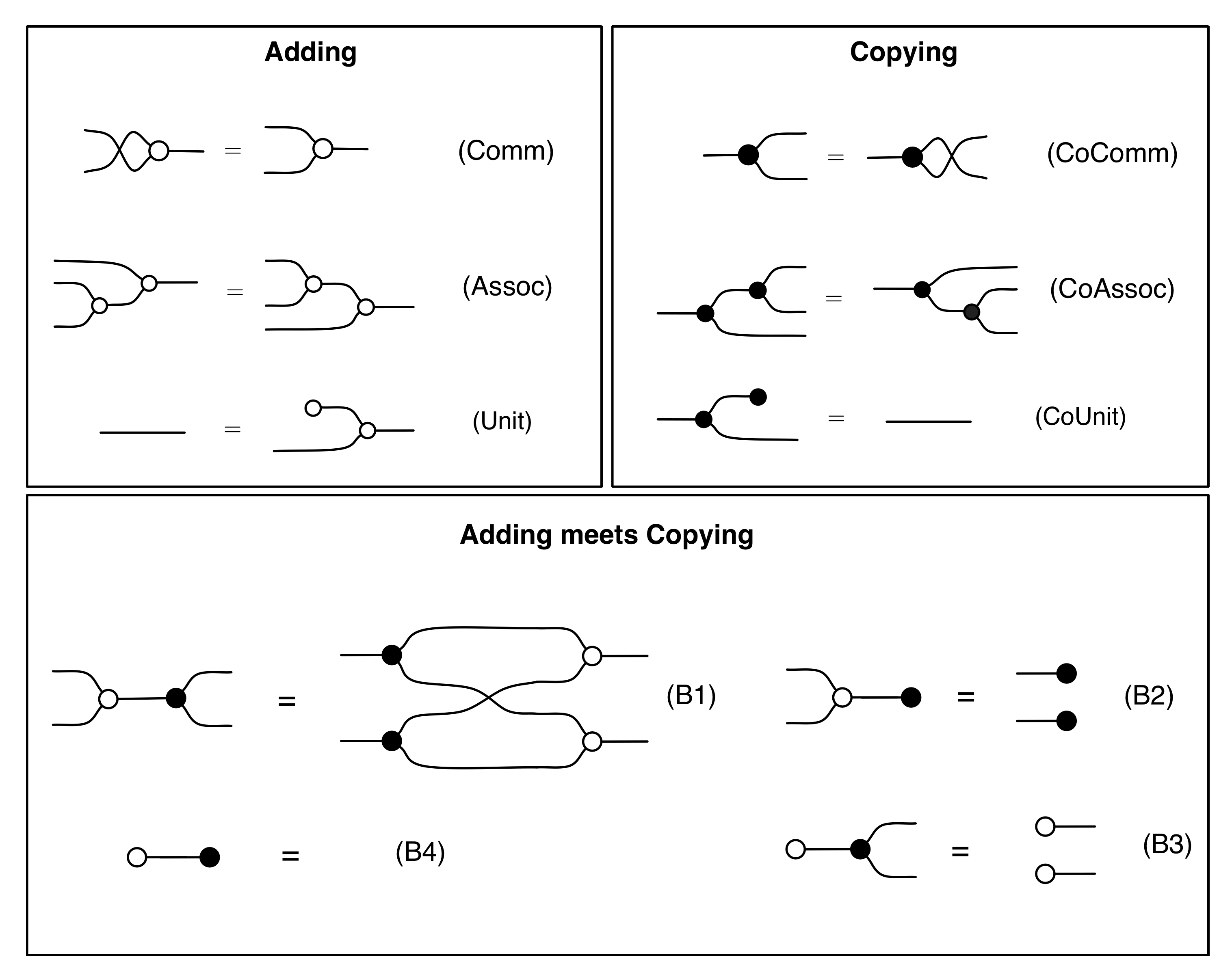
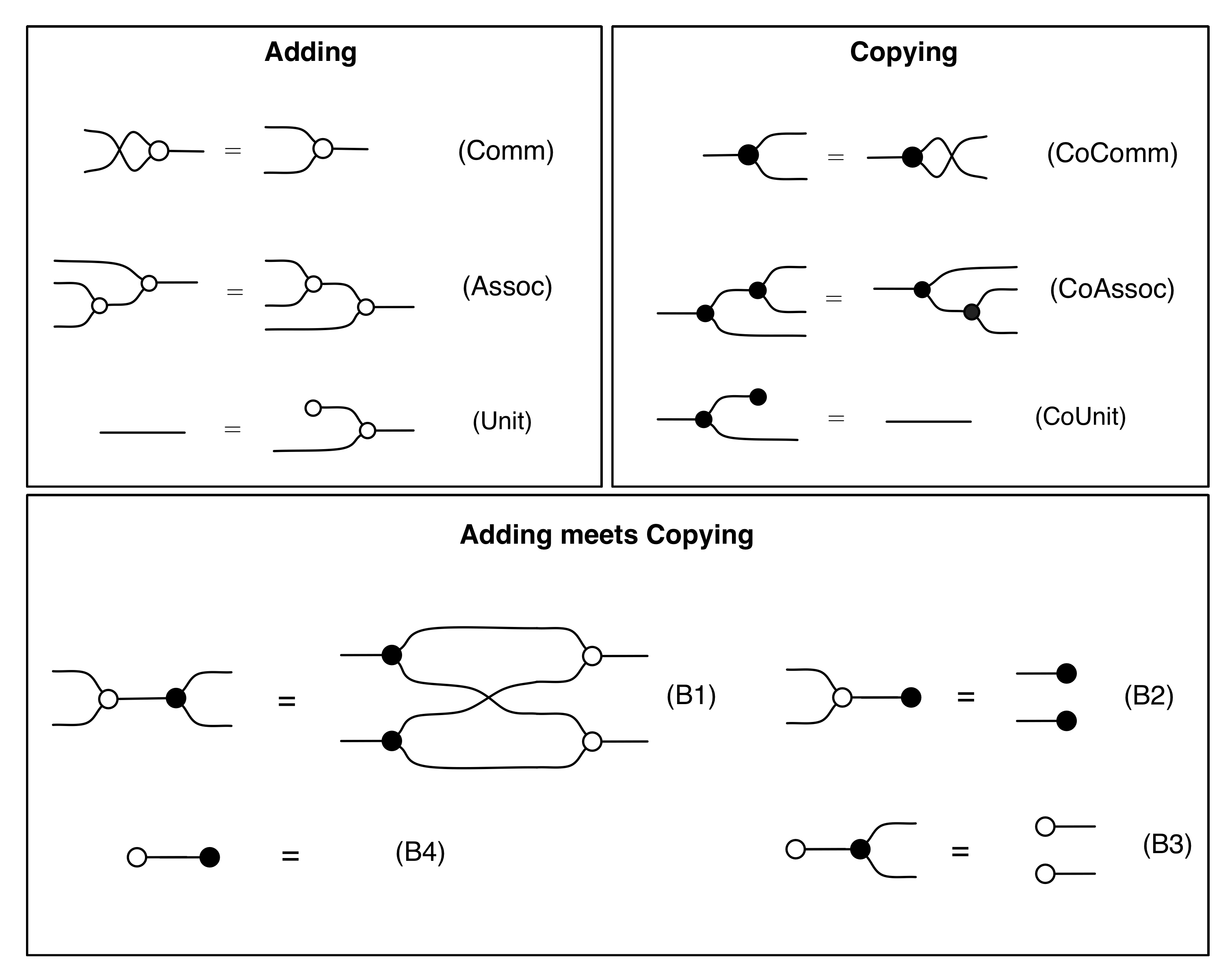
Let’s remind ourselves of the properties satisfied by these diagrams. All of the following are theorems, which we proved using only the basic equations that capture how the copying generators interact with the adding generators.

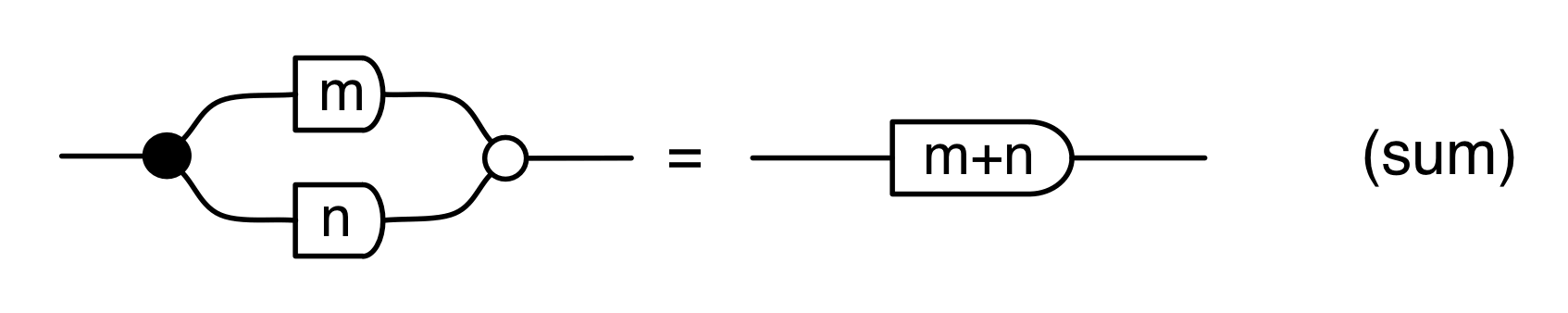
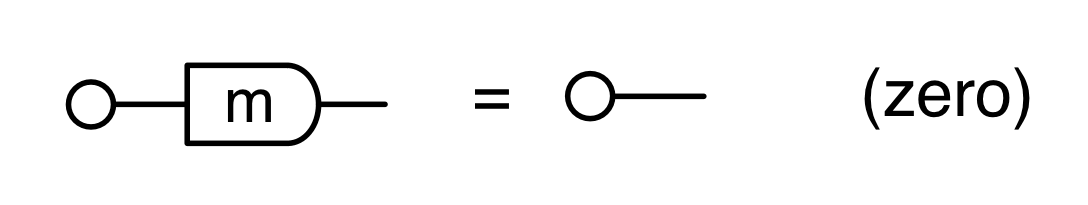


Our fifth principal actor is called the Antipode—Minus One to its friends. The antipode generator is a flamboyant character. It’s a bit of a rebel, in that it looks quite a bit different to the other characters we have met so far. This is how it will appear in this blog:
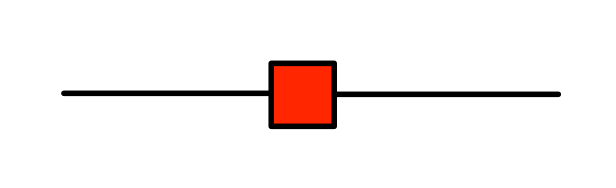 First, the colour: it’s red. This is motivated by the fact that we want the bizarro of antipode to be itself, just like the bizarro of every natural number is itself. If we coloured the antipode black or white, then this would be incompatible with our convention that bizarro, syntactically speaking, means reflecting and swapping black with white. We thus exclude red from the colour swapping game. In any case, red seems like a good choice for negative quantities: after all, if you have negative money, then you are said to be “in the red“.
First, the colour: it’s red. This is motivated by the fact that we want the bizarro of antipode to be itself, just like the bizarro of every natural number is itself. If we coloured the antipode black or white, then this would be incompatible with our convention that bizarro, syntactically speaking, means reflecting and swapping black with white. We thus exclude red from the colour swapping game. In any case, red seems like a good choice for negative quantities: after all, if you have negative money, then you are said to be “in the red“.
Second, the shape: it’s square. This contrasts with the shape of the sugars for natural numbers and matrices, which we have been pointing to the right, corresponding to the direction that numbers travel along the wires in our circuits. The fact that the antipode doesn’t play by the same rules is not an arbitrary choice, as we will see in a few episodes.
Let’s get an idea for what the antipode does, using the intuition of numbers travelling along wires. As we have seen in Episode 9, the natural number sugars act by multiplying their input by the natural number they represent. Similarly, the antipode acts by multiplying its input by -1. So, if a number x arrives on the left dangling wire, the number -x will exit on the right dangling wire, like so:
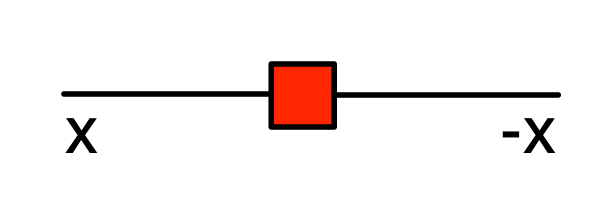
It’s time to meet the equations that involve the antipode. The antipode pretends to be a number; but unlike natural numbers it is a bona fide generator and not defined in terms of other generators. We therefore need to take some of the properties satisfied by natural numbers as basic equations of the expanded system.
Let’s start with how the antipode relates to the copying structure. First we have the antipode version of (copying):
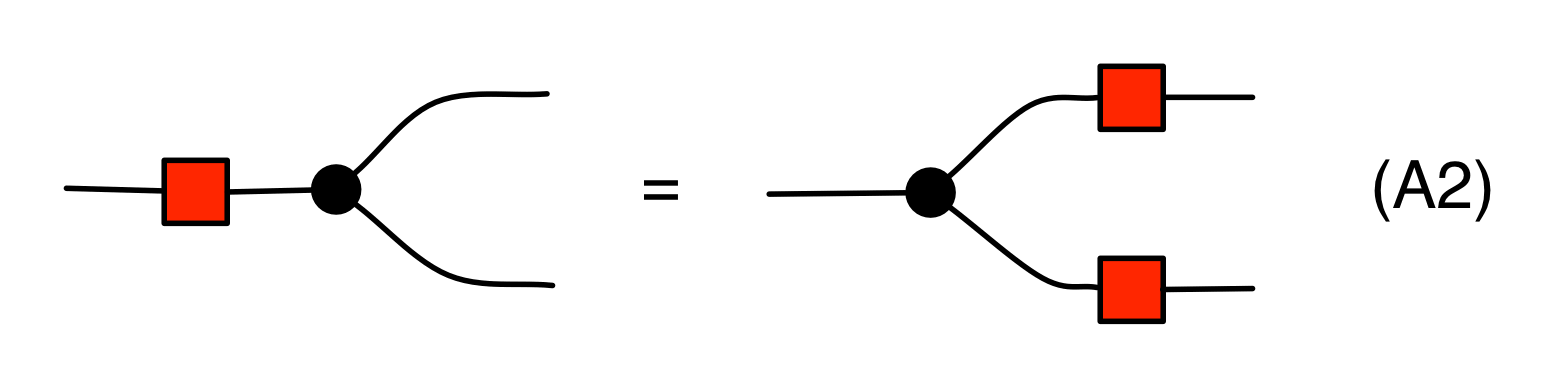 that says that multiplying any number by -1 and then copying it gives the same results as if we had first copied the number and then multiplied each copy by -1. Next we have an equation that resembles (discarding):
that says that multiplying any number by -1 and then copying it gives the same results as if we had first copied the number and then multiplied each copy by -1. Next we have an equation that resembles (discarding):
 which simply says that multiplying any number by -1 and discarding it is the same as simply discarding.
which simply says that multiplying any number by -1 and discarding it is the same as simply discarding.
The bizarro versions of (A2) and (A3) are included as well. The first of these is the following, which is the antipode equation that corresponds to (adding).
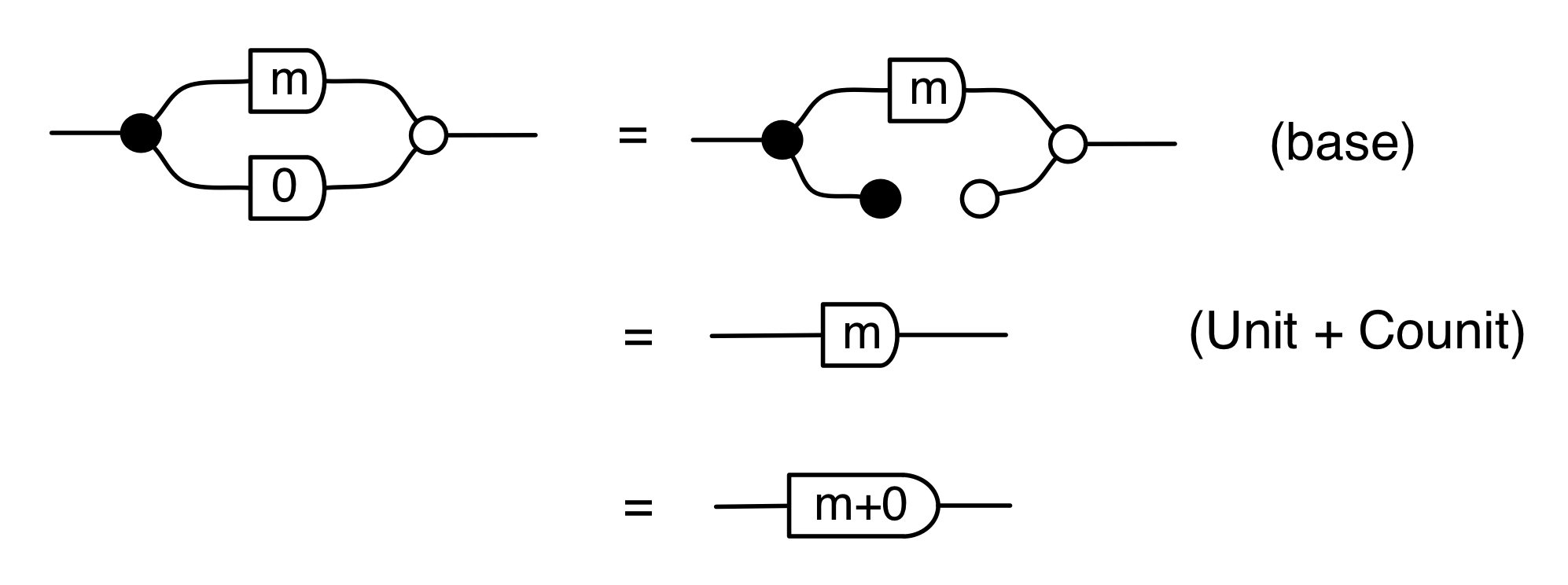
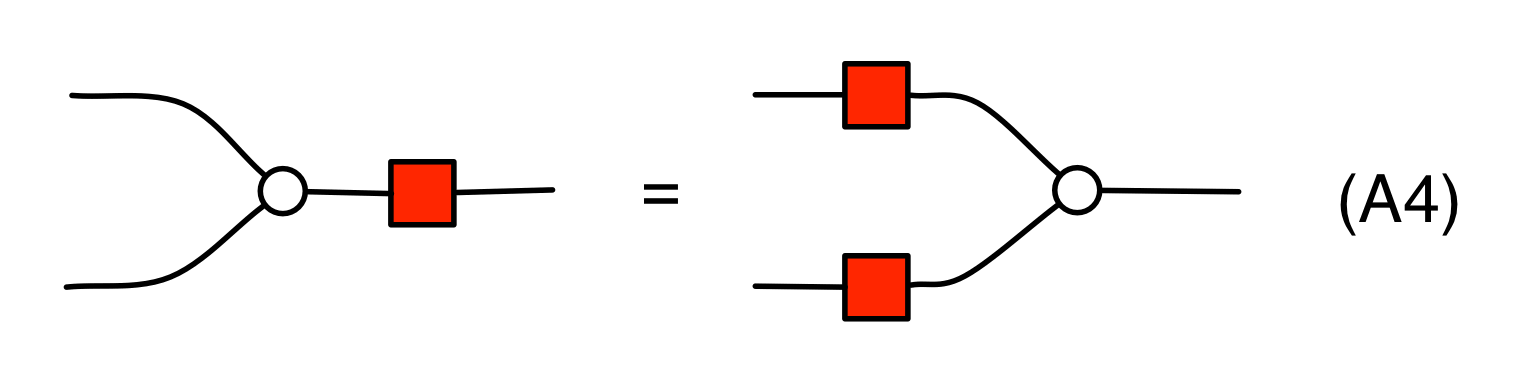 It can be understood as saying that for all numbers x and y we have that -(x + y) = -x + -y. Finally, we have the fact that -0 = 0, which is the antipode version of (zero).
It can be understood as saying that for all numbers x and y we have that -(x + y) = -x + -y. Finally, we have the fact that -0 = 0, which is the antipode version of (zero).

Clearly, in each of (A2), (A3), (A4) and (A5) the behaviour of the left hand side and the right hand side is the same.
The final and most important equation tells us how that antipode acts as the additive inverse of 1. Interestingly, it is the only equation of the system that involves all the generators that we have seen so far!
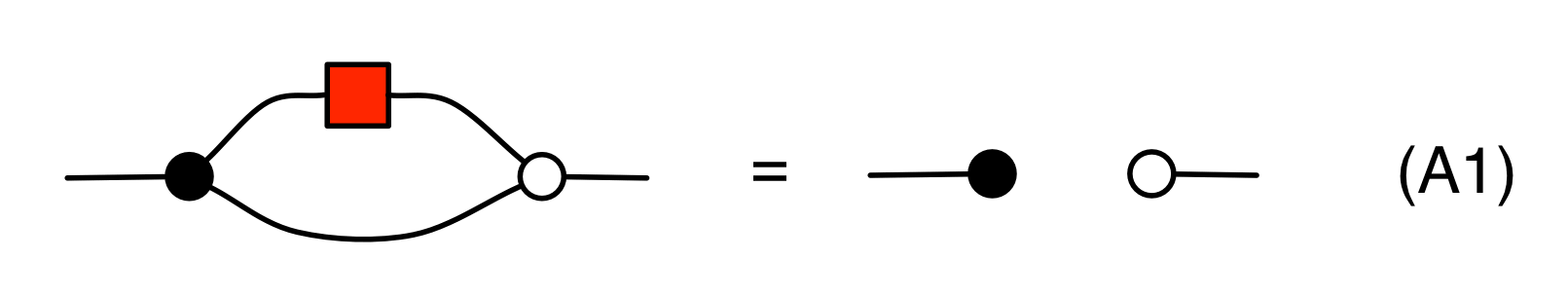
Since it is the most important, let’s spend a little bit of time understanding why it is compatible with our intuitions. First the left hand side.
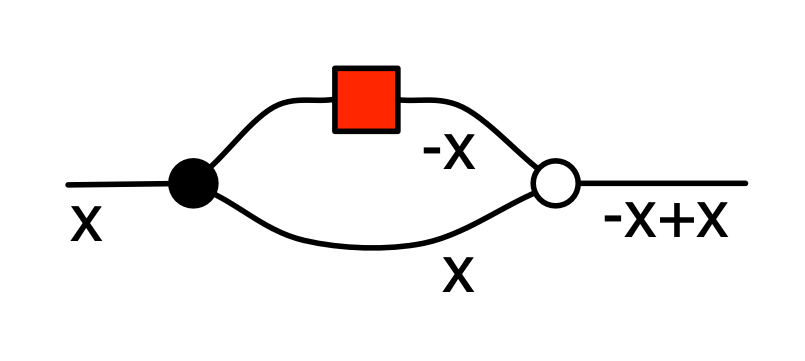
A number x arrives on the left, it is copied and the first copy passes through the antipode. So -x and x are fed to the adder, which then spits out -x+x.
The right hand side of (A1) accepts x on the left and emits 0 on the right. But for any x we have that -x+x=0, so the behaviours of the two sides agree.
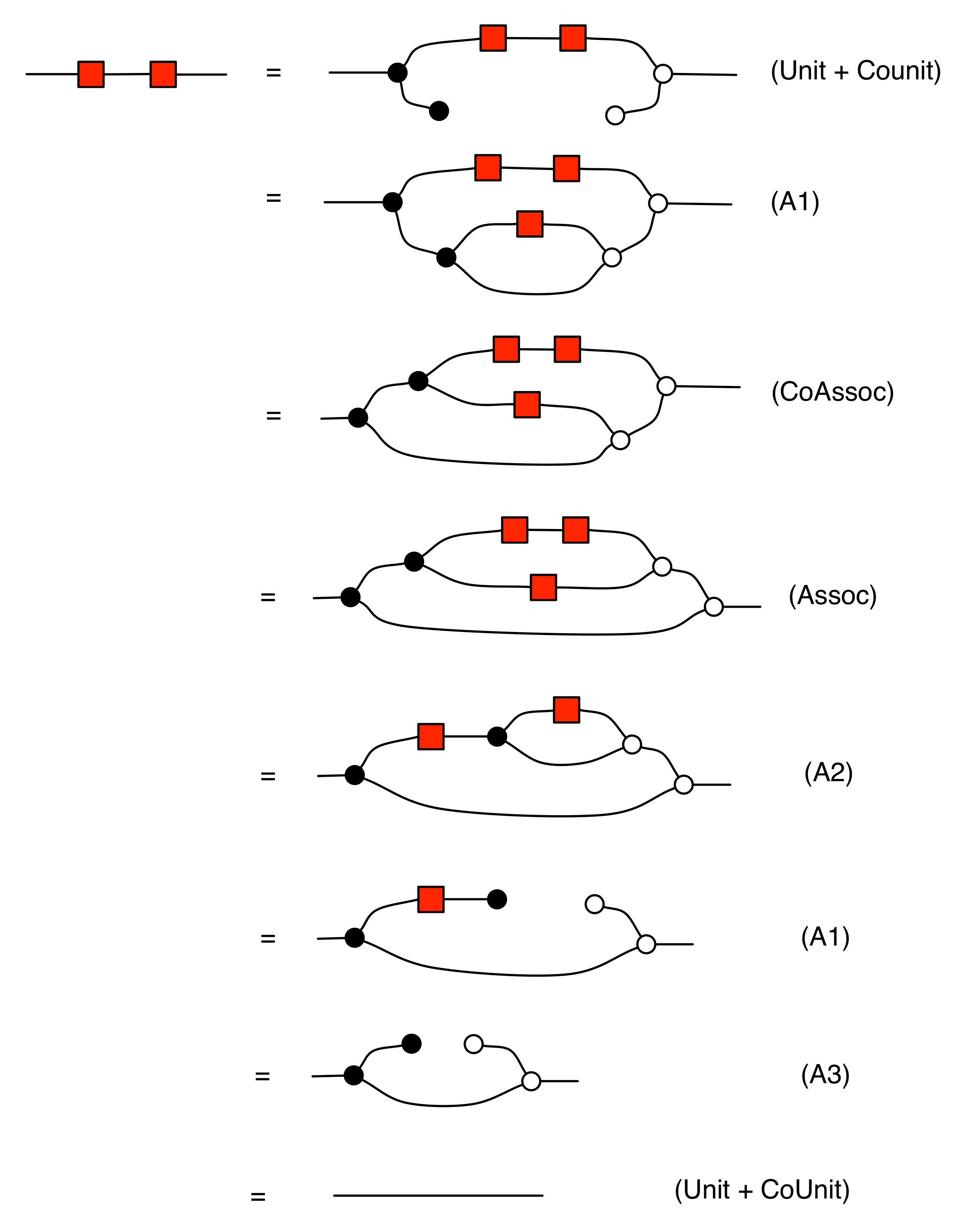
That takes care of all the equations we need. Let’s collect the entire expanded system in a handy cheat sheet:

We gave the name B to the diagrammatic language described by the first three panels, which stands for (bicommutative) bimonoids, or bialgebras. We will refer to the expanded system that includes the antipode generator and equations (A1)–(A5) as H, which stands for (bicommutative) Hopf monoids or Hopf algebras, which is the name that these structures are often called by mathematicians.
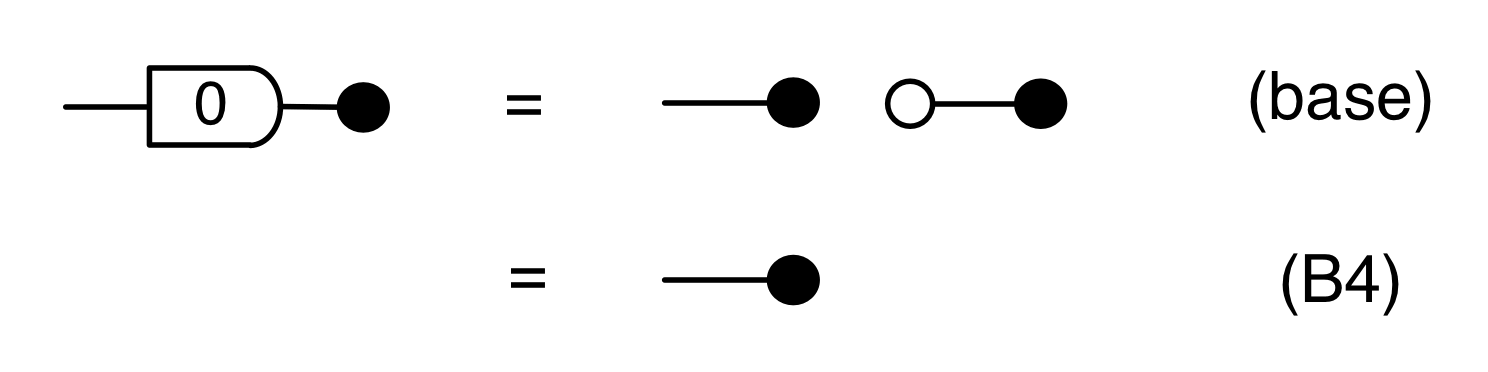
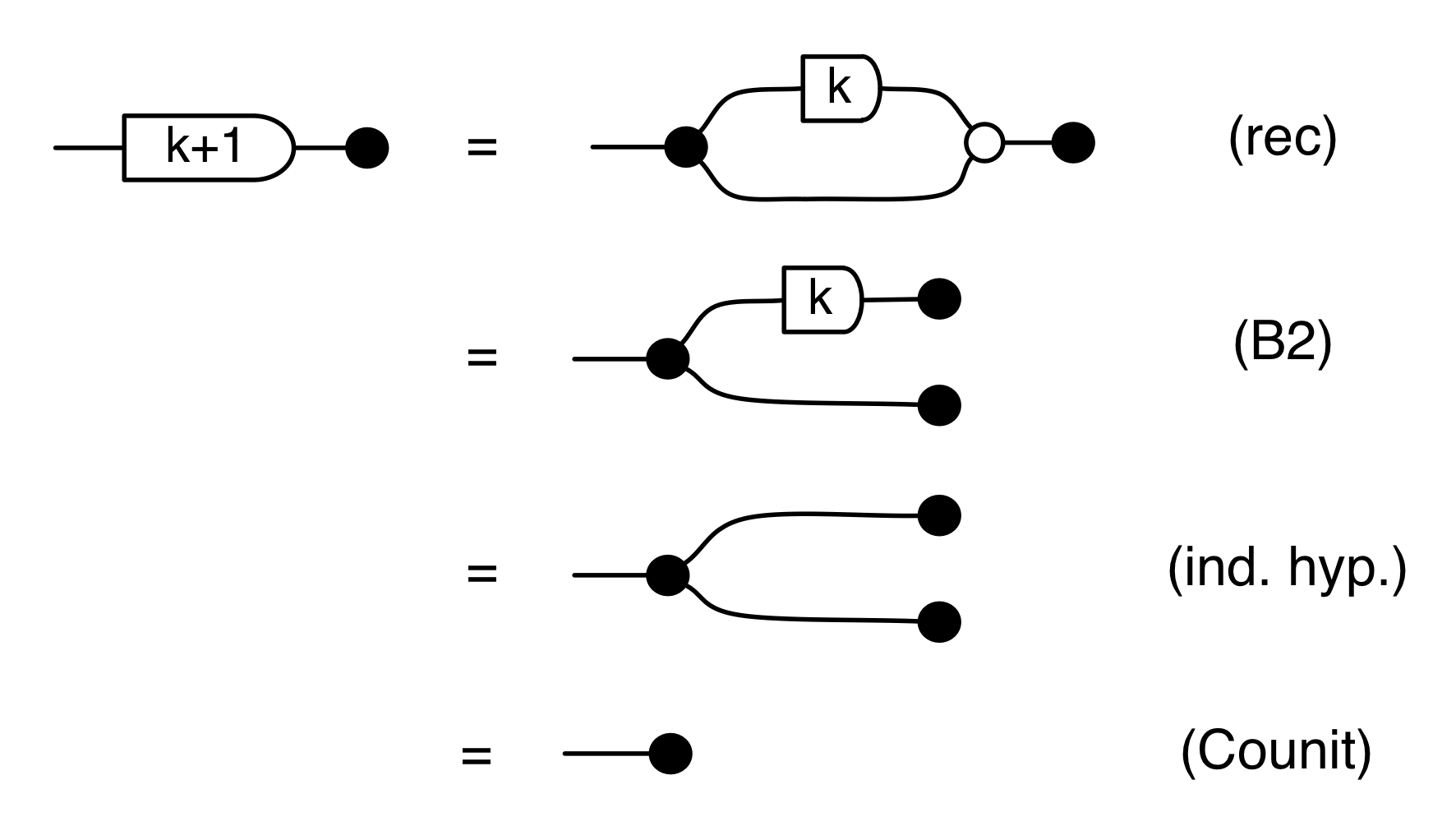
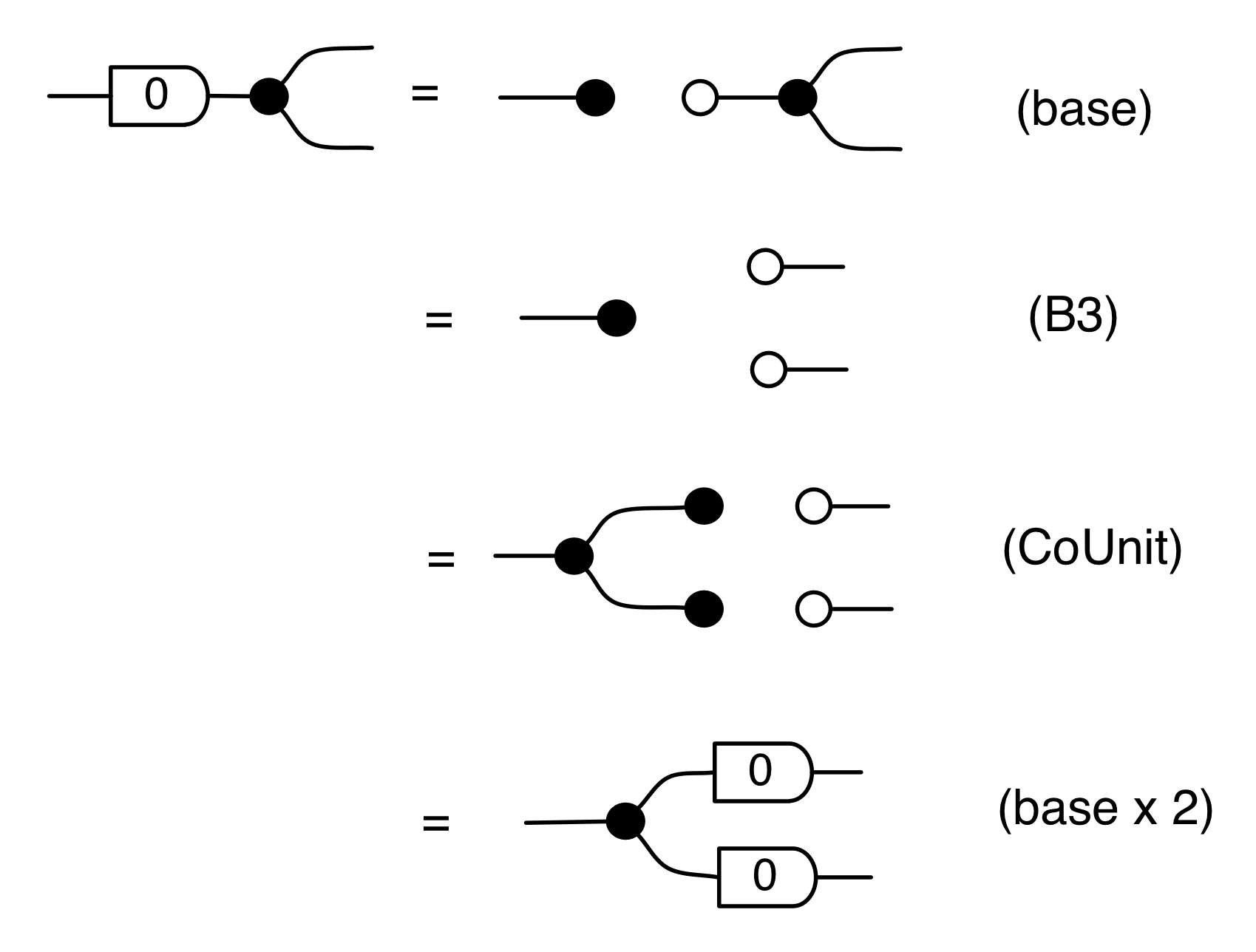
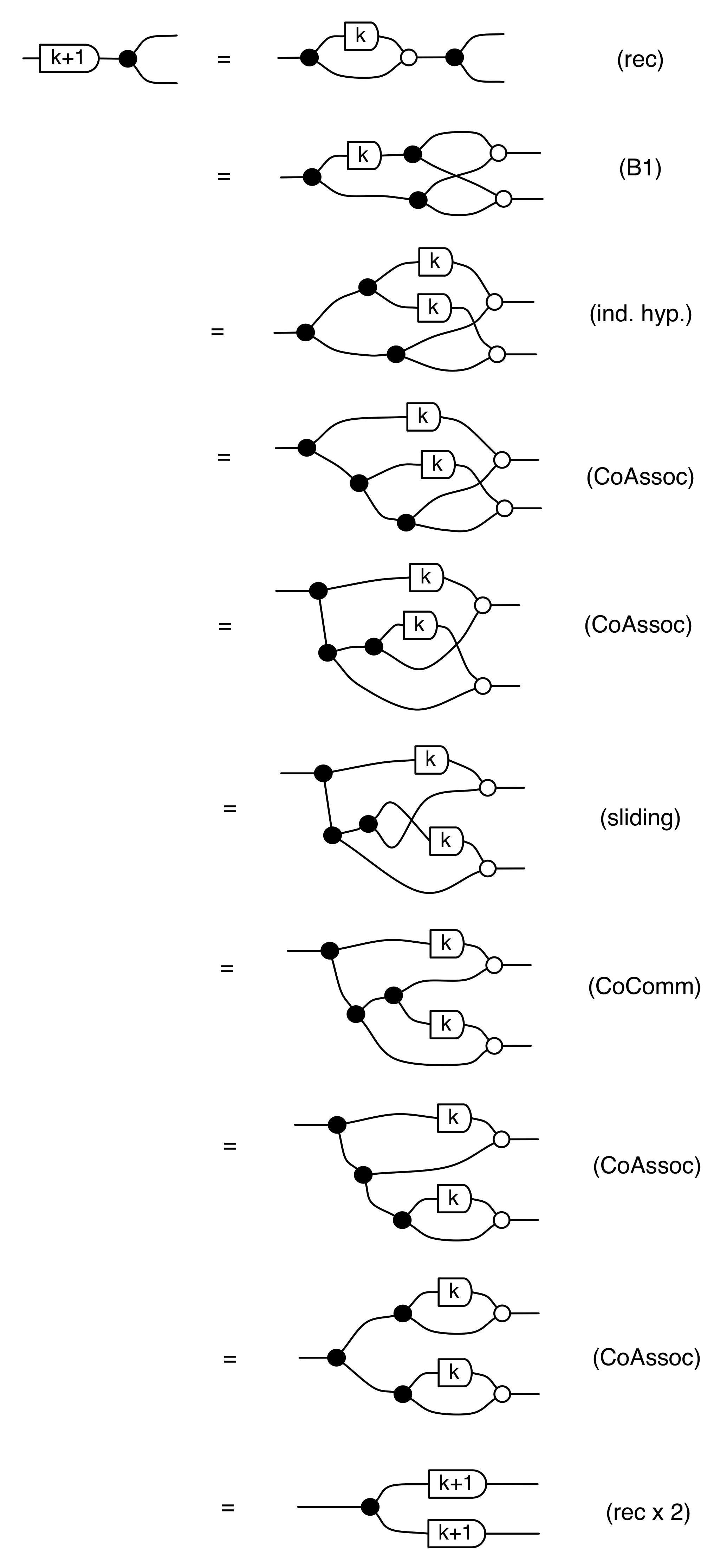
There are a number of interesting things that we can prove, using the basic equations. The first is that composing the antipode with itself gives the identity wire, which is the diagrammatic way of saying that -1⋅-1 = 1.
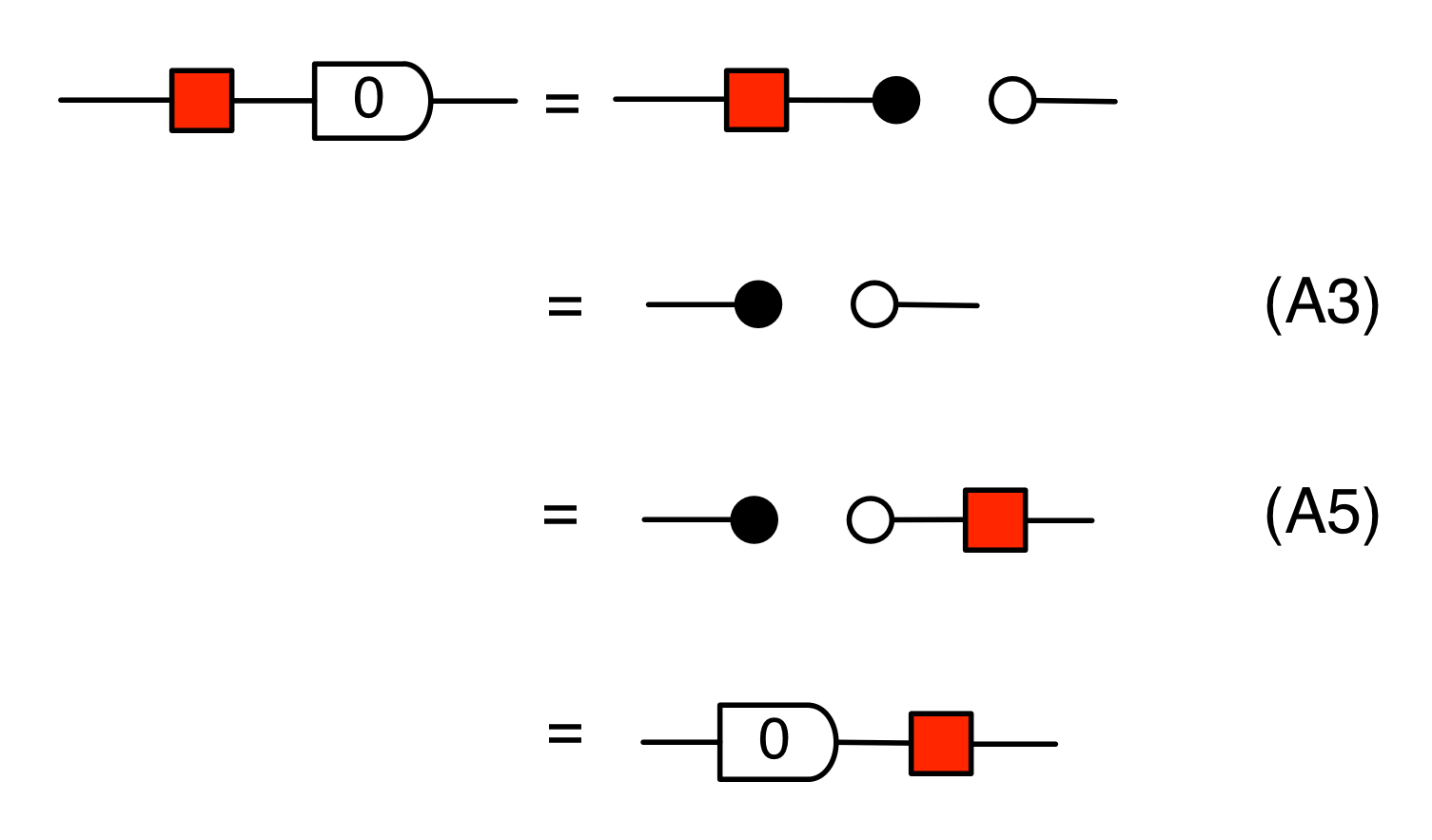
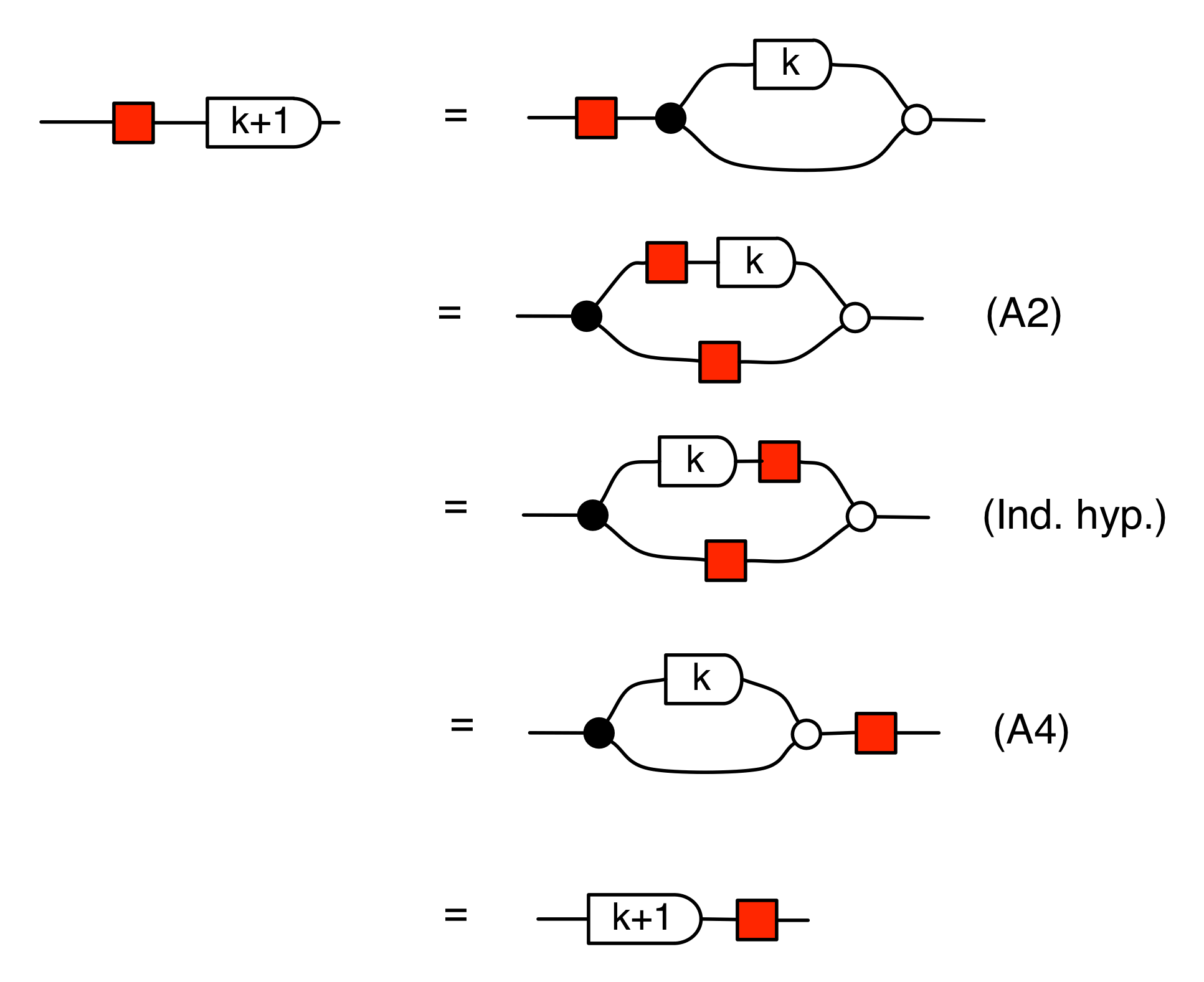
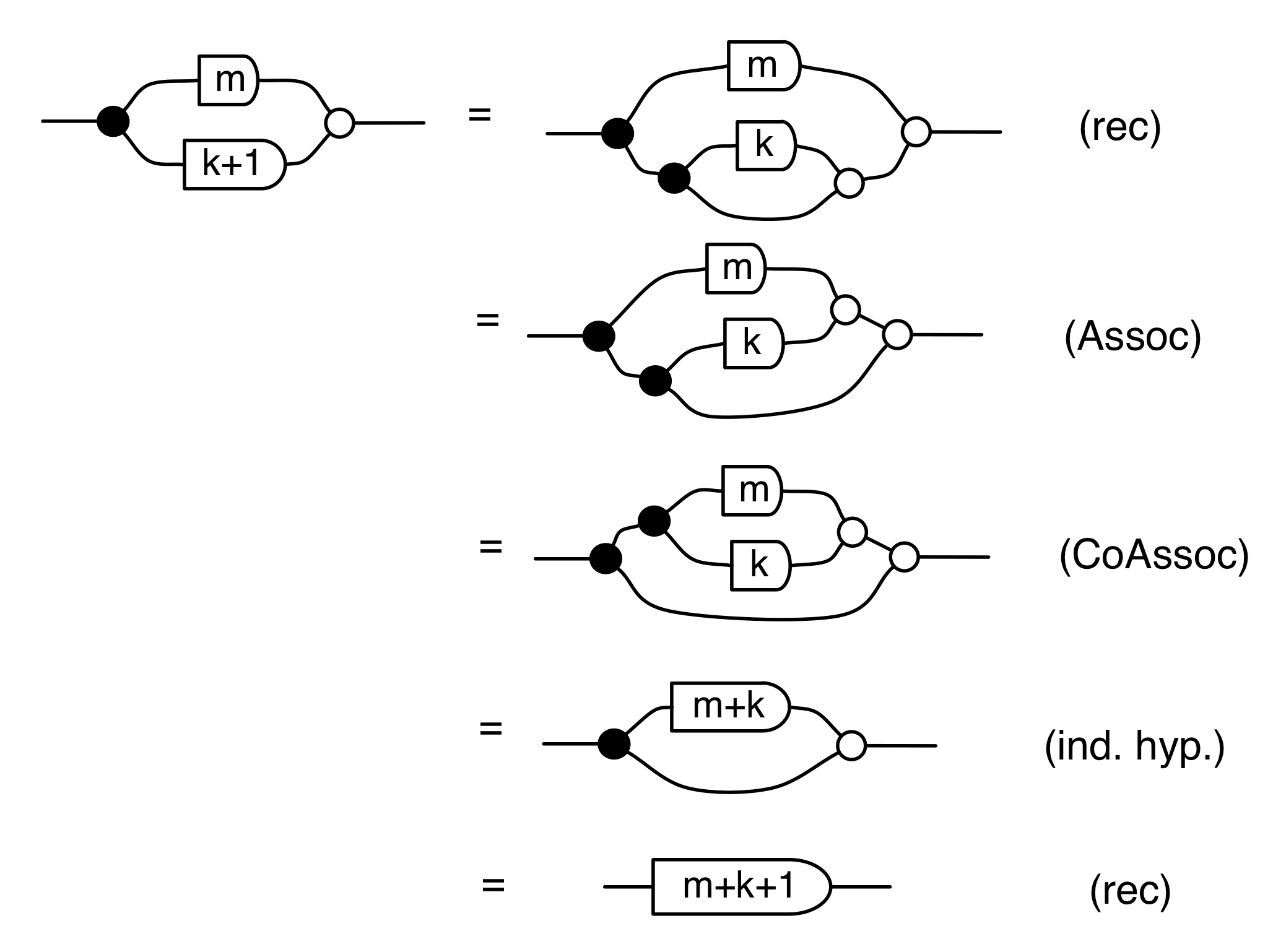
Another useful fact is that the antipode commutes with all the other natural numbers. That is, for all natural numbers n, we have the following:

We can prove this property by induction. First, the case n=0:
and the inductive step, for n=k+1:
We will now extend the syntactic sugar for natural numbers to integers; indeed, the antipode gives us a nice way to consider all integers diagrammatically. Since we already know how to deal with zero and the positive integers, the only remaining case is negative integers. Here, assuming that n is a positive natural number, we can define:

This extension of the syntactic sugar from natural numbers to integers seems to be simple enough, but how do we know that it “really works”? One way of making sure is to check that the algebra of integers as we know it is compatible with the algebra of diagrams: properties such as (multiplication) and (sum) ought to work for all the integers.
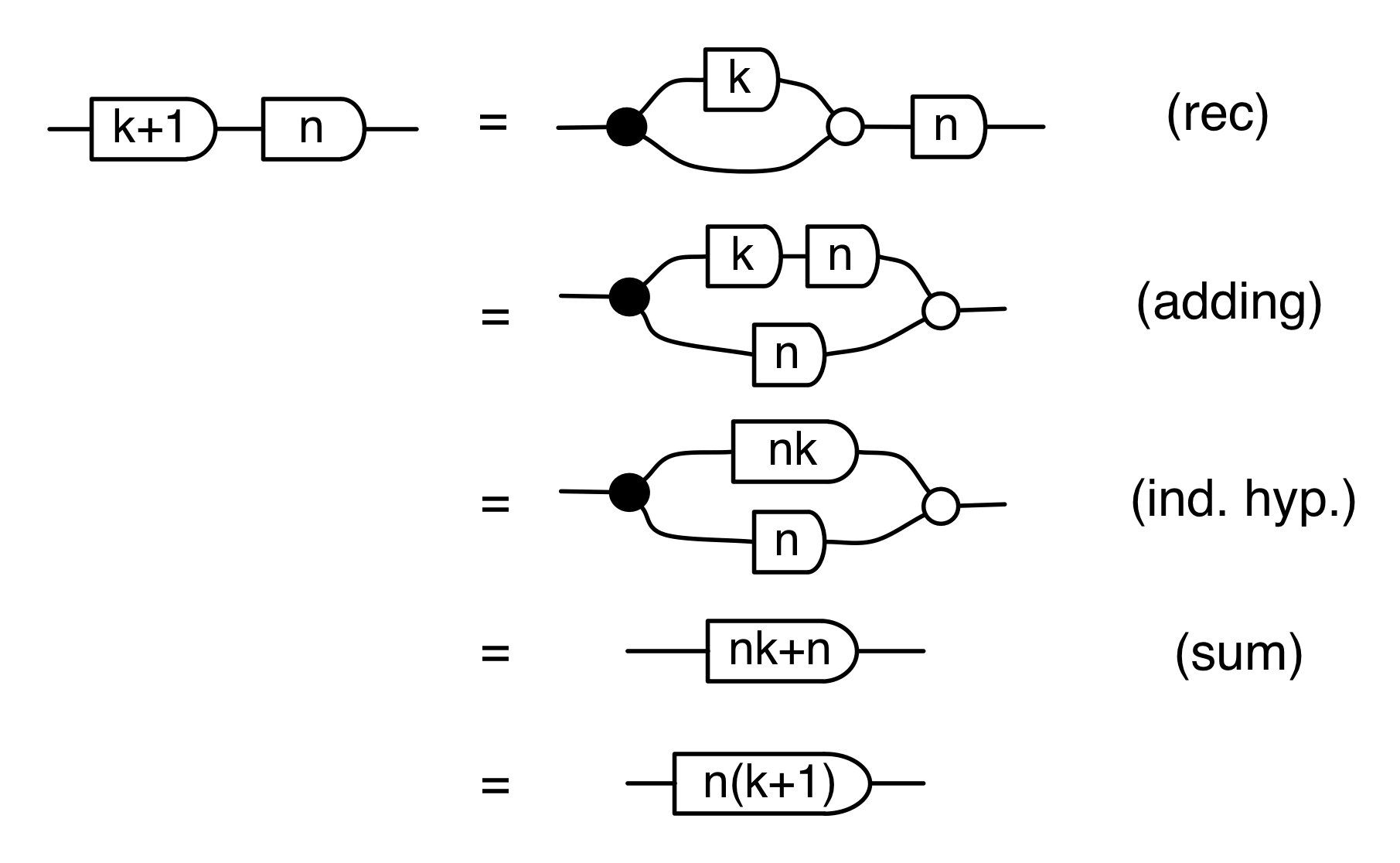
So, let’s assume from now on that u and v are (possibly negative) integers. First, let’s consider the multiplication property:

This is easy to prove from the facts that we have already established: the antipode commutes with the natural numbers and, diagrammatically, -1 ⋅ -1 = 1. Since we already know from Episode 9 that (multiplication) holds when u and v are positive, it’s enough to consider the cases where one or both of them are negative. Try it yourself!
To prove that summing up two integers works as expected takes a little bit more work. We want to prove the following:

When u and v are both non-negative then we do not have to do anything; we already proved this property by induction in Episode 9. If u and v are both negative then they are of the form -m and -n for some positive m and n. So let’s show that the property holds in that case:

In the first and the last line we used the definition of the sugar for negative integers, and in the second last line the property (sum) for natural numbers. And, of course, -(m+n)=(-m)+(-n), so we’re done.
We are left with the case where precisely one of u and v is positive and the other negative. Without loss of generality, we can assume that u is negative, that is, it is of the form -m where m is a natural number, and v is non-negative, that is, it is a natural number n. We don’t lose generality because if they were in the other order, we could simply swap them using commutativity of sum, which we proved in the last episode.
The idea now is to do a simultaneous induction on m and n. The base cases, where m or n (or both) are 0, are simple to verify: try it. Once we have established the base cases, the inductive case goes as follows:
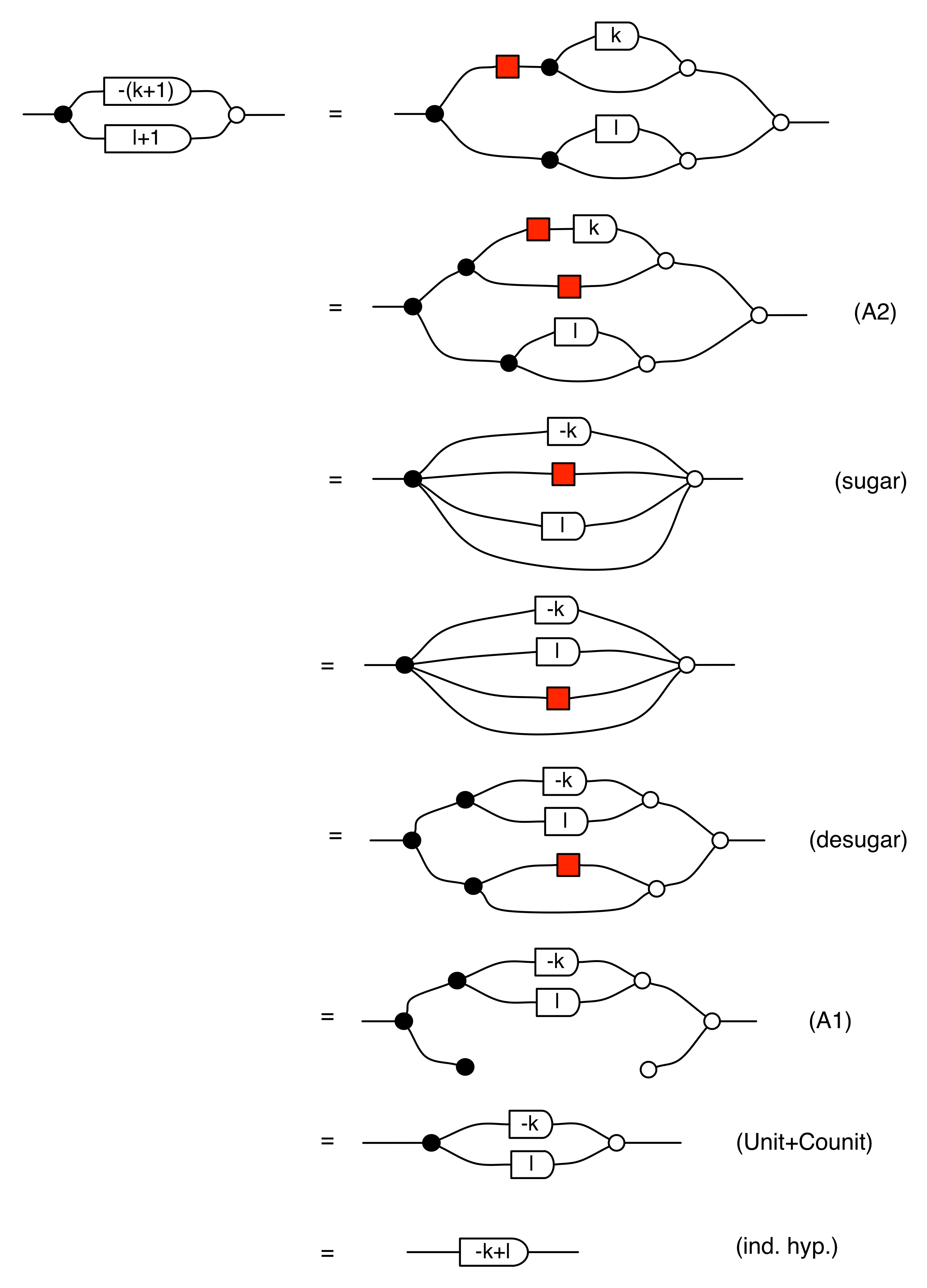
In the third and the fourth line of the proof above we used the definition and a useful property of the syntactic sugar from Episode 10. The final thing to notice is that -(k + 1) + ( l + 1) = -k + -1 + l + 1 = -k + l + -1 + 1 = -k + l. That completes the proof of the claim that (sum) works for all integers.
The final thing to be said is that also (copying), (discarding), (adding) and (zero) hold for all integers: this is easy to see since they hold for natural numbers and equations (A2)–(A5) postulate that they hold for the antipode generator. Armed with this knowledge we can prove, for example, that multiplication distributes over addition for integers.
In the next episode we will see that just as the diagrammatic system B gave us a diagrammatic language for matrices of natural numbers, system H gives us a language for matrices of integers. Then we will be able to move on to the really cool stuff!
Continue reading with Episode 19 – Integer Matrices.




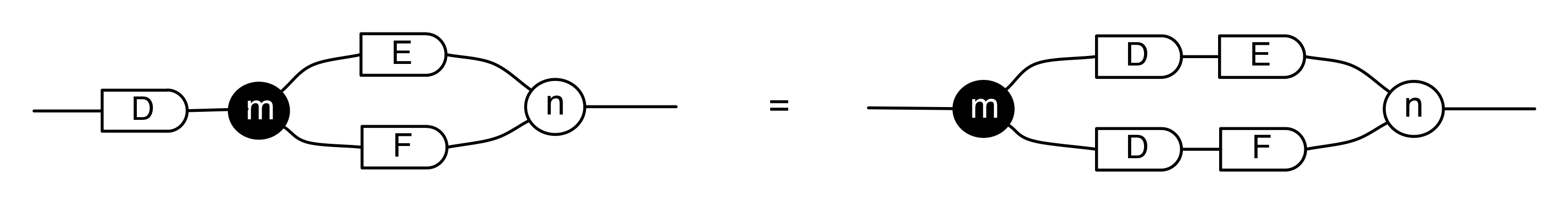






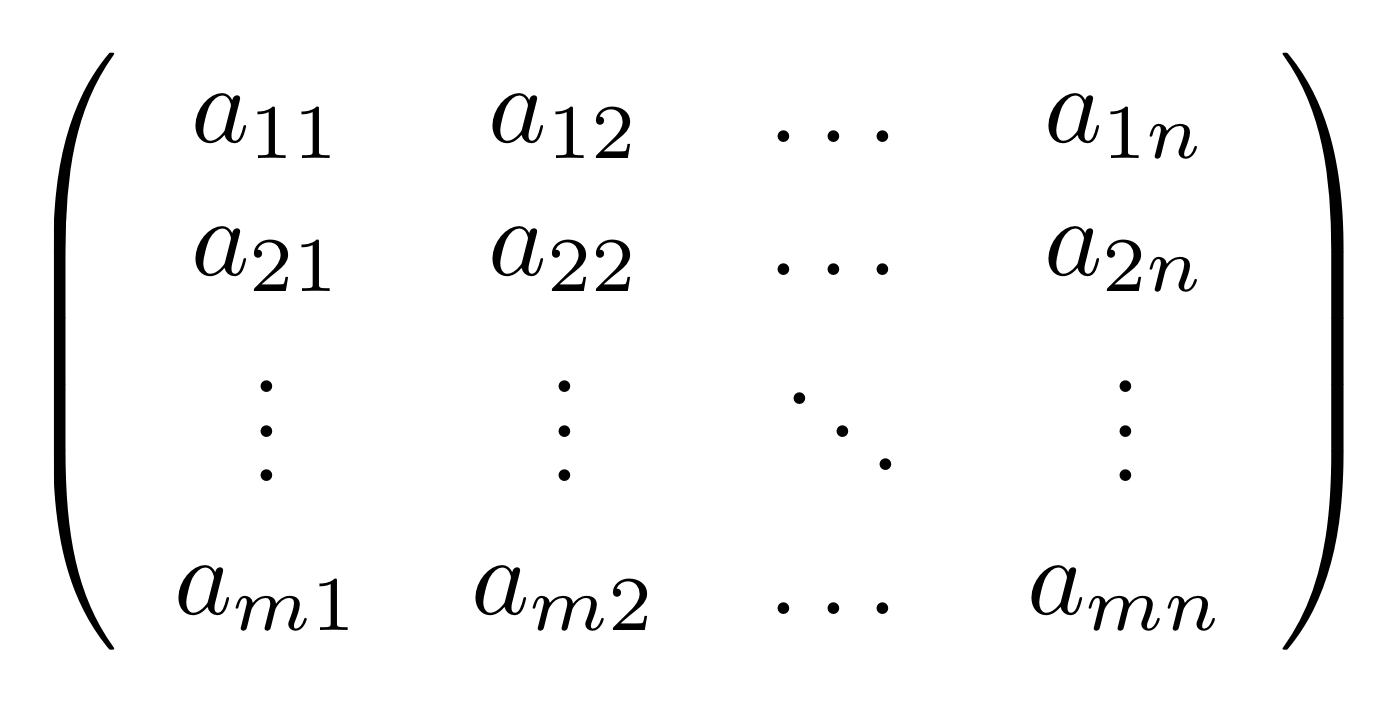













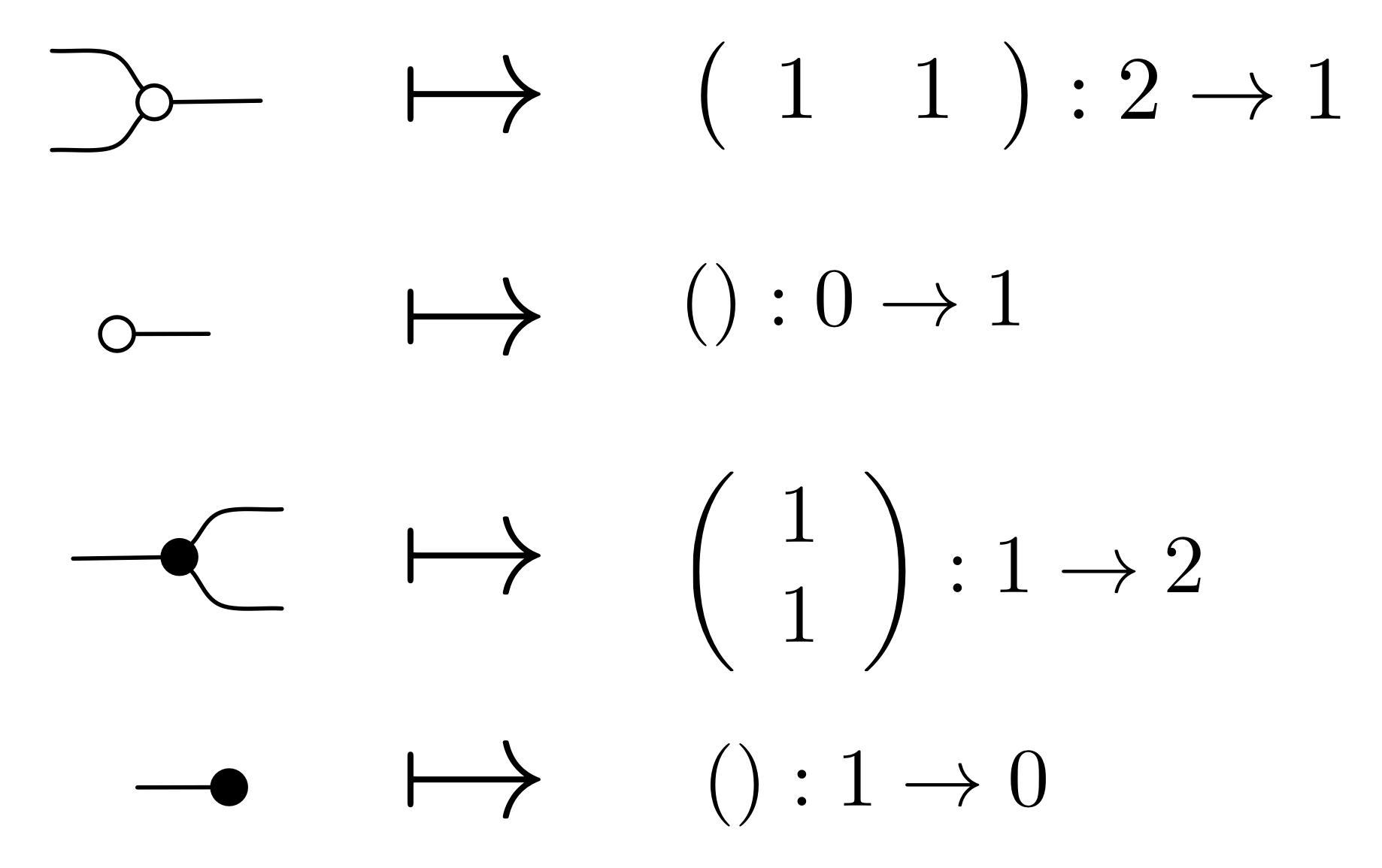
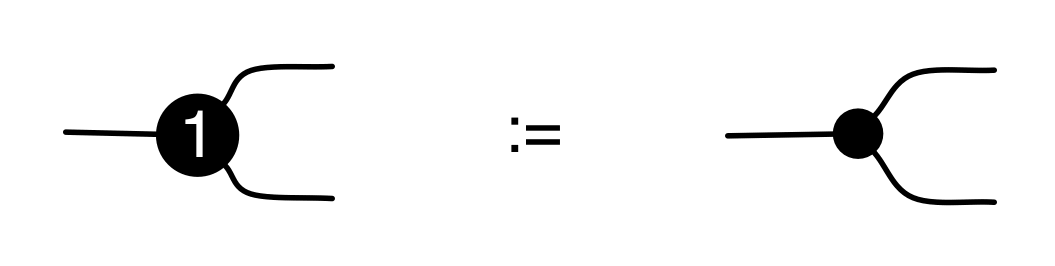
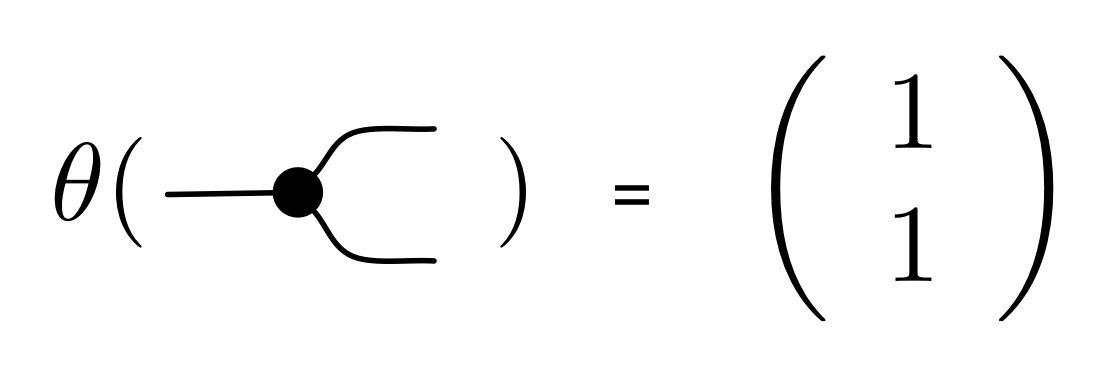
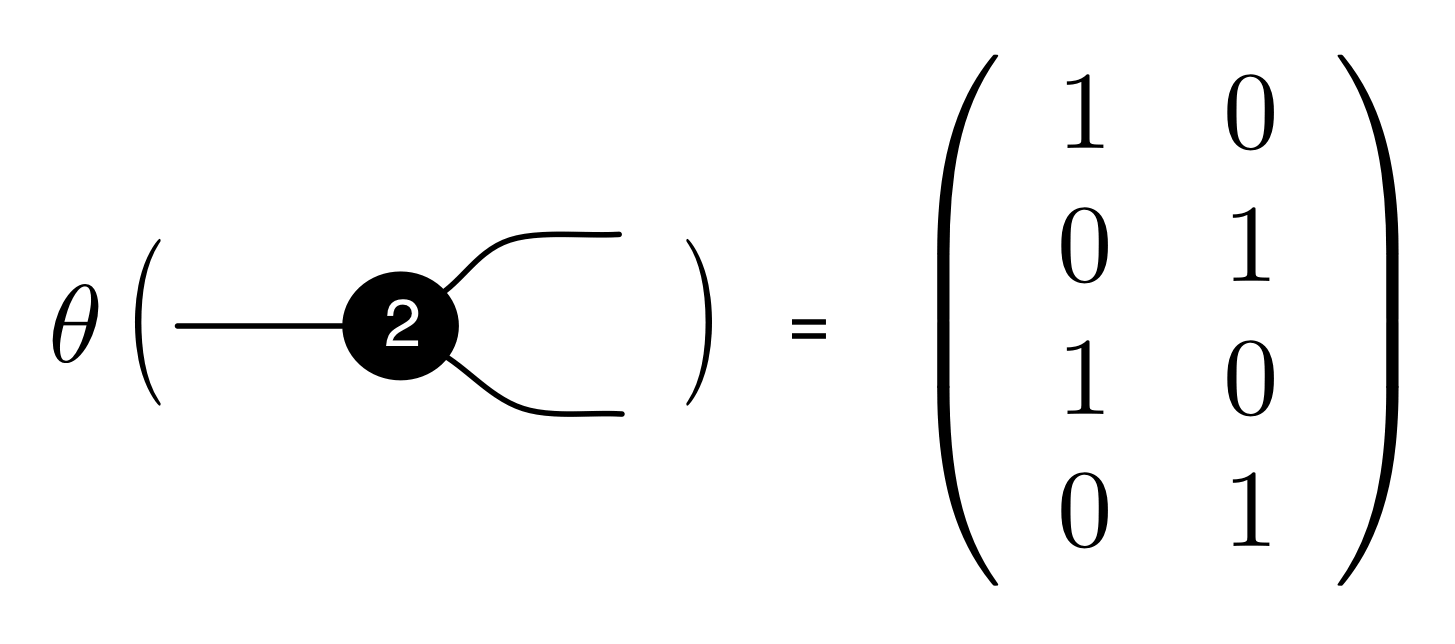

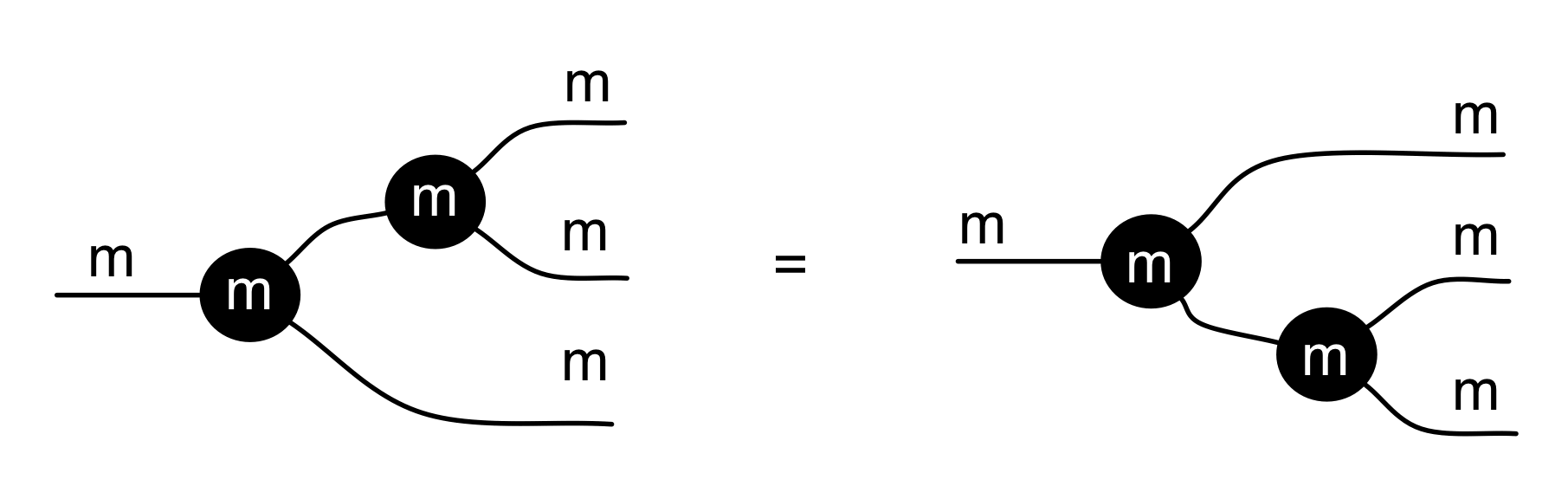
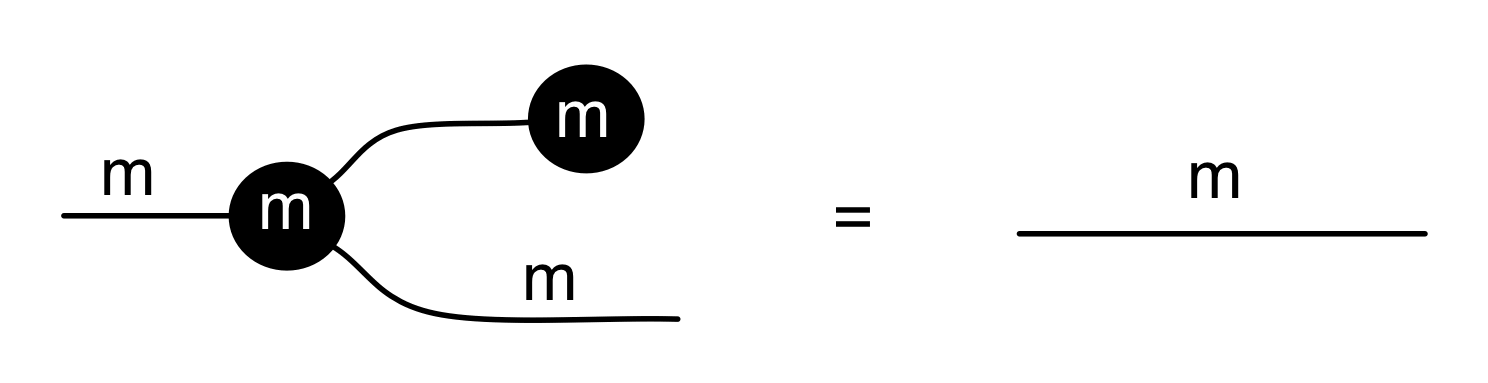
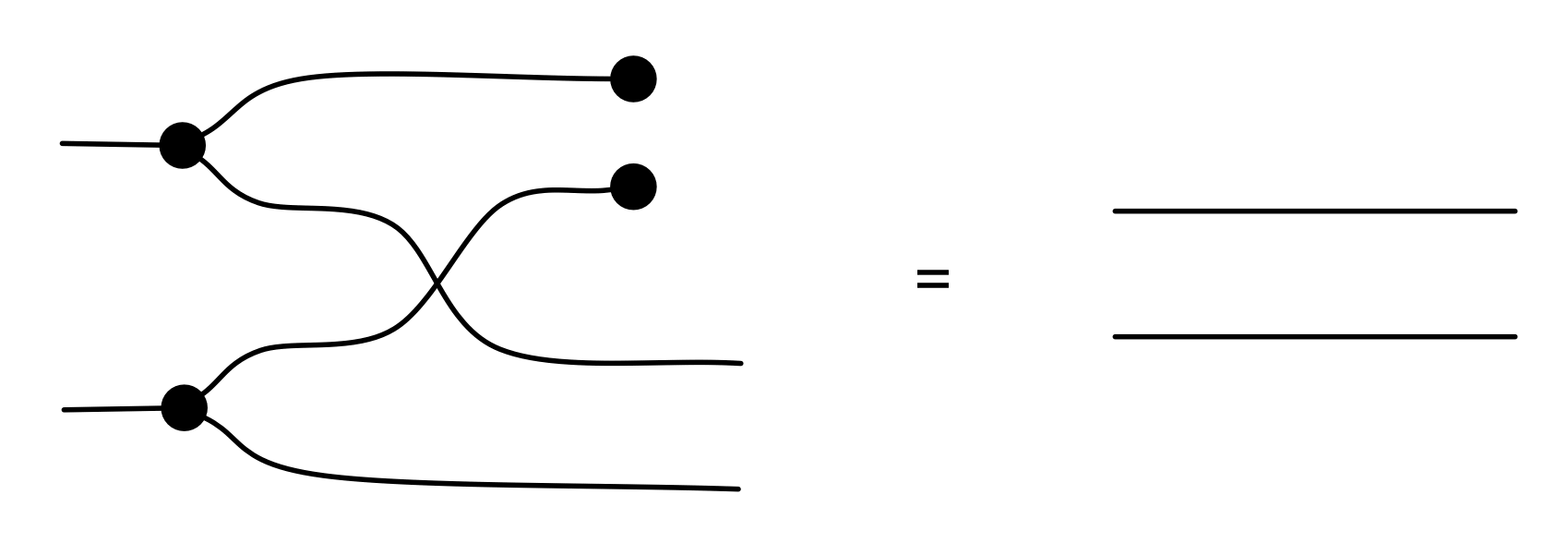
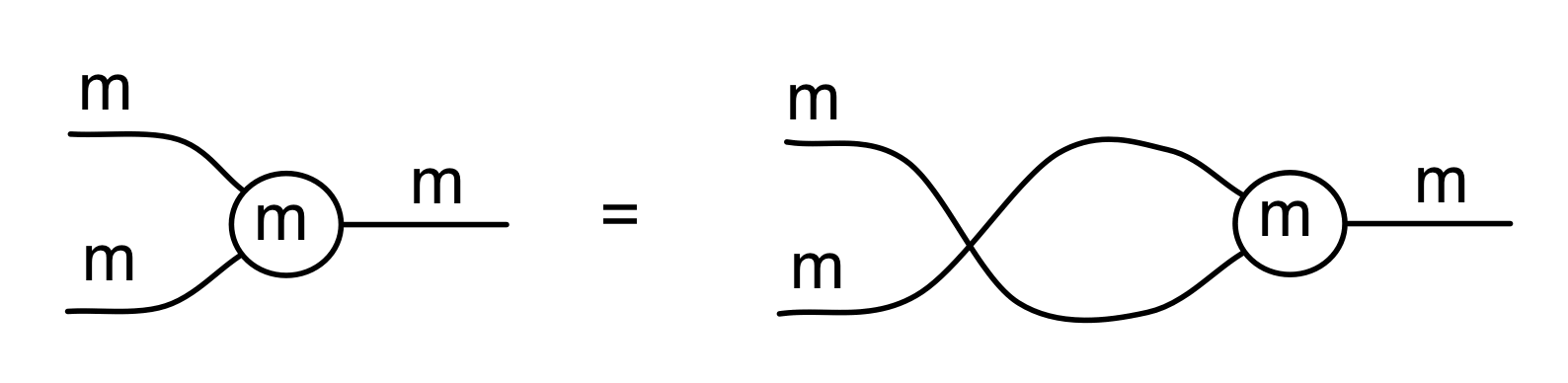
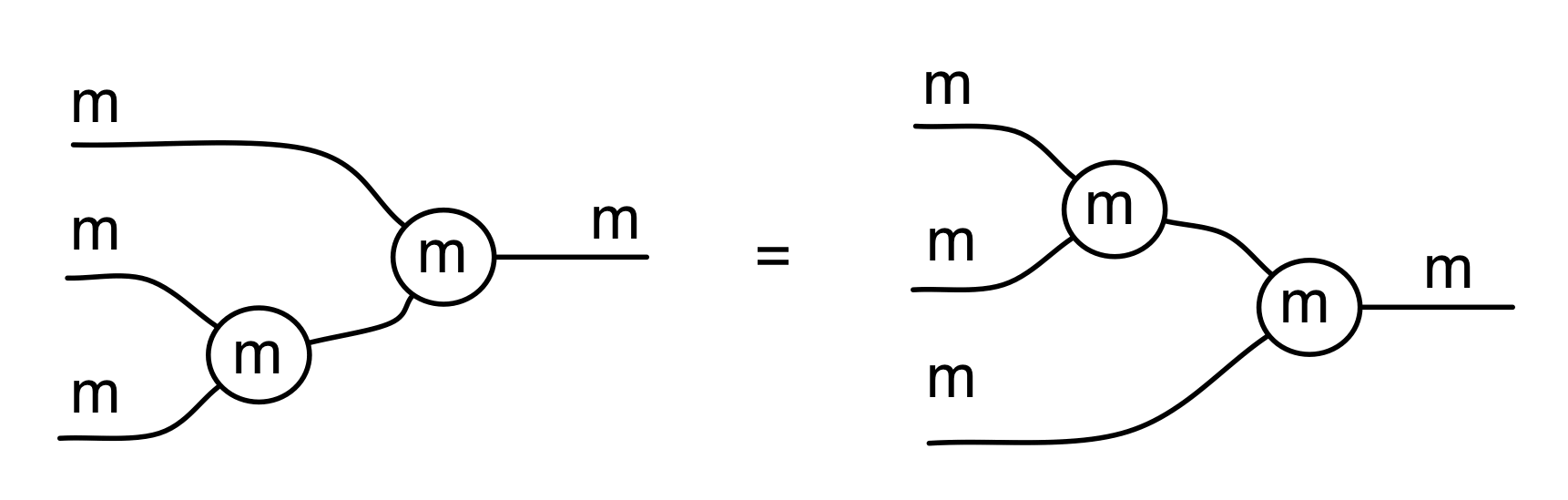


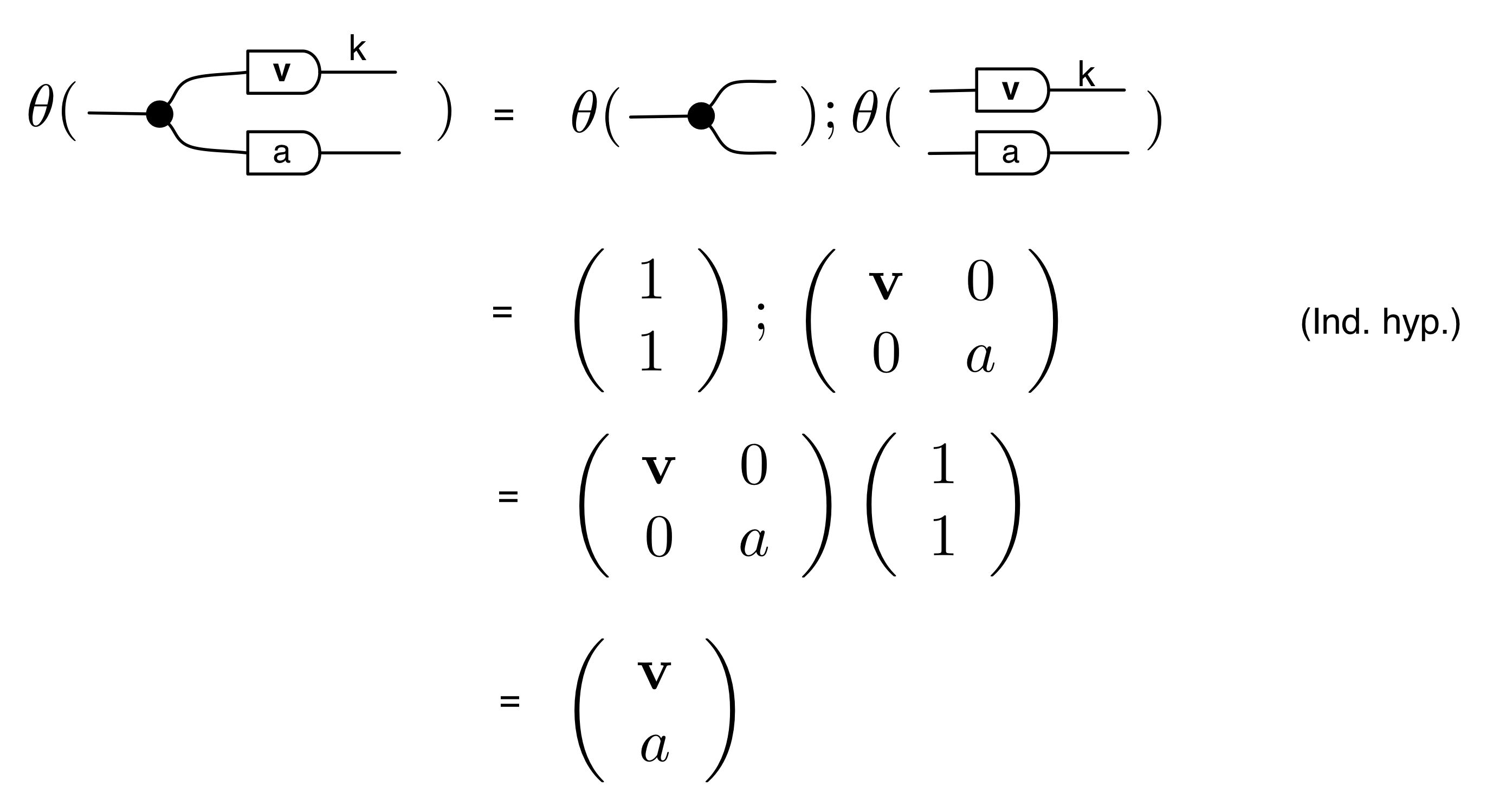
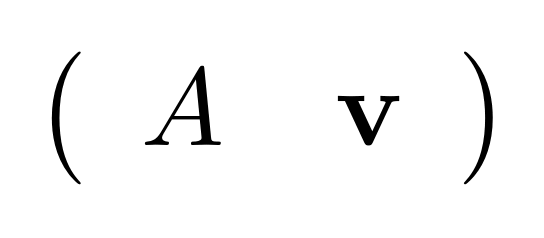
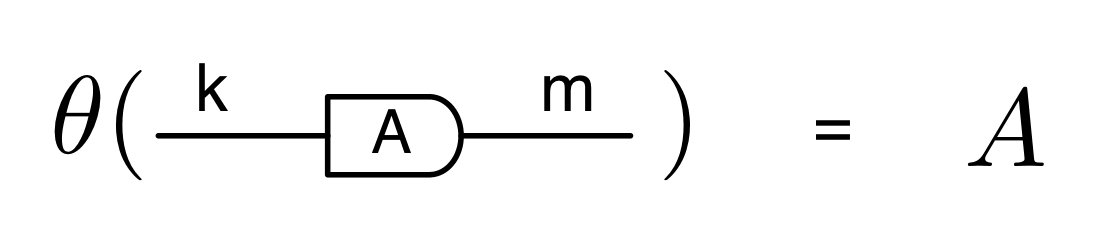
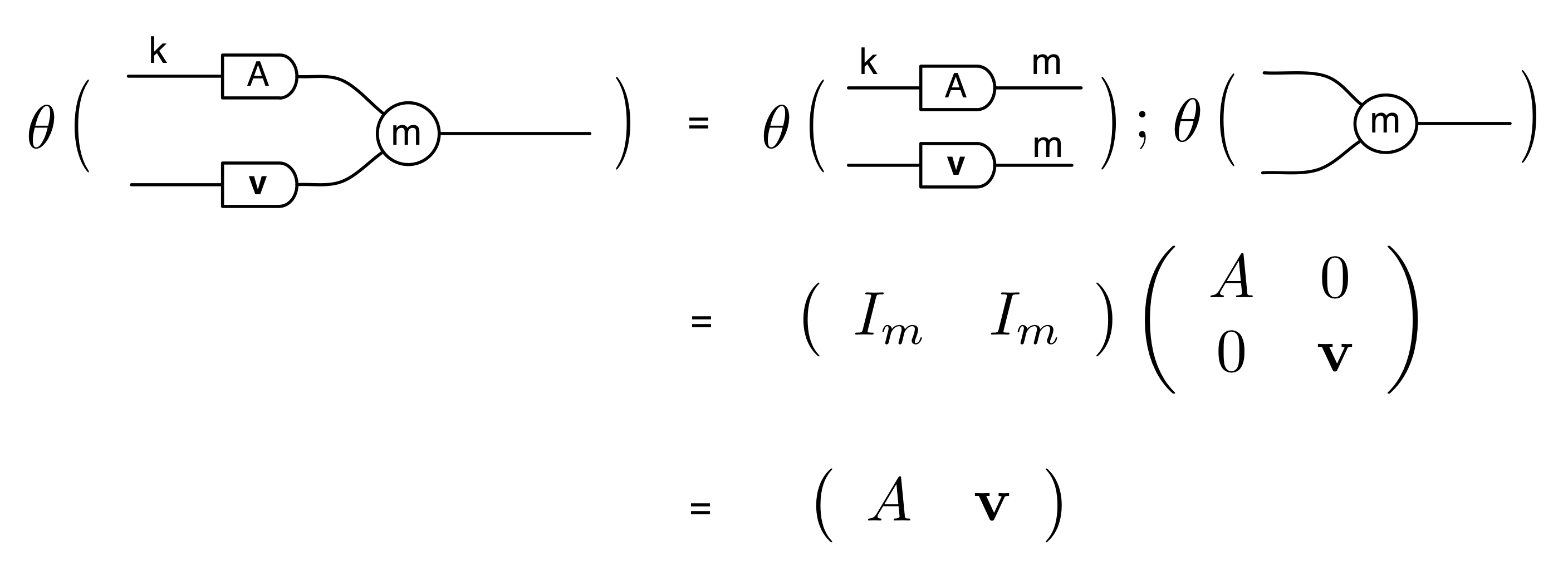
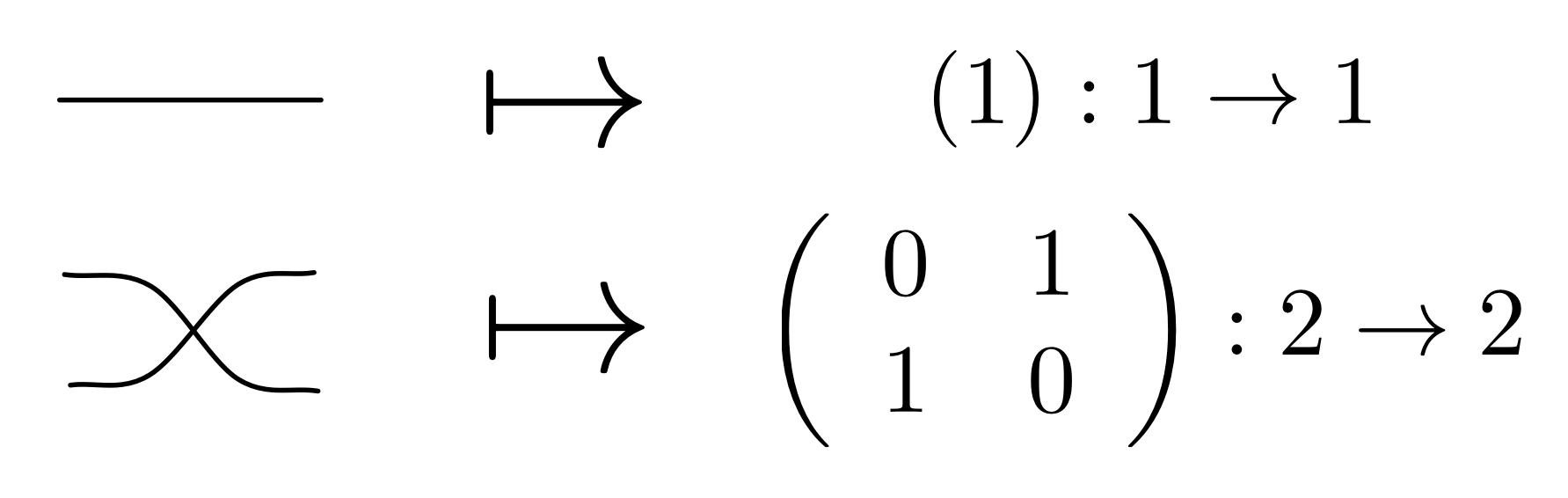
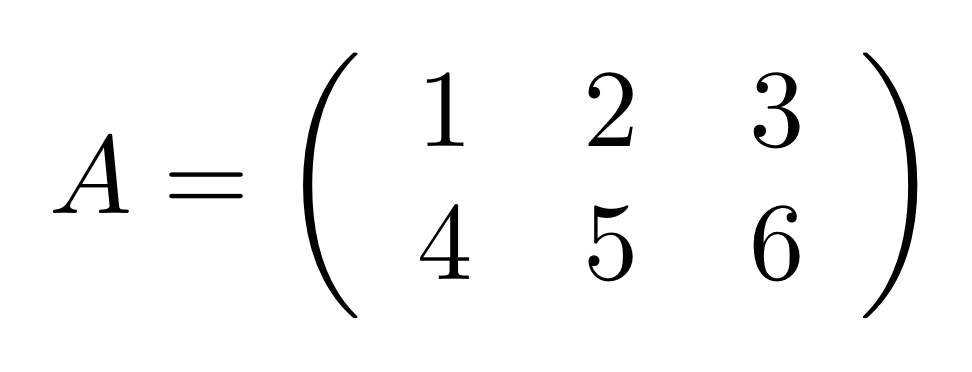

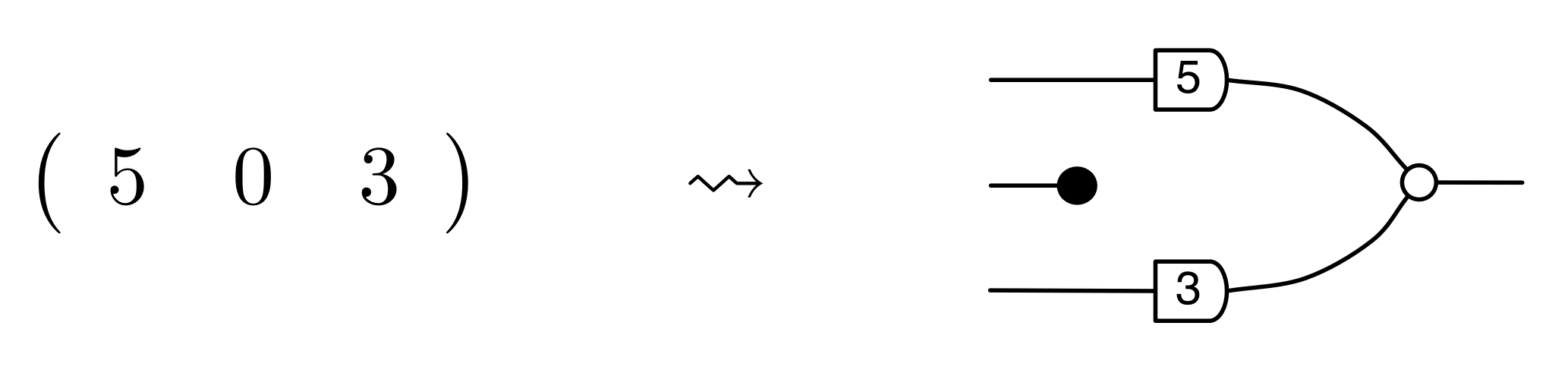

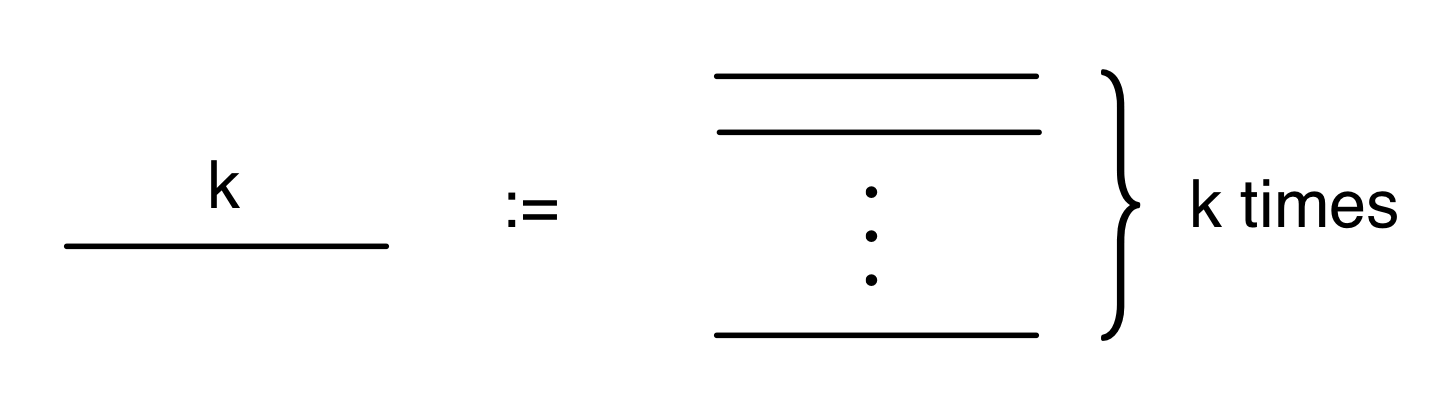



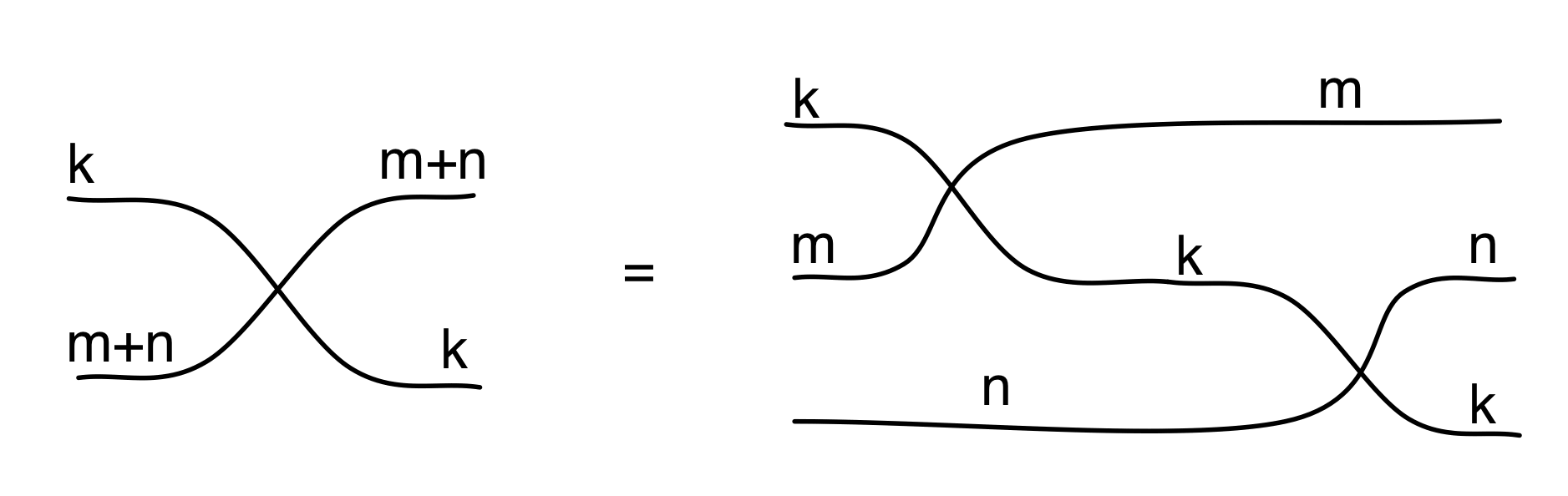

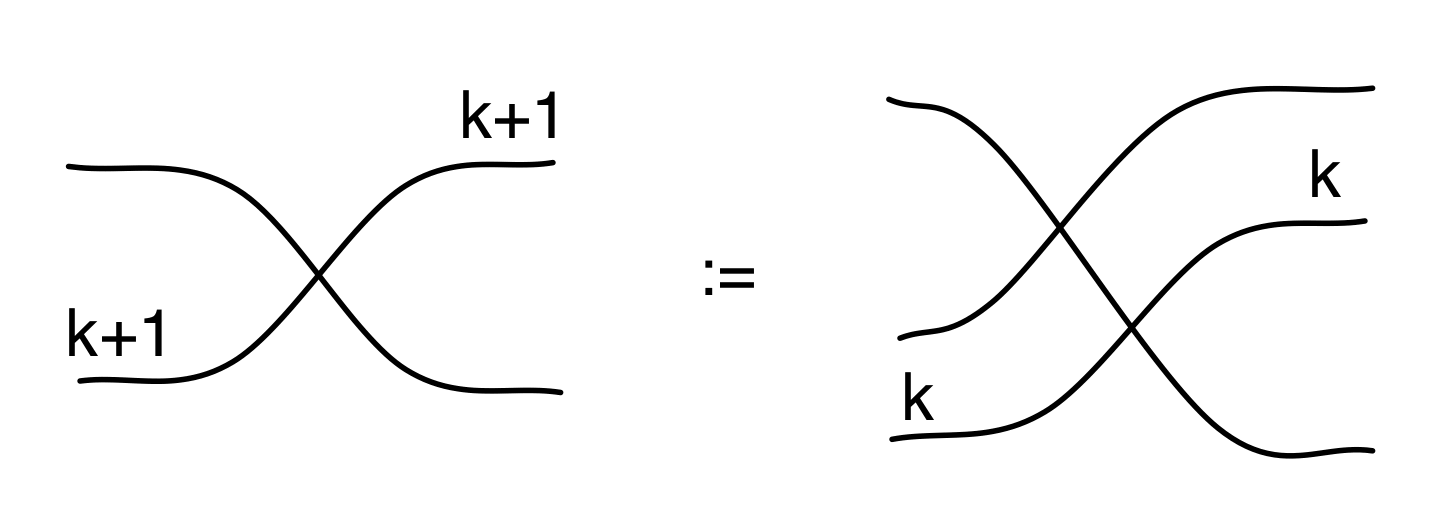


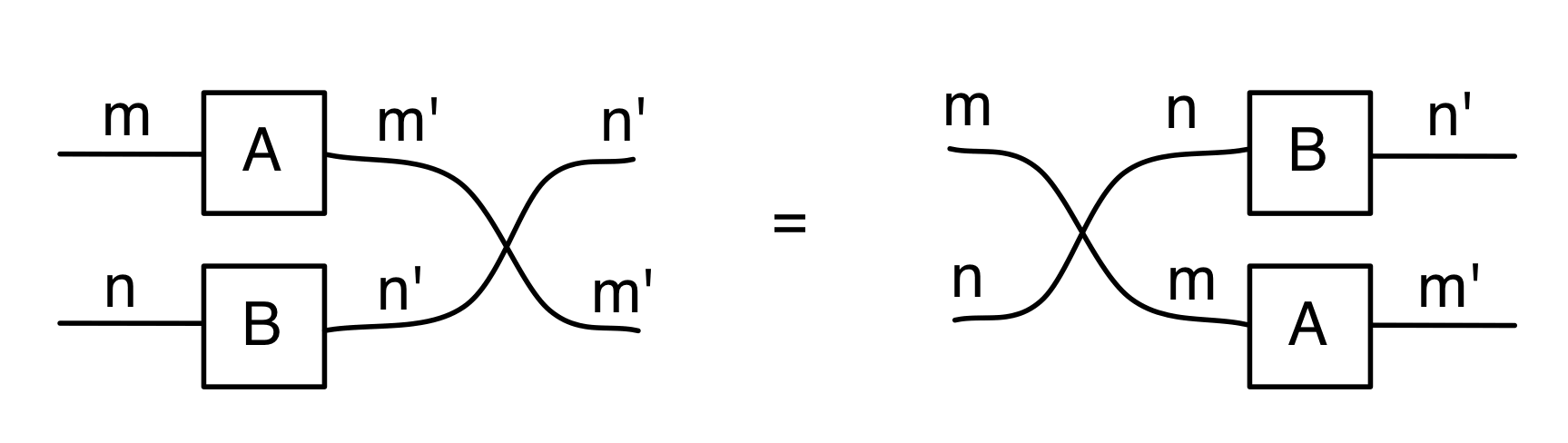

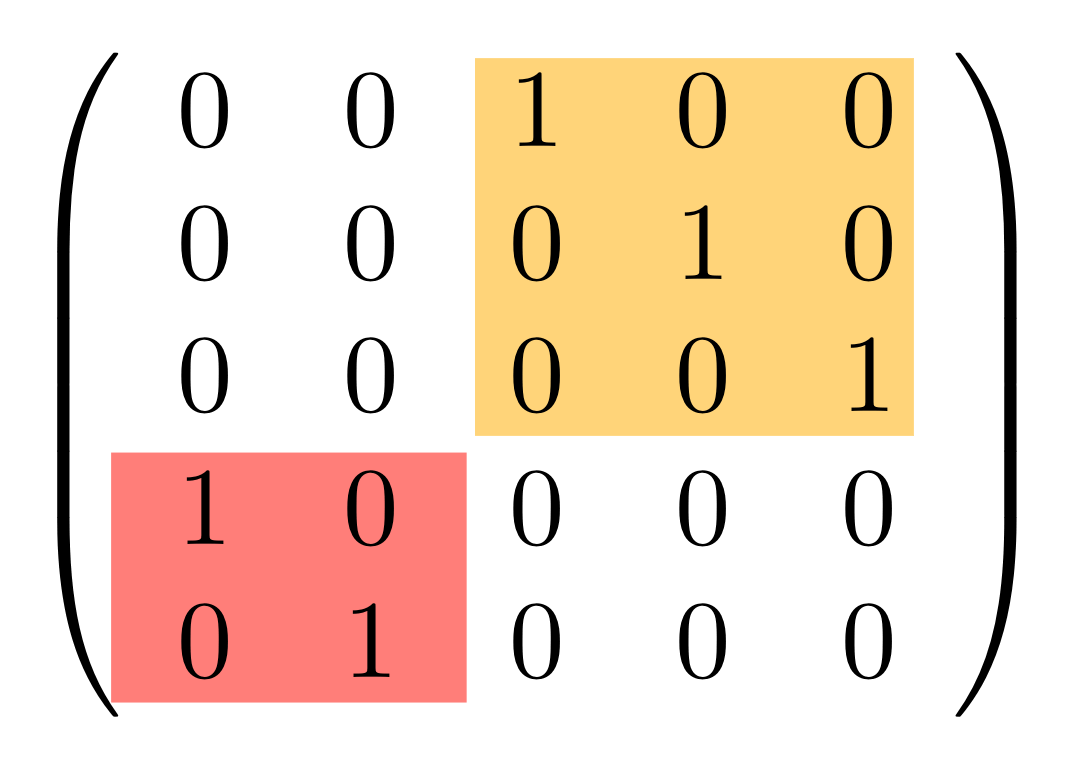




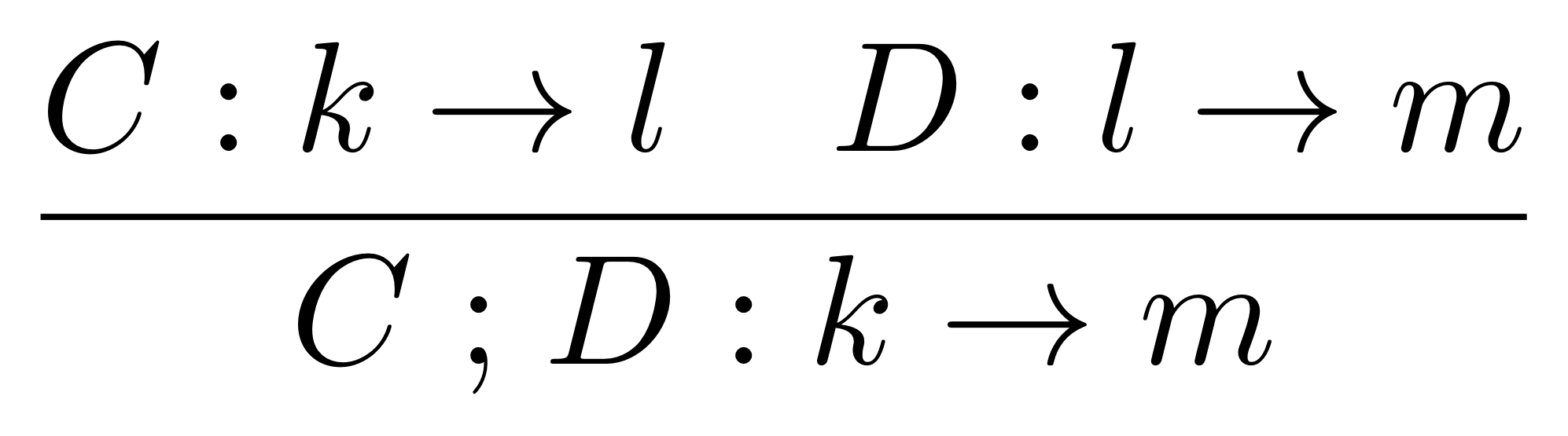
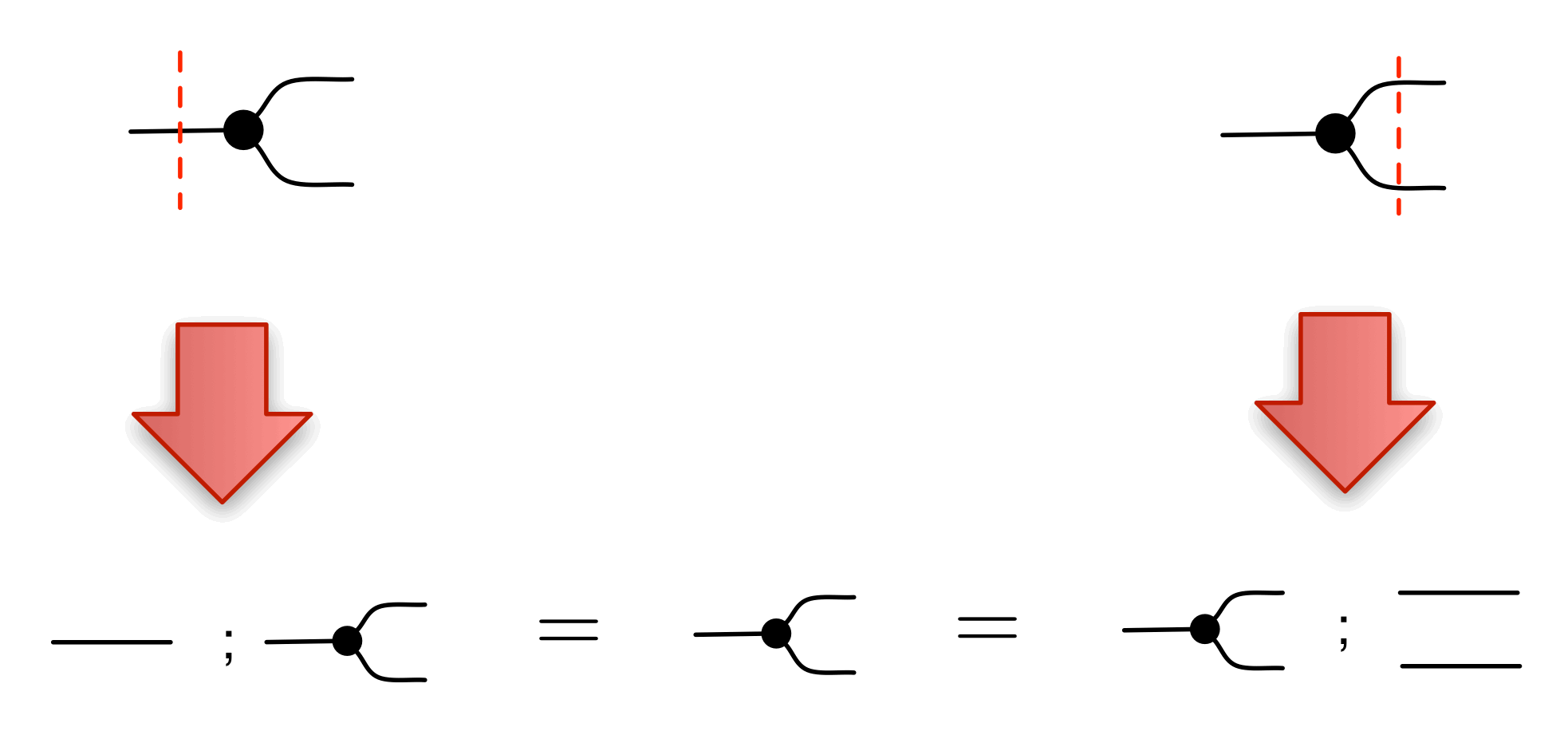



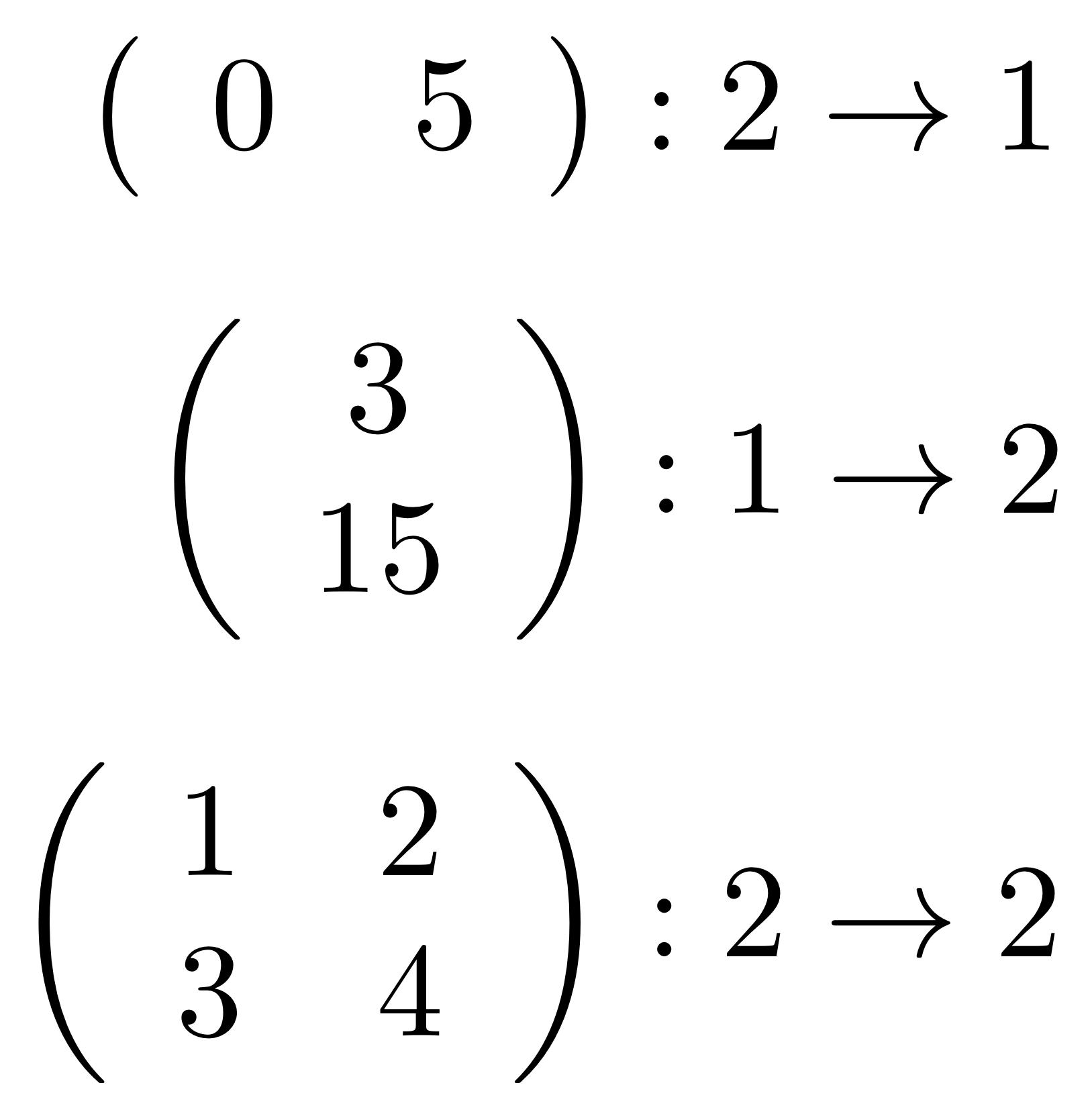
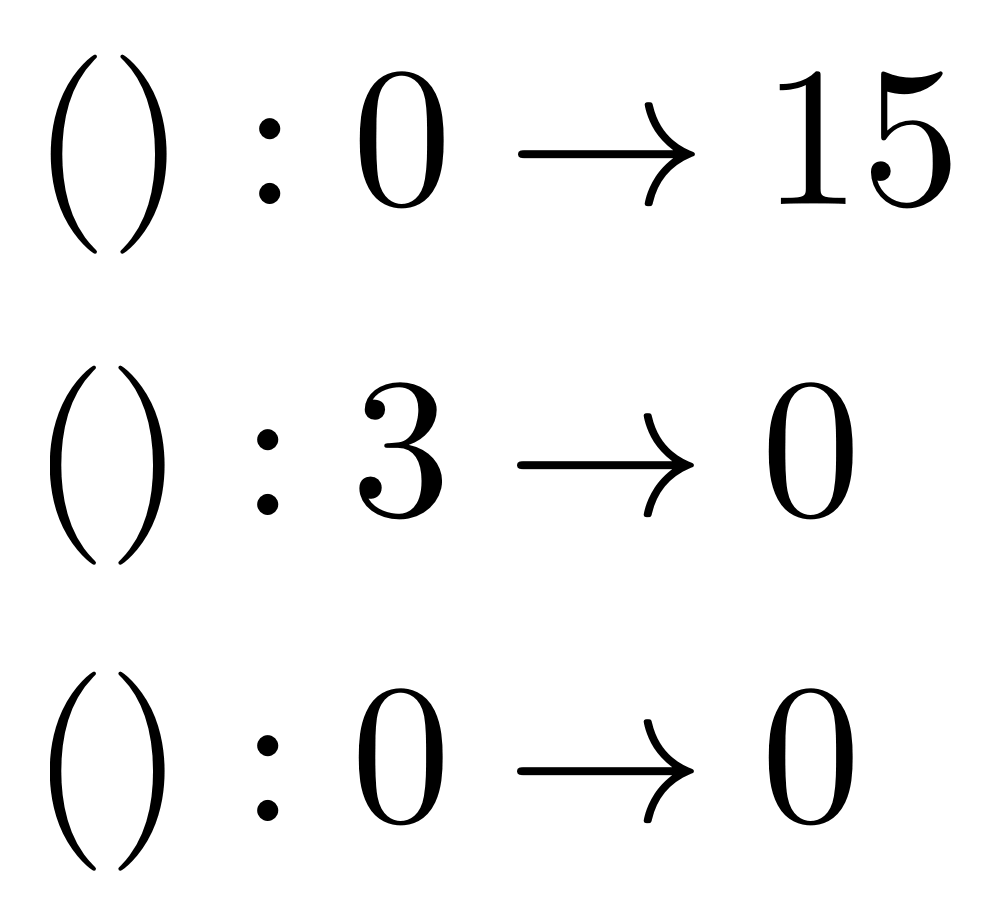
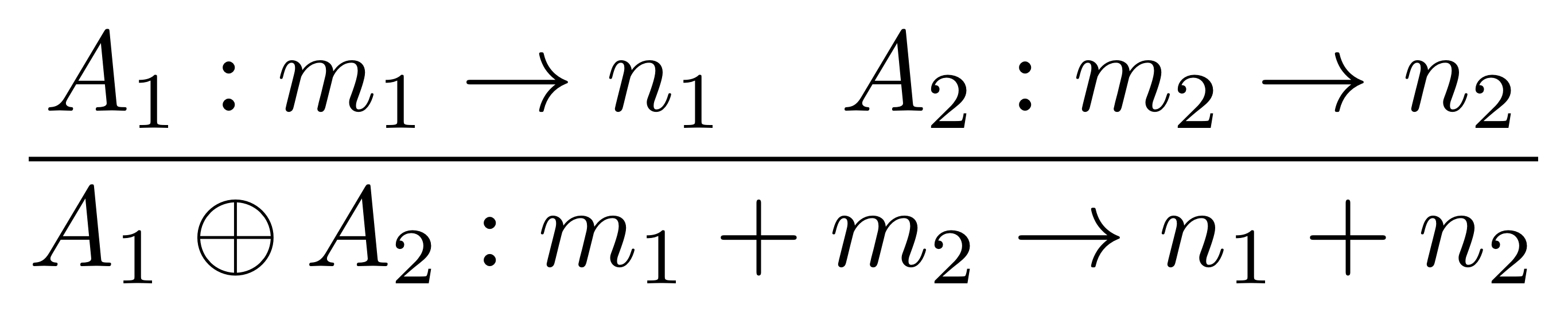

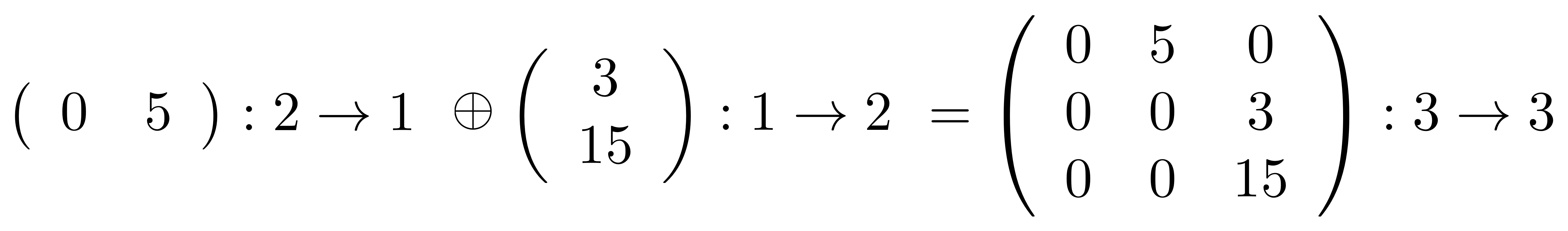
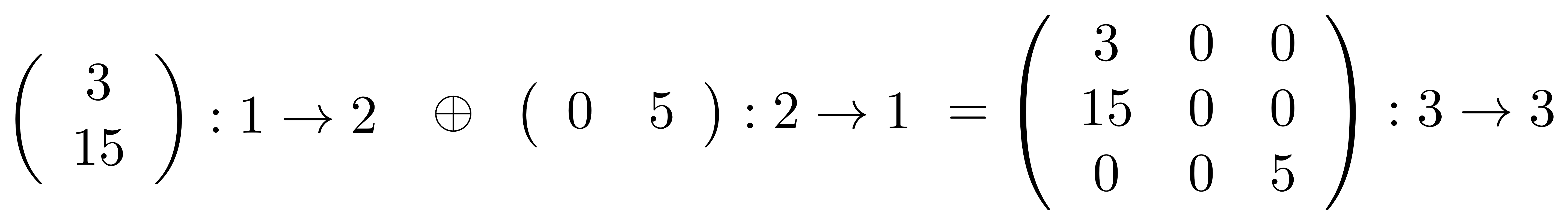
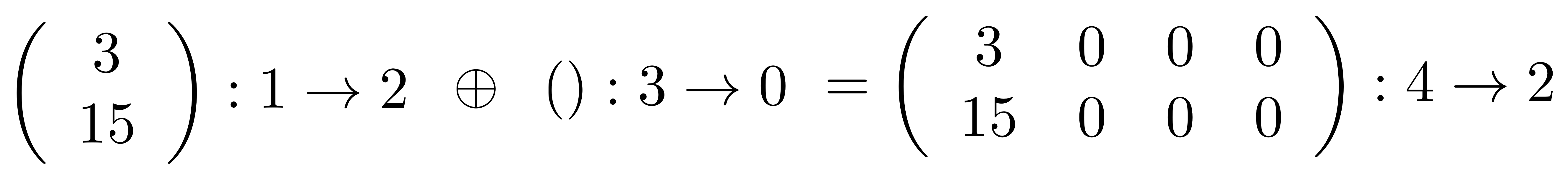
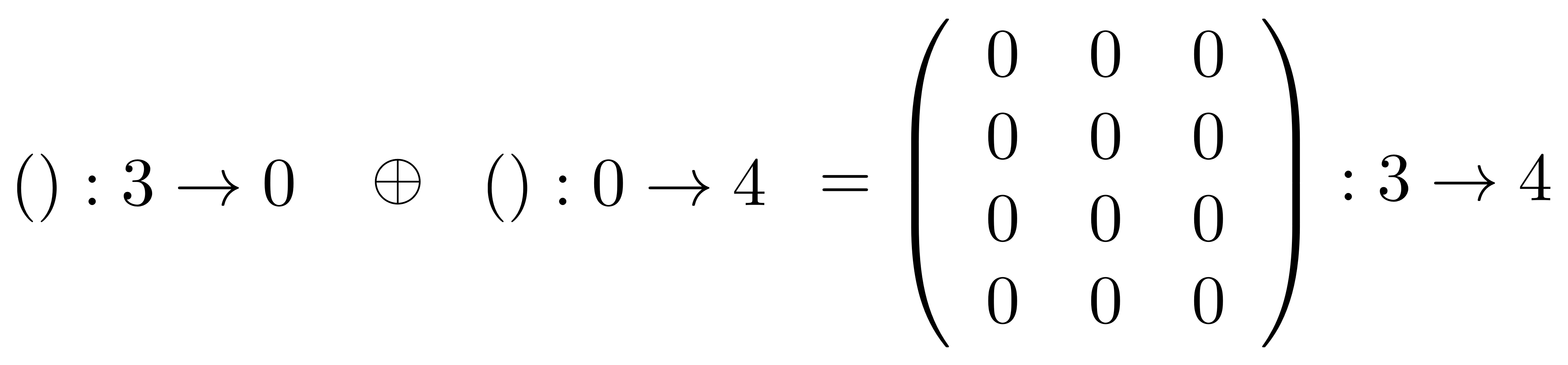
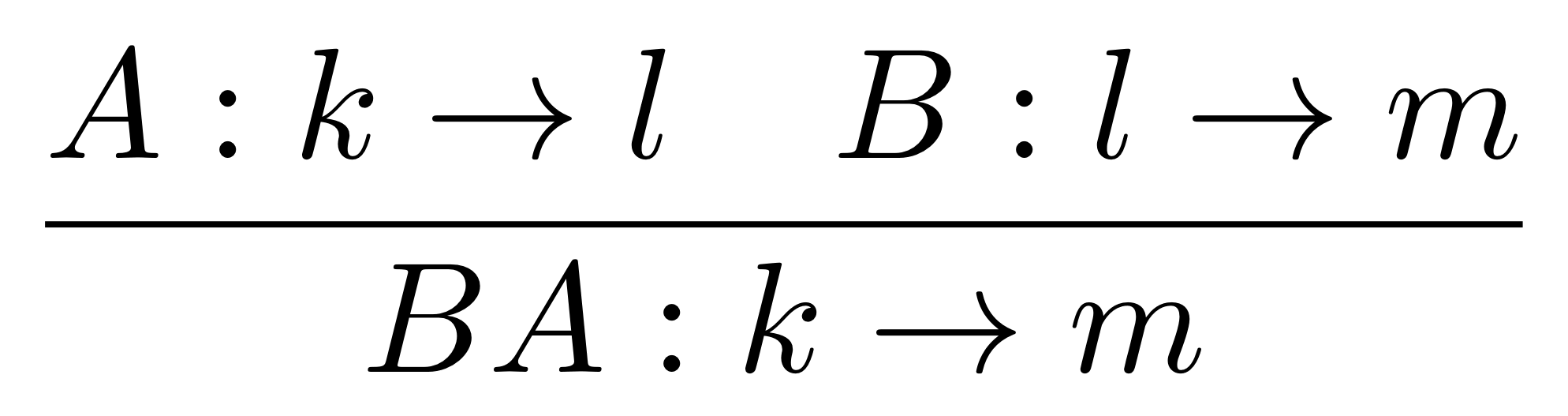
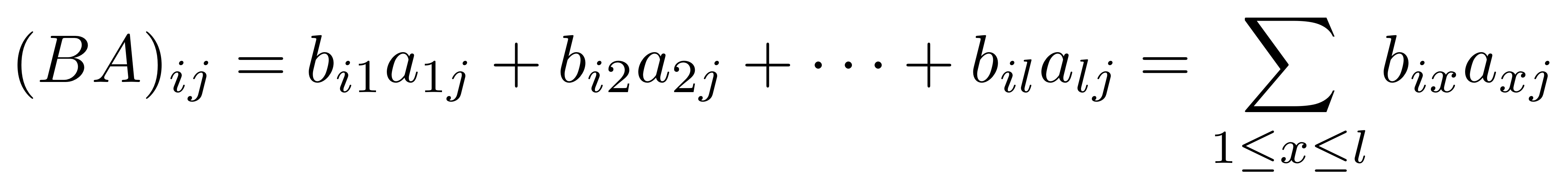
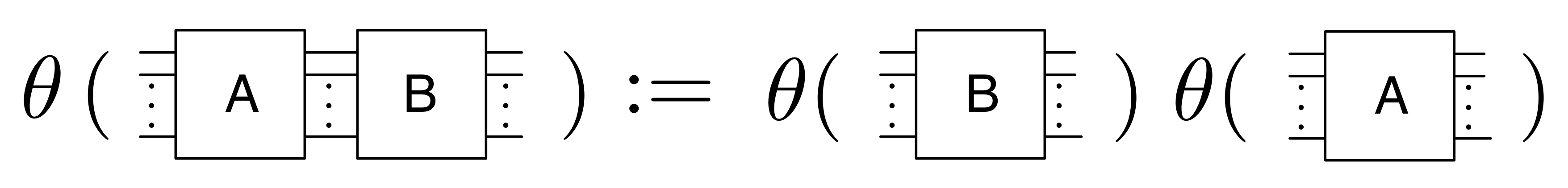
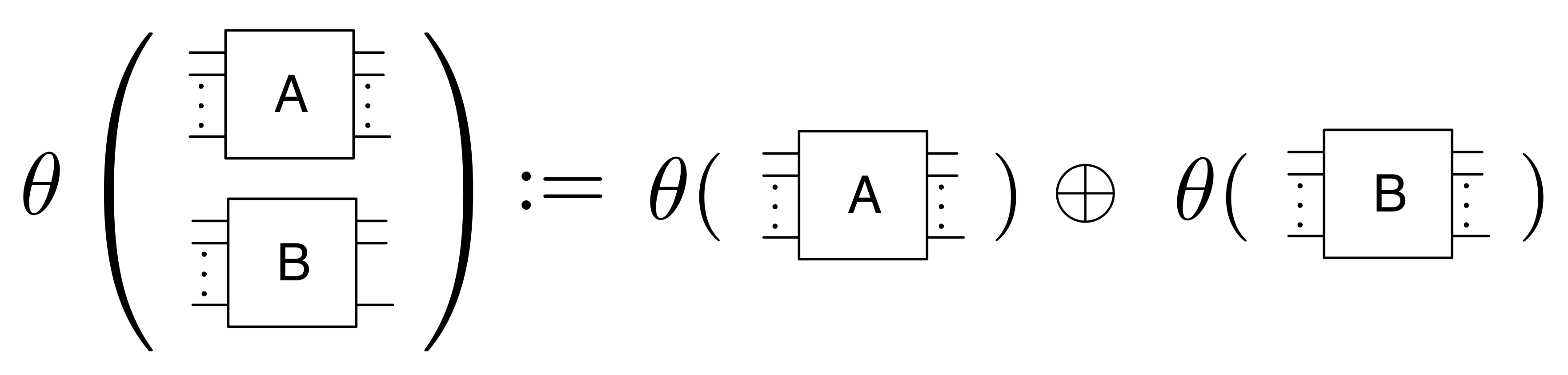

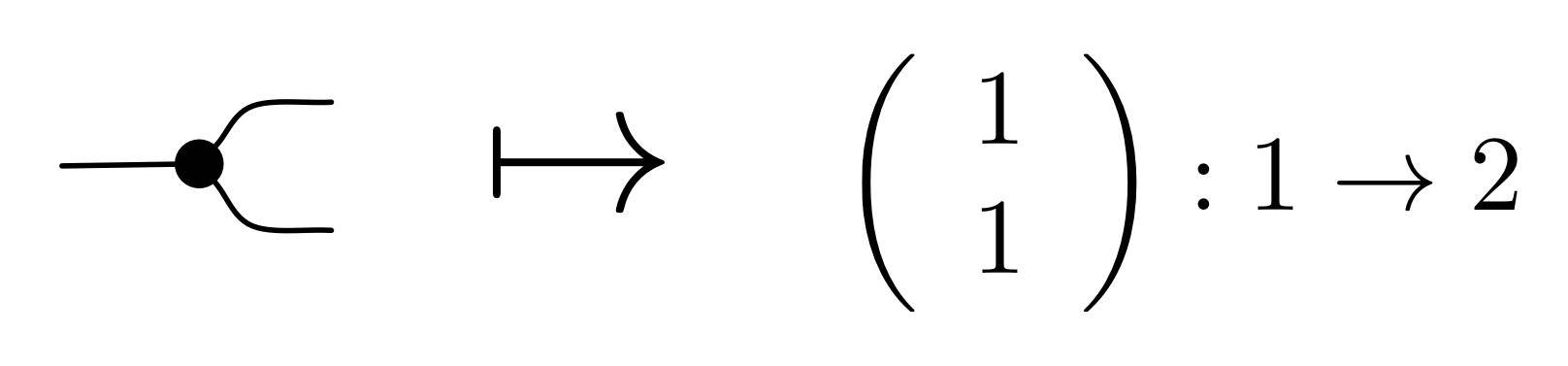
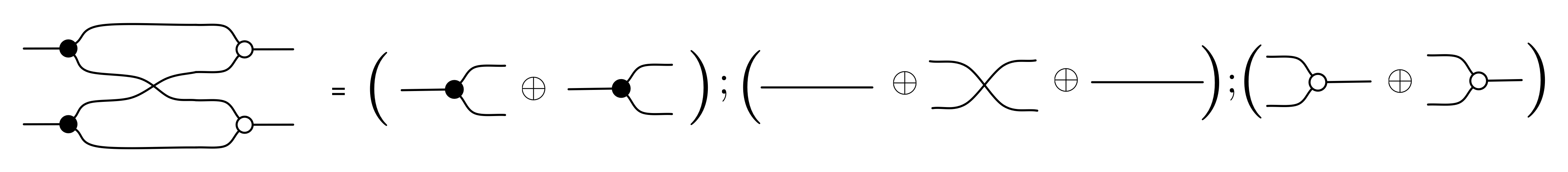
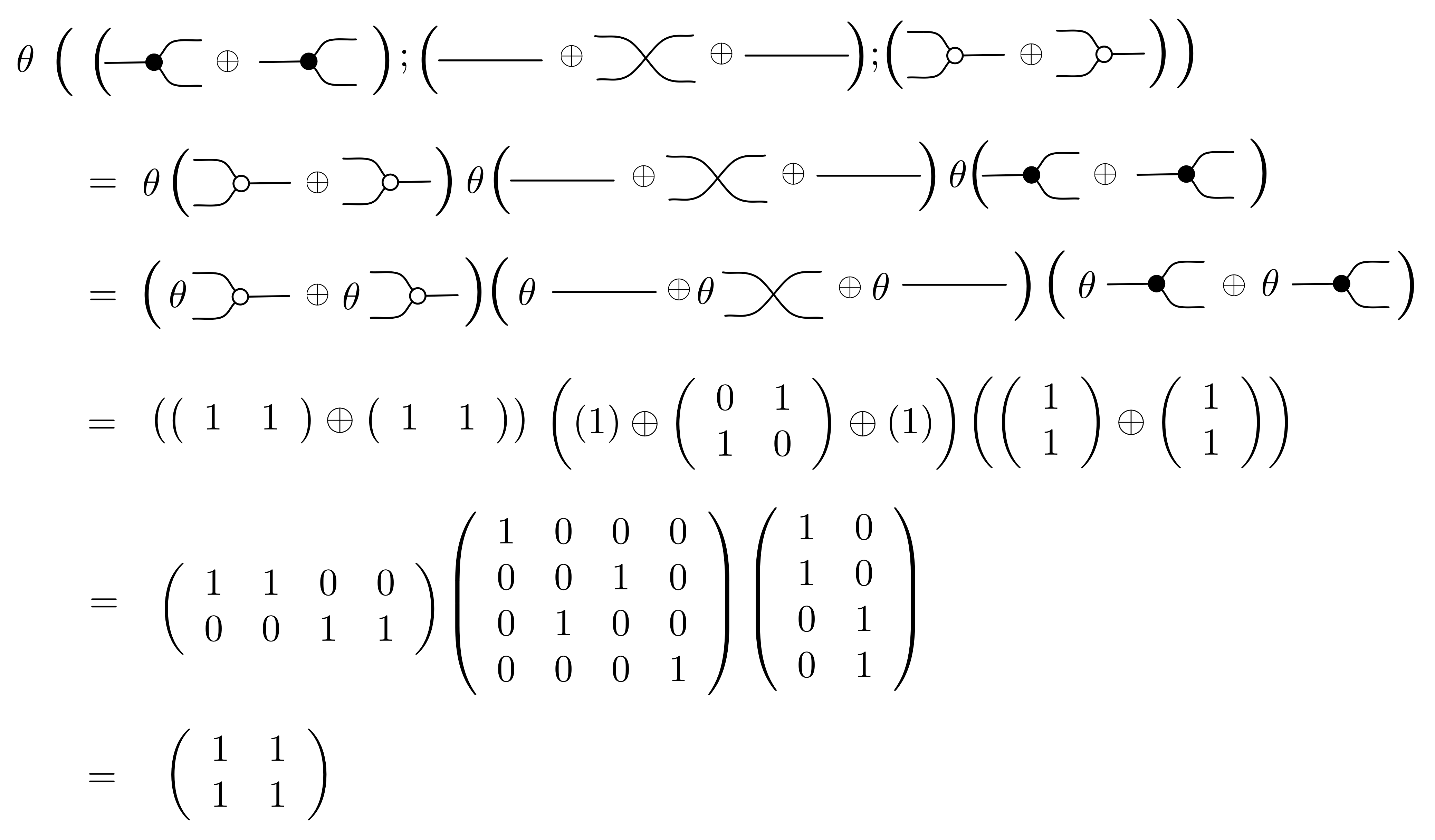
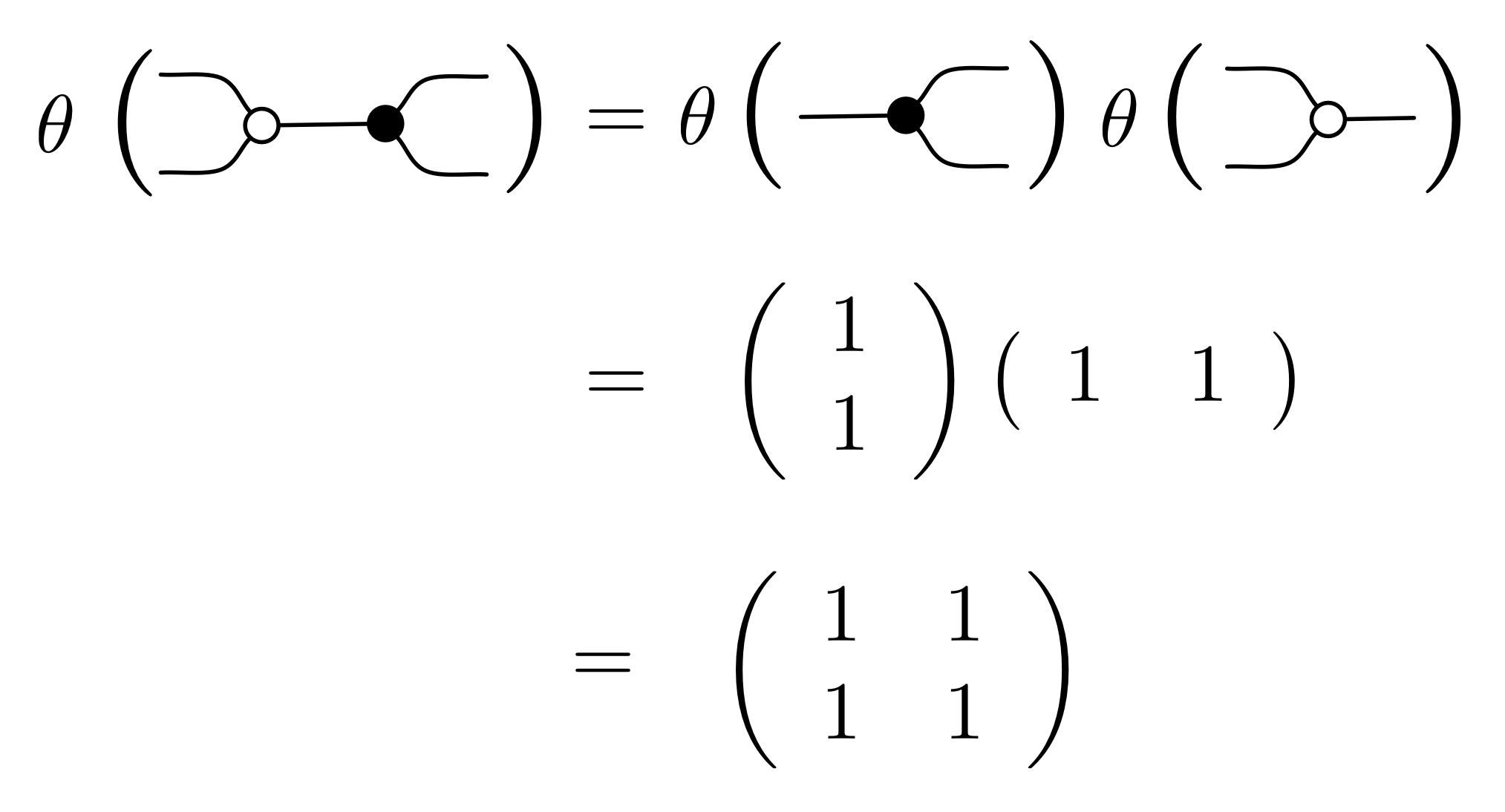












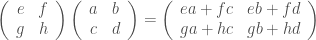 ①
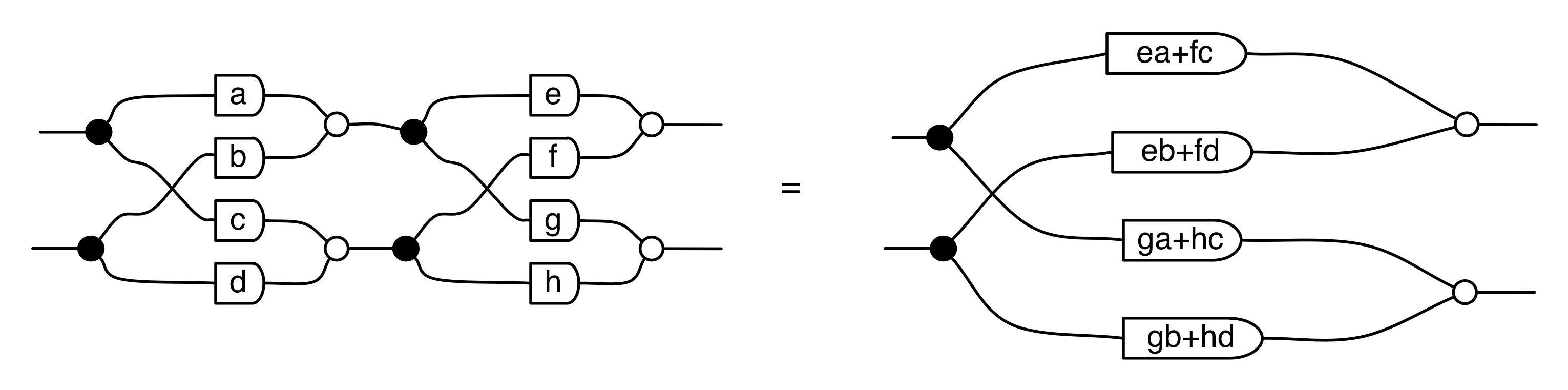
① . In general, the number of columns of the corresponding matrix is the number of dangling wires on the left, and the number of rows is the number of dangling wires on the right. Moreover, the entry at row
. In general, the number of columns of the corresponding matrix is the number of dangling wires on the left, and the number of rows is the number of dangling wires on the right. Moreover, the entry at row 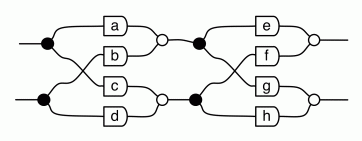

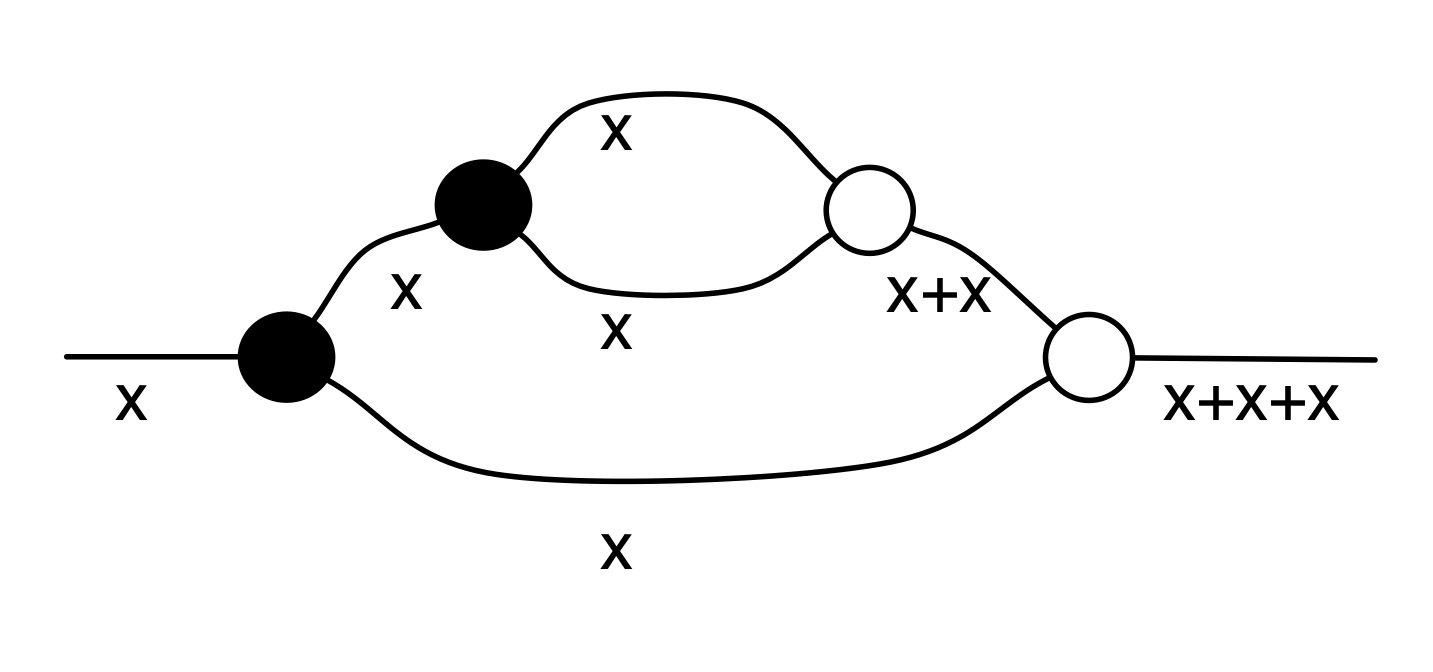




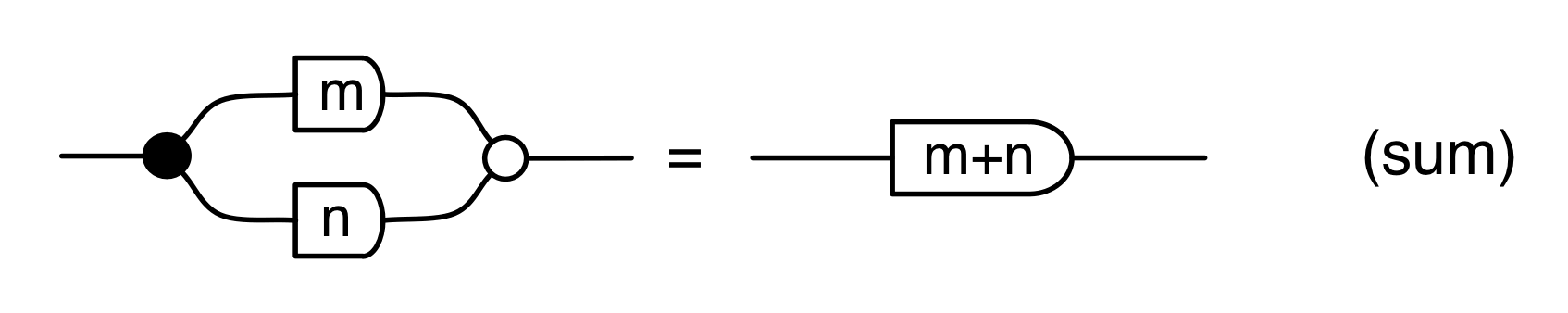






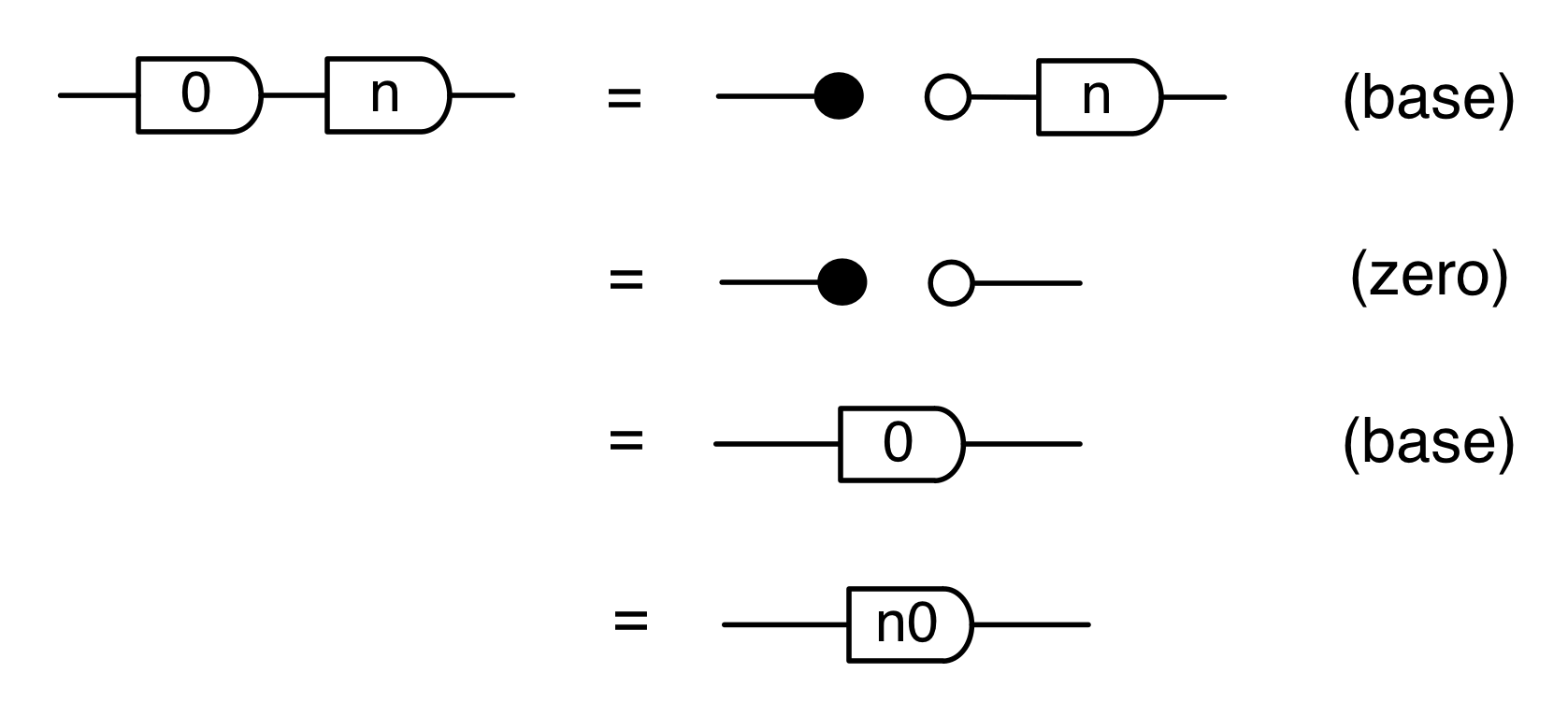

{kind=link}
{kind=link}
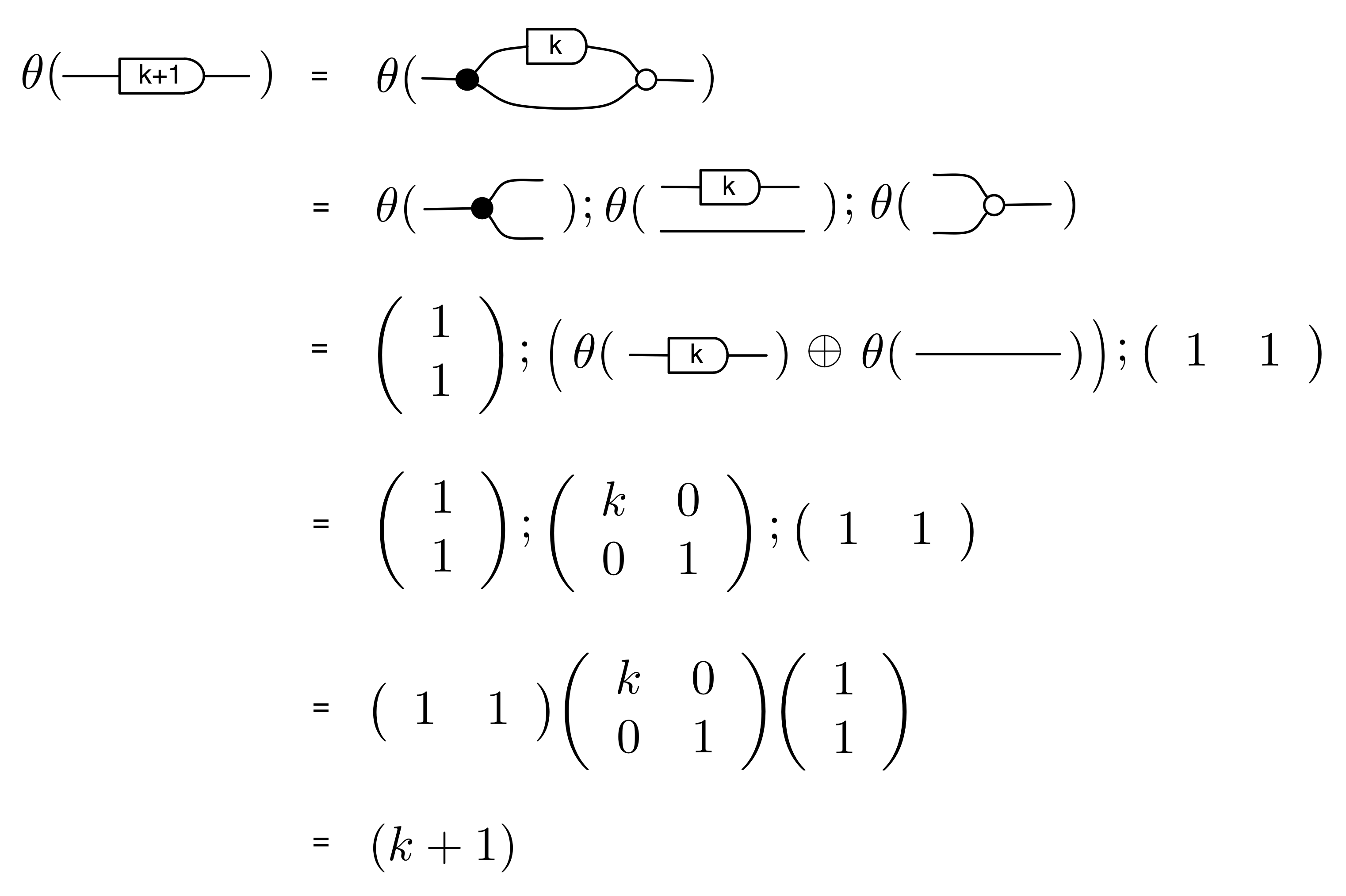{kind=link}
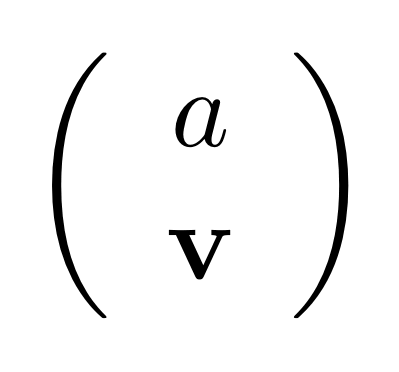{kind=link}
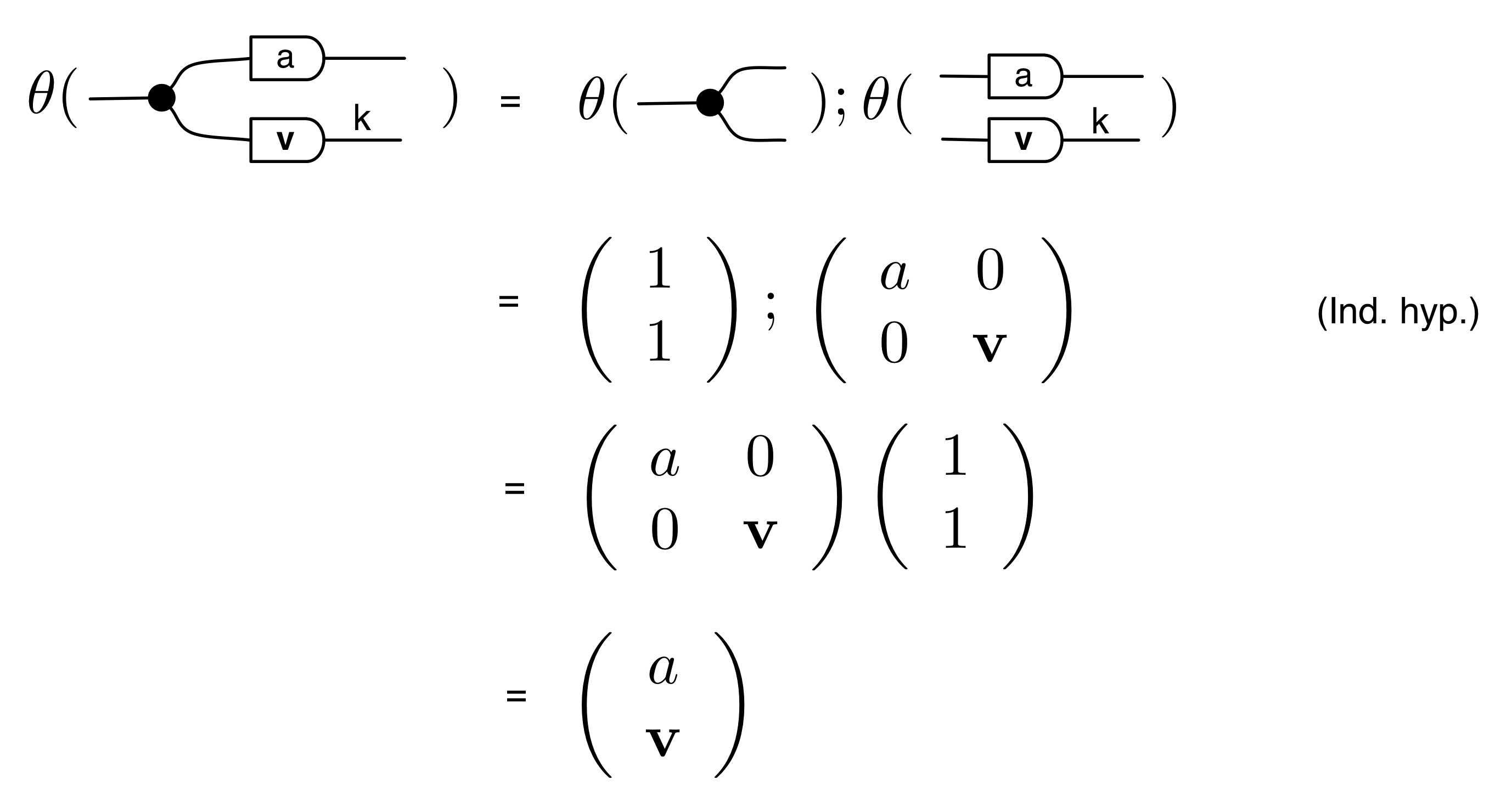{kind=link}